






一、视角转换基础知识:
1.2D到3D
一个非常经典的工作是LSS,通过估计深度将2D点投影到3D空间中,用分类的方法来代替回归,但是由于深度值是离散的,所以可视化BEV特征后会显得空洞,而且多视角下的同一个点要经过多次操作,所以有些低效
2.3D到2D
OFT、DETR3D、BEVFormer,这些工作都是预先定义一个3D空间中的锚点,利用相机的参数,将3D锚点投影回2D空间,那么就认为,这个2D空间上的特征就是3D空间上的特征。
在3D空间中的每一个位置都能获得2D空间的投影图像特征,因此可以产生密集的BEV特征,有些工作,如DETR3D,只选取自己感兴趣的3D空间区域,来投影回图像特征,但是这样可能会产生错误的BEV特征,因为3D空间投影回2D空间是经过一个射线,而3D空间的位置有可能本身就是错的
而且在这个过程中,BEV空间的特征点与图像空间的特征点做交互的时候,密集查询太耗算力
二、BEVFormer的做法
1.3D到2D
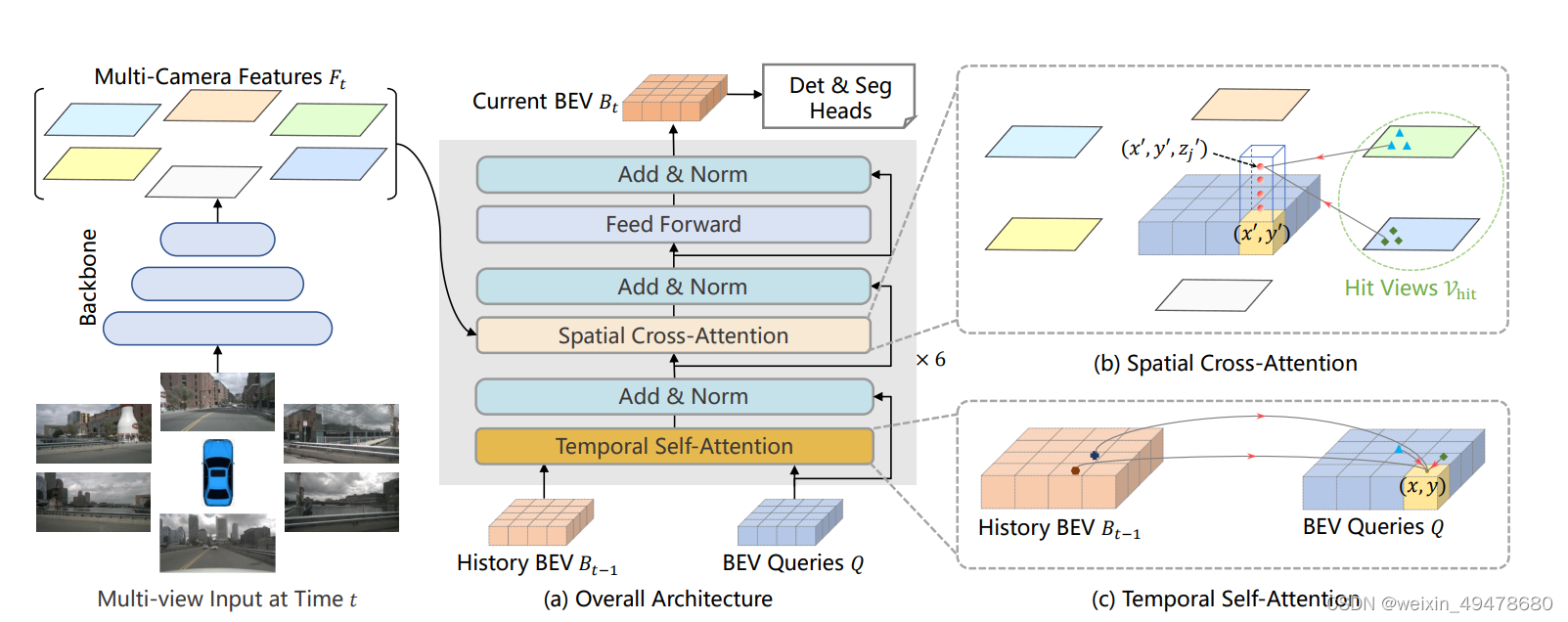
首先将BEV平面上的点BEV query拉伸成3D,(x,y,z),有四个不同高度的采样点,利用相机内外参,将3D点投影到2D空间,但是由于遮挡或者相机内外参的错误,投影有可能不准确。
考虑两个问题:如何选择所需要的特征?如何建模高度信息?
