






目录
时间自注意力 (Temporal Self-Attention,TSA)

引言
基于点云的目标检测(编码):Pointpillars: Fast encoders for object detection from point clouds(2019 CVPR)
基于点云的BEV语义分割:Bev-seg: Bird's eye view semantic segmentation using geometry and semantic point cloud(2020 arXiv)
单目摄像头:单独处理不同的视图,不能跨摄像机捕捉信息,导致性能和效率较低;
多目摄像头:从多摄像头中提取整体表征(鸟瞰图(应用于多目摄像头情景) - 一种常用的周围场景表示方式)。
作者目标:设计一种不依赖深度信息的 BEV 生成方法,可以自适应学习 BEV 特征,而不是严格依赖 3D 先验。
BEVFormer 内容
BEV 是连接时间和空间的理想桥梁
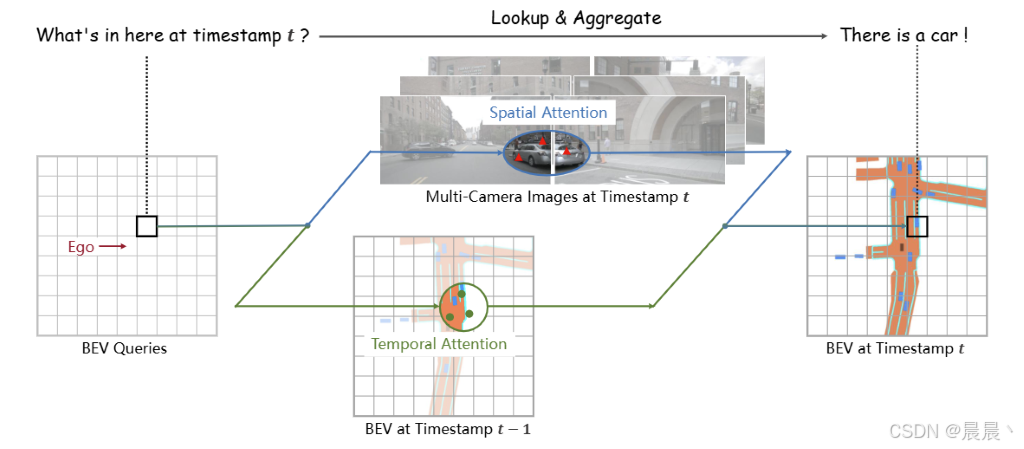
BEVFormer 关键步骤
BEVFormer 包含三个关键设计:
1、融合空间和时间特征的网格状 BEV 注意力查询;
2、空间交叉注意力模块 -> 聚合多摄像头图像的空间特征;
3、时间自注意力模块 -> 从历史 BEV 特征中提取时间信息。
相关参考内容
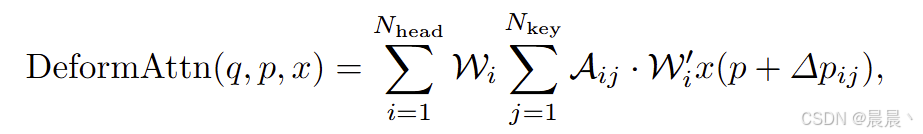
作者注意力模块基础:将 2D 的可变形注意力扩展到 3D 感知任务。参考:Deformable convolutional networks(2017 CVPR)、Deformable detr: Deformable transformers for end-to-end object detection(2021 arXiv)
Deformable convolutional networks:在二维空间上引入一种可学习的、动态的注意力/采样机制 - 2D可变形注意力。
传统卷积的局限性:在每个位置的操作总是固定的、规则的网格做加权求和:
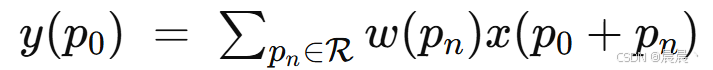
R 表示采样网格;w 表示核权重。在真实场景中,物体的几何形态(角度、大小、扭曲)是各不相同的,固定网格的感受野不够灵活。Deformable convolutional networks 在每个采样点上加一个可学习的偏移量,使网络能够动态“关注”最有意义的像素位置。
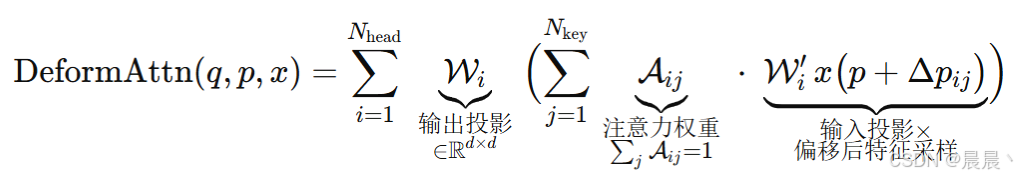

