







Federated Meta-Learning with Fast Convergence and Efficient Communication.(Fed-Meta)
1.动机:
元学习算法:对于new tasks快速适应和有良好的泛化能力,适合联邦设置(去中心化的训练数据是Non-iid和高度个性化的
key:共享参数化算法(或元学习器),而不是以前的方法中的全局模型
【举例】在图像分类任务中,n个类别的图像可能会被不均匀的分布在客户端,每个客户端拥有的类别数为k(k《=n)
在联邦学习中,会训练一个large n-way 分类器来利用所有客户端的数据,而一个k-way的分类器对于一个客户端就足够;
在元学习中,算法可以训练包含不同类别的任务
综上,在联邦元学习中,可以使用元学习来训练一个k-way分类器进行初始化,以此降低通信成本。
(note:
(1)元学习:让机器拥有学习的能力,元学习广泛应用于小样本学习中,在元学习中,训练样本中的训练集称为support set,训练样本中的测试集叫做query set。在机器学习中,只有一个大样本数据集,将这一个大数据集分成了两部分,称为train set和test set;
但是在元学习中,不止一个数据集,有多少个不同的任务,就有多少个数据集,然后每个数据集又分成两部分,分别称为support set和query set。
(2)元学习的损失通过N个任务的测试损失相加得到。MAML所要优化的损失是在任务训练之后的测试loss,而pre-training是直接在原有基础上求损失没有经过训练)
2.提出的算法:federated meta-learning framework
在元学习中:参数化方法(parameterized algorithm)或说meta-learner是通过meta-training过程从大量任务中慢慢学习的,在each task中快速训练一个特定的模型。一个任务通常由互不关联的support set和query set组成。在support set上训练特定任务模型,然后在query set上测试,测试结果用于新算法。
在联邦元学习中:算法在server上进行维护,并(将算法)分发到clients端进行模型训练。在元学习的每一个episode中,一批sampled clients接受算法参数并进行模型训练,然后将query set上的测试结果上传到server端进行算法更新(见Figure 1)。
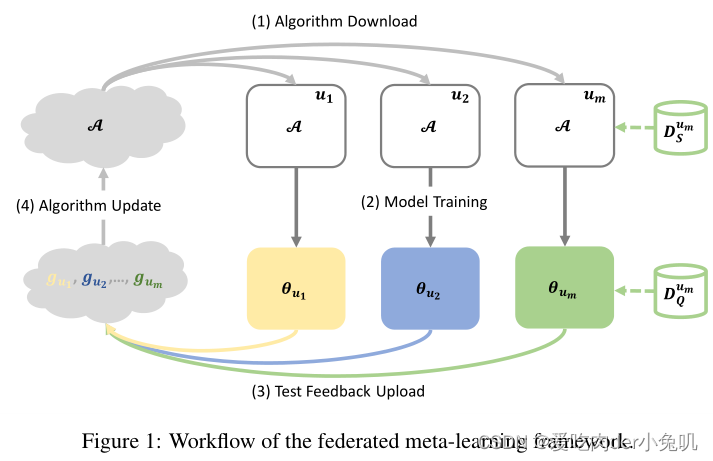
本文提出的联邦元学习框架将每个客户端视作一个task,目标不是训练一个包含所有任务的global model,而是训练一个初始化良好,能够快速适应新任务的模型。
2.1文字介绍
1)将元学习融入联邦学习框架,目标:利用分布在clients的数据,协同地对算法进行元训练。
2)机制:
将元学习融入联邦学习框架,目标:利用分布在clients的数据,协同地对算法进行元训练。
传输的信息:
① 模型初始化参数(model parameter initialization from server to clients)
② test loss (from clients to server)③ 在Meta-SGD中,学习率 α \alpha α也进行传递(for inner loop model training)
2.2 流程
 这是关于联邦元学习的算法流程:
这是关于联邦元学习的算法流程:
1)服务器端更新:
抽样客户端,为选中的客户端分发初始化的模型参数,在每一个客户端进行各自的模型更新,更新完成之后进行测试损失的平均
(MAML与Meta-SGD的区别只在于后者多出一个学习率参数;)
2)客户端更新
先在训练集Support上学习,模型参数更新为
s
e
i
t
a
seita
seita,然后据在测试集Qurray上进行测试,得到测试损失L,然后返回给服务器。
3.比较联邦元学习和联邦学习
1)联邦学习在server和clients间传输的是全局模型,联邦元学习传输的是算法
2)联邦元学习中的共享算法可以比联邦学习中的共享模型更灵活。
我的理解:利用来自于各个用户的测试损失来对服务器端的模型初始化进行微调,以此来找到一个好的初始化信息。
与直观的FedAvg不同,FedAvg(Meta)使用测试客户机的支持集在测试之前对从服务器接收到的模型初始化进行微调,这体现了元学习的本质——“学习微调”。

















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