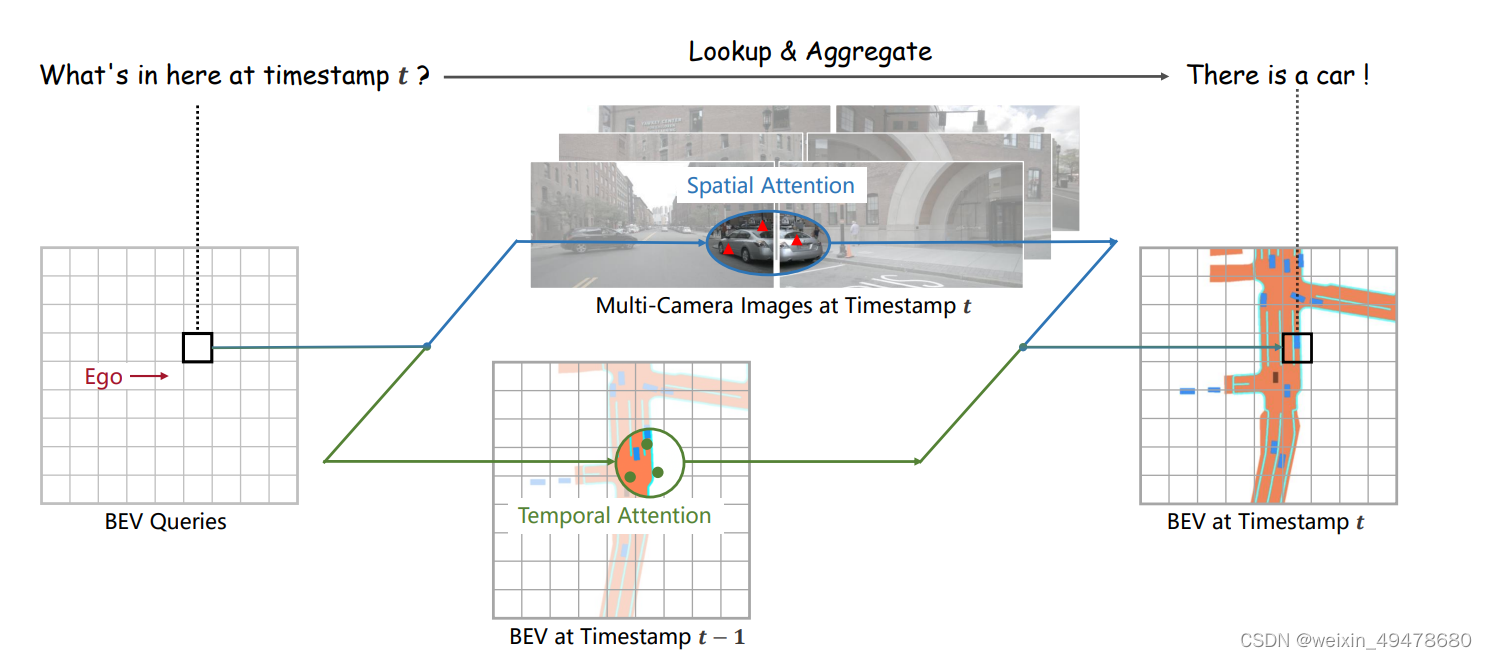
为了解决问题一,按照BEV query的索引去找对应视角下的特征,先映射到相应的视角上,再将投影点作为参考点,在参考点附近利用注意力机制进行采样,生成当前视角下需要被融合的特征。在每一个视角下去做deformable attention
BEVFormer仅仅关注可能会与图像特征交互的BEV query,而不是将BEV视角下的所有特征都与采集到的图像交互。此外,由于不同视角下对应的BEV query长度可能不同,在这项工作中,通过padding对应相同长度的BEV query,只和一部分的BEV进行交互,降低GPU
2.融合时序特征:
利用上一时刻的先验知识,在选定的点附近利用注意力机制采样,保证从历史时刻的特征中提取出真正想要的特征,同时可也利用注意力机制来调节从历史时刻中获取到的知识的权重。通过将前一时刻的BEV特征和BEV query做时间自注意力,可以利用历史信息,有效关注真正想要的特征区域。
有了历史特征参考之后,对当前应该生成什么样的BEV query有一定的指导作用
3.BEVFormer在下游任务的应用:
BEV特征可能看作是伪2D特征,2D中的任务都可以用到这里,用相同的模型进行分割和检测,两个任务尽可能对齐
BEV特征可以看成是2D特征,DETR系列貌似是检测器
检测头:原来是2D图像经过backbone之后获得图像特征,BEV上是多视角图像经过BEV encoder之后获得BEV特征,并将其看做是2D特征
分割头:分割允许不同类别的分割头重叠,基于query 的解决方案,每一个类别对应一个query,query经过mask decoder 只负责检测这个类别对应的mask

















 1475
1475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