BEVFormer 整体流程

相关参考内容
Inverse Perspective Mapping(IPM 逆透视映射)(2D -> BEV 的一种简单方法):
1、A sim2real deep learning approach for the transformation of images from multiple vehicle-mounted cameras to a semantically segmented image in bird's eye view(2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC))
2、Structured bird's-eye-view traffic scene understanding from onboard images(2021 CVPR)
前人对 BEV 时间信息的研究:叠加多个时间戳的 BEV 特征来考虑时间信息。
1、Fiery: Future instance prediction in bird's-eye view from surround monocular cameras(2021 CVPR)
2、Translating images into maps(2022 International Conference on Robotics and Automation (ICRA))
3、Understanding bird's-eye view of road semantics using an onboard camera(2022 IEEE Robotics and Automation Letters)
堆叠 BEV 特征来考虑时间信息的弊端:限制了可用的时间信息量(可以理解为降低了时间分辨率);带来了额外的计算成本;
作者的解决办法:通过 RNN 的方式,从之间的 BEV 特征中获取时间特征。
BEVFormer 整体框架
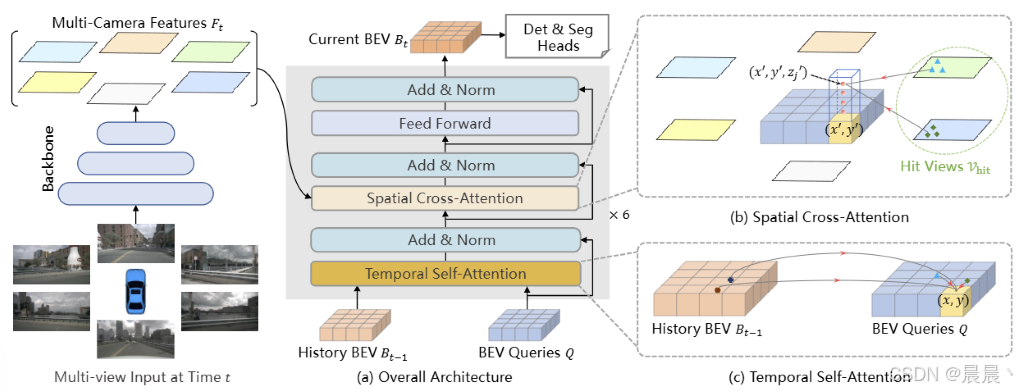
除了 BEV 查询、空间交叉注意力、时间自注意力三层定制设计外,其余各层都遵循 Transformer 结构。
流程
首先,通过时间自注意力机制,利用 BEV 查询 Q 从先前的 BEV 特征 Bt-1 中查询时间信息;
接着,通过空间交叉注意力机制,利用 BEV 查询 Q 从多摄像头特征 Ft 中查询空间信息;
最后,通过前馈神经网络得到当前时间点 t 统一的 BEV 特征。
BEV 特征 Bt 将作为后续检测头的输入,用以实现目标检测、语义分割、三维边界框等任务。
BEV 核心:BEV查询

