







一、faiss接收的数据接口

add_docunments接收的documents是一个document对象的列表。
Document 对象的列表(List of Documents),是 LangChain 中的一种数据结构。每个 Document 对象包含两个主要属性:
-
metadata:文档的元数据- 这里包含
file_name(文件名) - 例如:
{'file_name': '01-通过-史国阳-硕士-算法岗.md'}
- 这里包含
-
page_content:文档的实际内容- 包含简历的具体文本内容
- 被分成了多个片段(chunks)
数据结构示例:
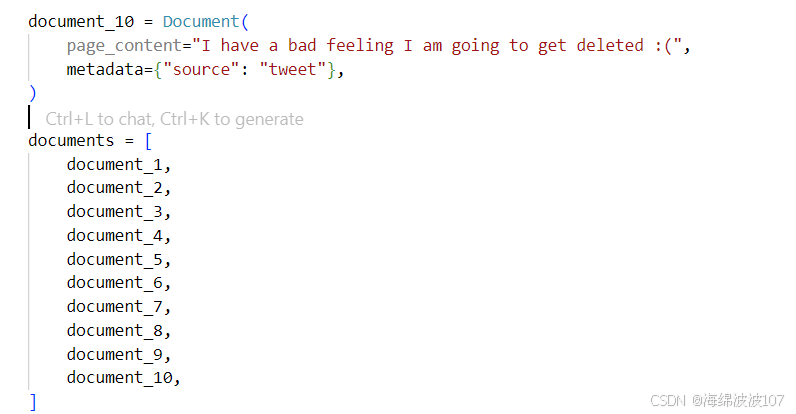
documents = [
Document(
metadata={'file_name': '01-通过-xxx-硕士-算法岗.md'},
page_content='# 基本信息\n\n**姓名:** xxx\n...'
),
Document(
metadata={'file_name': '01-通过-xxx-硕士-算法岗.md'},
page_content='- **广联达科技股份有限公司**\n...'
),
# ... 更多 Document 对象
]
这种结构通常用于:
- 文档向量化
- 文本分块处理
- 构建向量数据库
- 文档检索和问答系统
在之前的faiss学习的例子中,就是使用的这种对象列表。每一个document都有数据内容和相应的元信息,元信息可以用来存储一些标识符、属性、限制这类,以方便进行条件查询。
二、Markdown文件切分并处理为document列表
1.markdown分割器

让我解释这个 MarkdownHeaderTextSplitter 的初始化:
from langchain.text_splitter import MarkdownHeaderTextSplitter
# 定义要分割的标题级别
headers_to_split_on = [
("#", "header1"), # H1 标题
("##", "header2"), # H2 标题
("###", "header3"), # H3 标题
]
# 创建分割器实例
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on,
strip_headers=False # 保留标题在分割后的文本中
)
这个分割器的作用是:
- 根据 Markdown 标题层级分割文本
- 每个分割后的片段会包含其对应的标题信息
参数说明:
-
headers_to_split_on:定义要识别的标题级别- 每个元组包含 (标题符号, 元数据键名)
- 例如:(“#”, “header1”) 表示 H1 标题
-
strip_headers=False:True: 移除分割后文本中的标题False: 保留标题在文本中
使用示例:
text = """
# 个人简历
## 教育背景
本科毕业于北京大学
## 工作经验
### 公司A
担任软件工程师
### 公司B
担任高级工程师
"""
splits = markdown_splitter.split_text(text)
# 结果示例:
# [
# Document(
# page_content="# 个人简历",
# metadata={"header1": "个人简历"}
# ),
# Document(
# page_content="## 教育背景\n本科毕业于北京大学",
# metadata={"header1": "个人简历", "header2": "教育背景"}
# ),
# ...
# ]
这种分割方式特别适合:
- 结构化处理 Markdown 文档
- 保留文档的层级结构
- 基于标题进行文档检索
- 问答系统中的上下文管理
切分器自动将markdown处理为document列表
2.文本分割器

