







来源
ViT和Transformer的关系
- Vision Transformer(简称ViT)是Transformer在CV领域的应用
- ViT只使用了Transformer的编码器部分
朴素思路
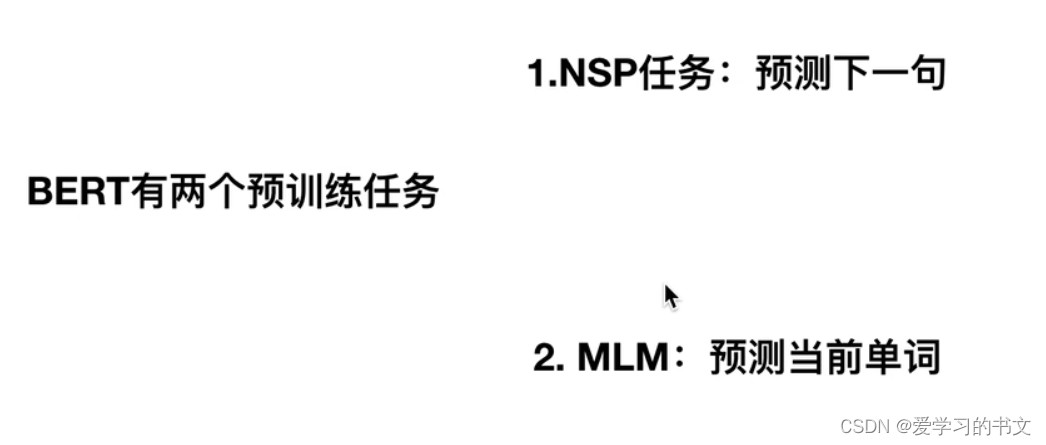
一个朴素的输入思路:把图片每个像素点作为一个token输入