空间交叉注意力
作者基于 Deformable detr: Deformable transformers for end-to-end object detection(2021 arXiv)设计空间交叉注意力(原论文是针对 2D 场景,为此作者对其进行适当改进 -> 将 BEV 平面上的查询提升为圆柱状查询 Pointpillars: Fast encoders for object detection from point clouds(2019 CVPR),从柱状查询中采样 Nref 3D 参考点,然后将这些点投影到2D视图中。)
多摄像头情况下单帧图像像素数量巨大,若采用多头注意力对每个 BEV查询 做像素级全局注意力,导致内存难以接受。->借鉴 Deformable detr 做稀疏采样,在查询的感兴趣区域内抽取少量关键点,再做注意力聚合。
参考点的获得:
首先,计算查询 Qp 在BEV平面上的索引 p=(x, y),并计算得到对应真实世界中的坐标。
高度维的扩展由预先定义的一组锚点来决定,例如在 [-3, 3]m 的范围内均匀取 Nref 层用来存储不同高度处的信息。
通过该方法,在每个查询 Qp 处即可得到一组参考点。
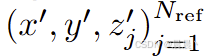
查找参考点在摄像头的位置
首先,通过相机的内外参矩阵将每个 Qp 映射回相机 2D 坐标。
然后,判断视野。即计算得到的位置位于某个像素内,当前像素将被标记为 HitView,否则忽视该视角。
过程总结如下:

i 表示相机视角的索引,j 表示参考点的索引,Nref 表示每个 BEV 查询总的参考点,Fit 表示第 i 个相机视角的特征。
时间自注意力 (Temporal Self-Attention,TSA)
引入时间自注意力,是为了解决:1、目的运动状态估计(静止图像没有时间线索);2、被遮挡的较高目标 - 遮挡恢复(前帧可见的物体可能在当前帧被遮挡);3、减少内存开销,对长时依赖更有效(简单堆叠多帧 BEV 特征可能导致内存开销,TSA 可通过单步将注意力汇聚一帧)。
之前简单叠加 BEV 特征:
-
Fiery: Future instance prediction in bird's-eye view from surround monocular cameras(2021 CVPR)
-
Translating Images into Maps(2022 International Conference on Robotics and Automation (ICRA), Philadelphia)
-
Understanding Bird’s-Eye View of Road Semantics Using an Onboard Camera(2022 IEEE Robotics and Automation Letters)
时间自注意力模型:
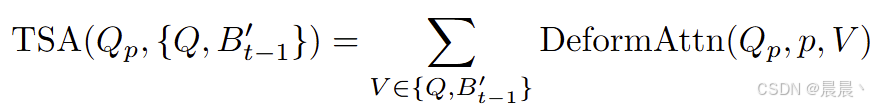
具体步骤:
首先,通过上一时刻的 BEV 特征Bt-1∈RH×W×C 通过车辆的 IMU/GPS 等传感器,计算 t-1 到 t 时刻的平移量 ΔX,ΔY 与旋转 Δθ,得到对齐后的历史特征 B't-1 。
然后,构建注意力的 {Key,Value} 集合。具体来说 Qp 即为 BEV 查询在 p=(x, y) 处的取值(与空间交叉注意力相同)-> {Qp, B't-1}。特别的,对于第一个样本的每一个序列,采用 {Qp, Qp}。
BEVFormer 模型训练
多帧随机抽样
对于当前时间 t 的训练样本,作者拟通过之前的三帧数据提取历史 BEV 信息。三帧的选择并非固定使用前三帧,而是从过去的 2s 内随机选取 3 帧,记作 t'∈{t-3, t-2, t-1}。(目的:增加不同速度、采样间隔下的多样性,帮助模型更好适应真实车辆运动过程中的抖动和采样不均)
递归生成 BEV 特征 / 梯度截断
对于 {t-3, t-2, t-1, t} 四帧数据,前三帧只做前向传播,不保留梯度(即递归生成 BEV 特征)。对于第一帧数据 {t-3} ,由于没有先前 BEV 特征,因此时间自注意力机制退化为自注意力机制。在当前时刻 {t} ,模型同时基于多摄像头数据和先前的 BEV 特征 Bt-1 生成 BEV 特征 Bt(此时使用梯度下降来优化参数)-> 此时 Bt 包含了跨越四个样本的时间、空间信息。
优点:既可以使得 Bt 保留充足的历史信息,同时又可以避免反向传播导致的内存和计算爆炸。
检测/分割
将生成的 BEV 特征 Bt 作为后续目标检测、分割模块的输入,并计算相应的损失函数。
BEVFormer 模型推理
按时间顺序评估视频序列的每一帧,将前一时间帧的BEV特征用于下一时刻。
作者的实验配置
learning rate:2×10-4(始终保持不变);epochs:24;Backbone:ResNet‑101‑DCN(通过 FCOS3D 初始化)或 VoVNet‑99(通过 DD3D 初始化)。作者默认使用 FPN(Feature pyramid networks for object detection 2017 CVPR)输出的多尺度特征。
BEV 网格:200×200;分辨率:0.512 m。高度特征分为 4 层 Nref 。每个 2D 平面的参考点,作者选取 4 个其周围的点作为当前的查询 Qp (每个点会存在一定的偏移)。
总结
1. 针对的问题
-
多摄像头视角下生成 BEV 表示存在深度依赖与误差累积
以往基于深度估计(Lift‑Splat 等)的方法,对预测深度十分敏感,稍有偏差即严重影响最终 BEV 特征质量。 -
缺乏对时序信息的高效融合
单帧 BEV 只能反映静态场景,无法准确估计物体速度,也难以补偿遮挡导致的视野缺失。
2. 提出的方法:BEVFormer
-
Grid‑Shaped BEV Queries
在 BEV 平面预设 H×WH\times WH×W 个可学习查询,每个查询对应物理空间中一个小网格; -
Spatial Cross‑Attention
对每个 BEV 查询,在“柱状”3D 参考点(多高度锚点)上投影到各摄像头特征图,仅在命中视野的局部区域做 Deformable Attention 采样,从而脱离深度预测依赖; -
Temporal Self‑Attention
将对齐后的上一帧 BEV 特征与当前 BEV Queries 拼接,通过可变形注意力聚合历史帧信息,实现在线的时序融合; -
统一多任务 Head
最终生成的 BEV 特征既送入 Deformable DETR 风格的 3D 检测头,又可接 Panoptic SegFormer 风格的分割头,实现检测与地图分割一体化。
3. 实现效果
-
nuScenes 测试集上达 56.9% NDS,比先前最佳摄像头方法 DETR3D 高出 9.0 个百分点,同时在平均速度误差(mAVE)上也大幅缩小与激光雷达基线的差距。
-
实时性能可调:默认 6 层 encoder 推理约 130 ms,可降至 7 ms(1 层、低分辨率)以支持更严格的延迟需求。
-
多任务融合:同一 BEV 表征下完成 3D 检测与 BEV 语义分割,两者较单任务场景性能不降反升。
4. 现存的不足与挑战
-
与 LiDAR 方法的性能差距
虽然 BEVFormer 在纯视觉范畴内效果出色,但在精度(特别是位置和高度精确度)与激光雷达方法仍有差距。 -
绝对深度与高度估计的局限
尽管“多高度柱”减轻了对深度网络的依赖,真实世界的地形起伏与道路坡度仍会给投影精度带来误差。 -
姿态对齐误差累积
依赖 IMU/GPS 做历史 BEV 对齐,若累计运动补偿存在偏差,时序融合可能反而引入位置漂移。 -
高算力需求
多摄像头下的 Backbone 特征提取和多头可变形注意力仍需强大 GPU,向“轻量化无人车端侧”部署还有一定距离。
BEVFormer 通过“空间+时序可变形注意力”成功打破了深度依赖,实现了高效、统一的 BEV 表征学习,并在多项自动驾驶基准上刷新了纯视觉方法的最高纪录(2022)。但要全面替代 LiDAR 或实现在资源受限平台的端侧部署,仍需在深度鲁棒性、对齐精度和算力优化方面继续探索。



















 3032
3032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