让我解释这个文本分割器的配置:
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=500, # 每个文本块的最大token数
chunk_overlap=50 # 相邻文本块之间的重叠token数
)
这是一个使用 tiktoken 编码器的递归文本分割器,主要参数:
-
chunk_size=500- 每个文本块的最大长度(以token为单位)
- token是GPT模型的基本处理单位
- 500 tokens 大约对应 375-425 个汉字或 150-200 个英文单词
-
chunk_overlap=50- 相邻文本块之间重叠的token数
- 用于保持上下文连贯性
- 防止句子或段落在分割时被生硬切断
使用示例:
text = """这是一个很长的文档,需要被分割成小块。
这样可以更好地处理和分析。每个块都会包含一定数量的文本。
相邻的块之间会有一些重叠,确保上下文的连续性。"""
chunks = text_splitter.split_text(text)
# 结果会是多个较小的、有重叠的文本块
这种分割方式的优点:
- 使用 tiktoken(OpenAI的分词器)确保准确的token计数
- 递归分割保证更自然的文本边界
- 重叠部分维持了上下文连贯性
- 适合后续的向量化和语义搜索
3.添加文件名
保证每个简历块都有名字,防止简历块分割之后,因为没有名字,六神无主了。因为有的时候发现简历中会带导师、博导师名字。分割之后,会认为这个博导师名字占有了这个简历内容。
三、整体流程
所以,不仅需要有该数据的接口,也要有转换为该接口的方法,两者都需要。就像两个齿轮,尺寸要契合才能一起运动。
源代码
import os
import jieba
import time
import pickle
from langchain_text_splitters import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
from langchain_community.embeddings import OpenAIEmbeddings, OllamaEmbeddings
from langchain_openai import OpenAIEmbeddings
import faiss
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_community.vectorstores import FAISS
from uuid import uuid4
from langchain_core.documents import Document
OPENAI_API_KEY='sk-xxx'
# 初始化embeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large",api_key=OPENAI_API_KEY)
# 初始化index
index = faiss.IndexFlatL2(len(embeddings.embed_query("hello world")))
# 初始化vector_store
vector_store = FAISS(
embedding_function=embeddings,
index=index,
docstore=InMemoryDocstore(),
index_to_docstore_id={},
)
# 批量读取 markdown 文件并处理
def split_text_from_mds(folder_path):
text_splits = []
for filename in os.listdir(folder_path):
if filename.endswith(".md"):
file_splits = process_markdown(filename, folder_path)
text_splits.extend(file_splits)
return text_splits
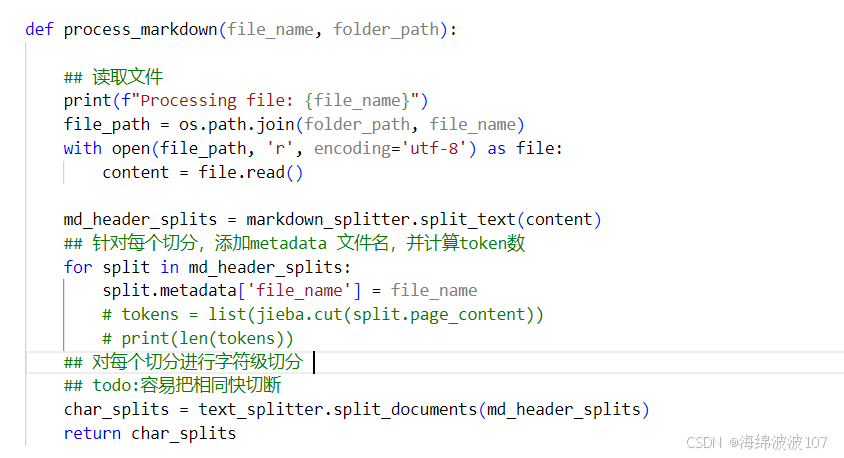
def process_markdown(file_name, folder_path):
## 读取文件
print(f"Processing file: {file_name}")
file_path = os.path.join(folder_path, file_name)
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
md_header_splits = markdown_splitter.split_text(content)
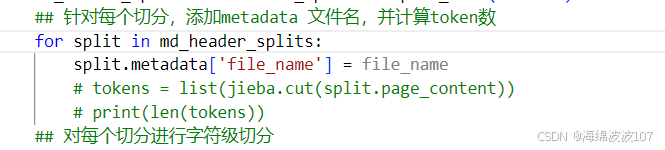
## 针对每个切分,添加metadata 文件名,并计算token数
for split in md_header_splits:
split.metadata['file_name'] = file_name
# tokens = list(jieba.cut(split.page_content))
# print(len(tokens))
## 对每个切分进行字符级切分
## todo:容易把相同快切断
char_splits = text_splitter.split_documents(md_header_splits)
return char_splits
# 切分器
## Markdown header split
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
("####", "Header 4"),
("#####", "Header 5"),
("######", "Header 6"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on, strip_headers=False)
## Char-level splits
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=500, chunk_overlap=50
)
def add_vector_store(documents, vector_store):
"""
将文档添加到已有的向量库中
Args:
documents: 文档列表,每个文档包含文本内容和元数据
vector_store: 已初始化的FAISS向量库实例
Returns:
添加文档后的FAISS向量库实例
"""
try:
# 生成文档的唯一标识符
uuids = [str(uuid4()) for _ in range(len(documents))]
# 记录开始时间
start_time = time.time()
vector_store.add_documents(documents=documents, ids=uuids)
# 计算处理时间
process_time = time.time() - start_time
print(f"向量化处理耗时: {process_time:.2f} 秒")
return vector_store
except Exception as e:
print(f"创建向量库时发生错误: {str(e)}")
raise
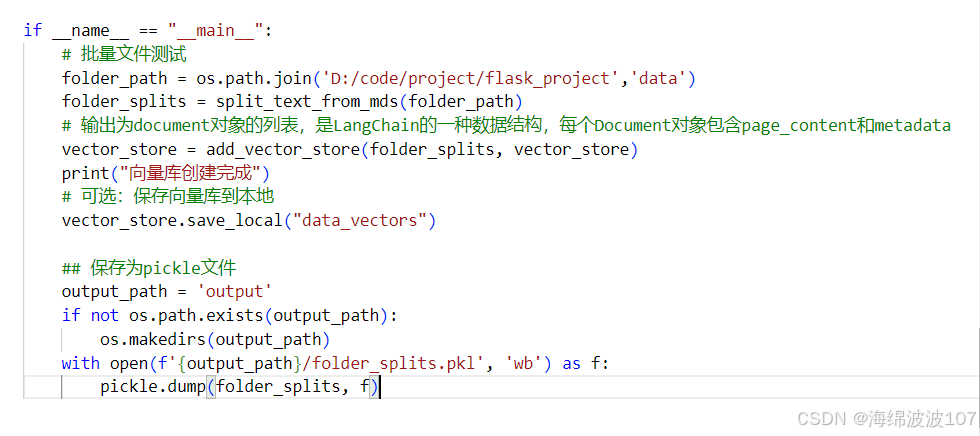
if __name__ == "__main__":
# 批量文件测试
folder_path = os.path.join('D:/code/project/flask_project','data')
folder_splits = split_text_from_mds(folder_path)
# 输出为document对象的列表,是LangChain的一种数据结构,每个Document对象包含page_content和metadata
vector_store = add_vector_store(folder_splits, vector_store)
print("向量库创建完成")
# 可选:保存向量库到本地
vector_store.save_local("data_vectors")
## 保存为pickle文件
output_path = 'output'
if not os.path.exists(output_path):
os.makedirs(output_path)
with open(f'{output_path}/folder_splits.pkl', 'wb') as f:
pickle.dump(folder_splits, f)


















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