tokenization指的是分词,分出来的每一个词语叫做token。
- 在NLP叫每一个单词为token
- 在CV中就是把图像切割成不重叠的patch序列(其实就是token)
CLS:标注句子语义的标注(Classification)
DASOU的猜测︰
- 如果采用一个平均,会涉及到所有tonkens的输出;
- 而MLM任务又会涉及到其中的部分mask的tokens的输出;
- (CLS出处)CSL符号一定程度在让两个任务保持一种相对的独立;
问题
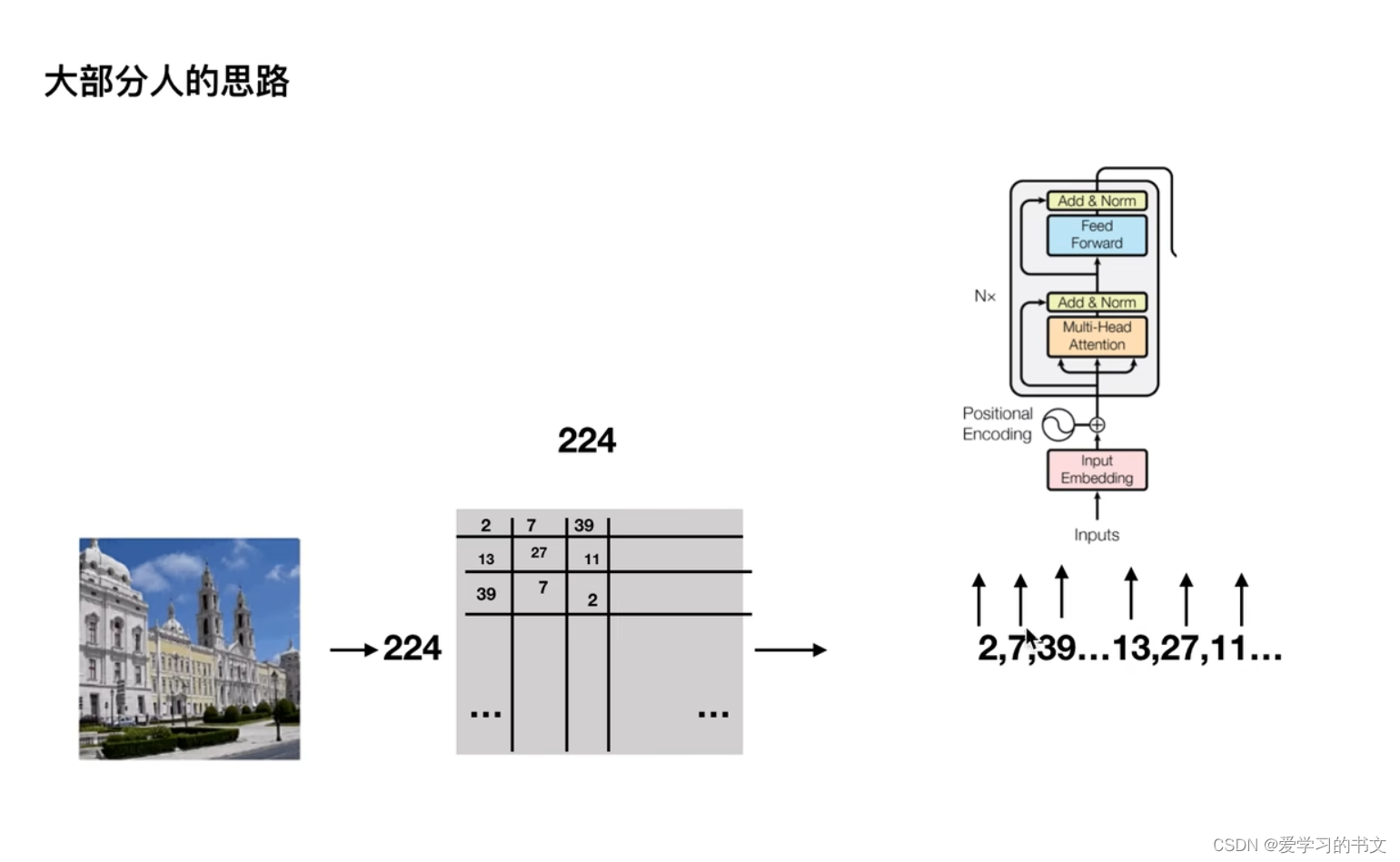
但是这样输入太大了,导致复杂度过高
ViT思路
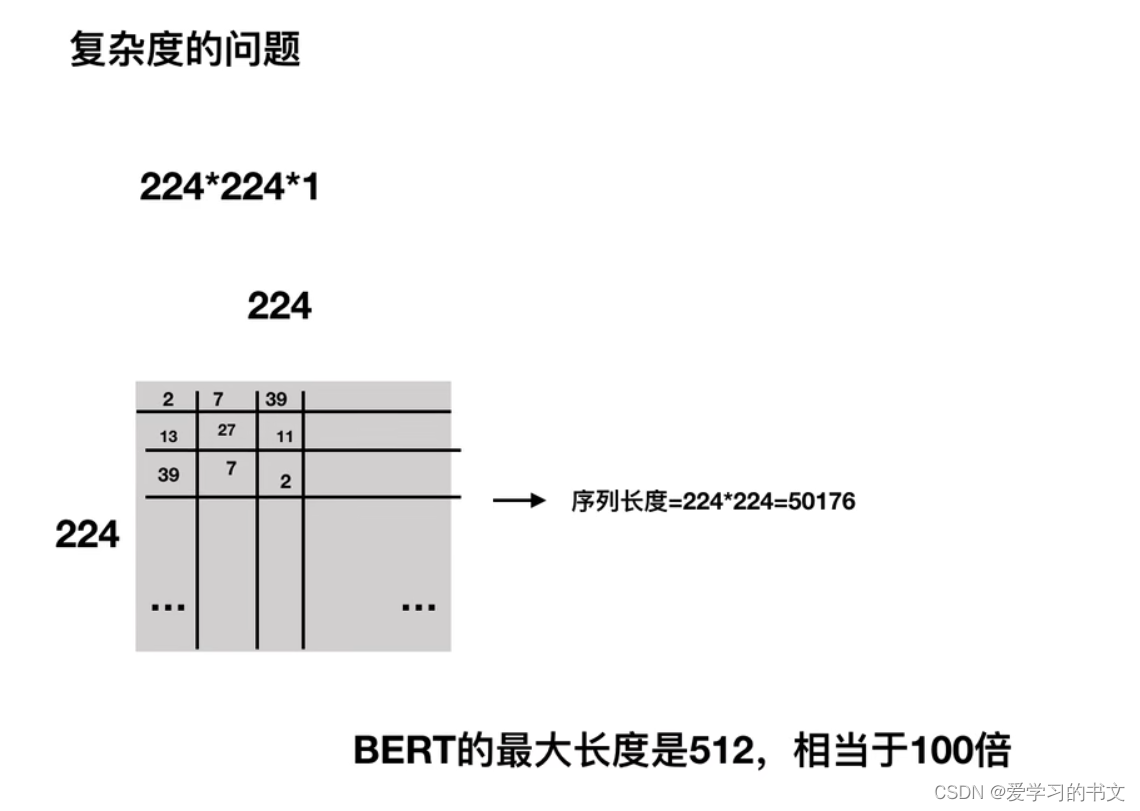
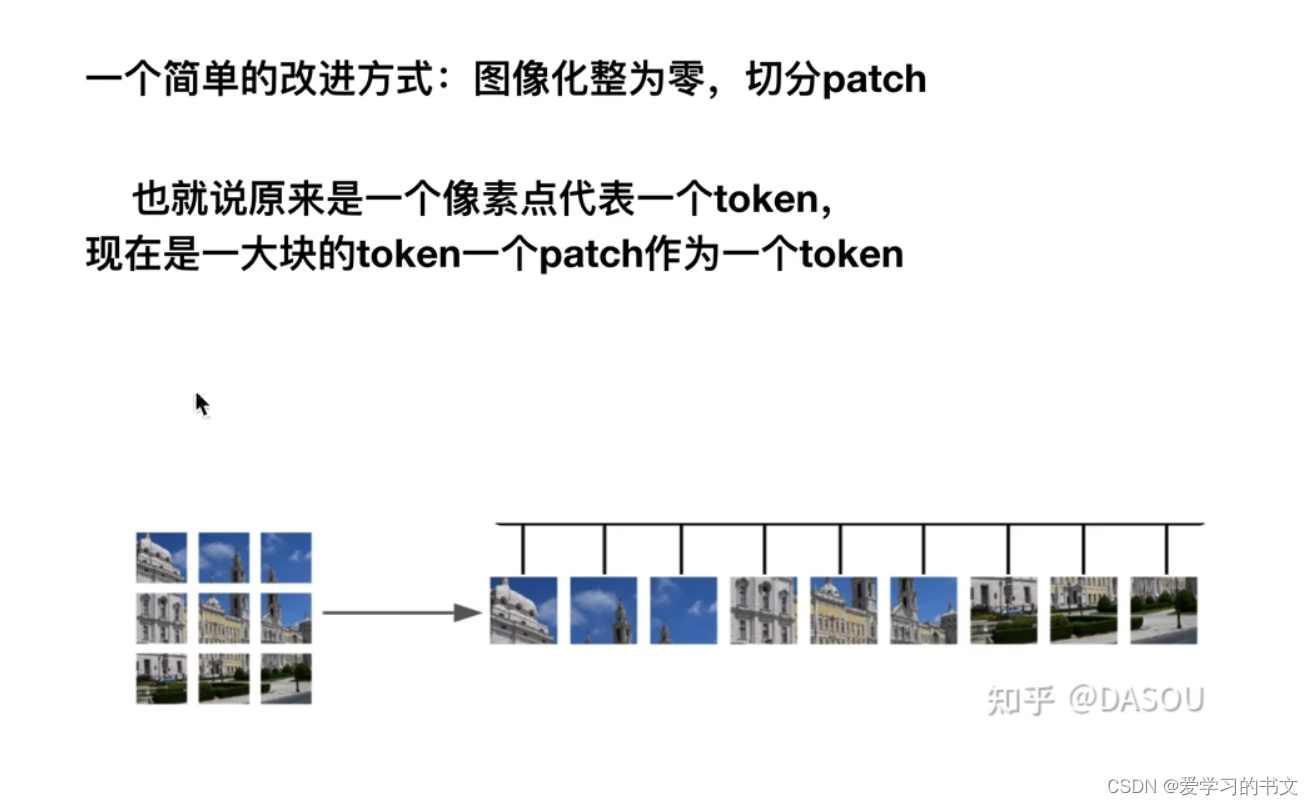
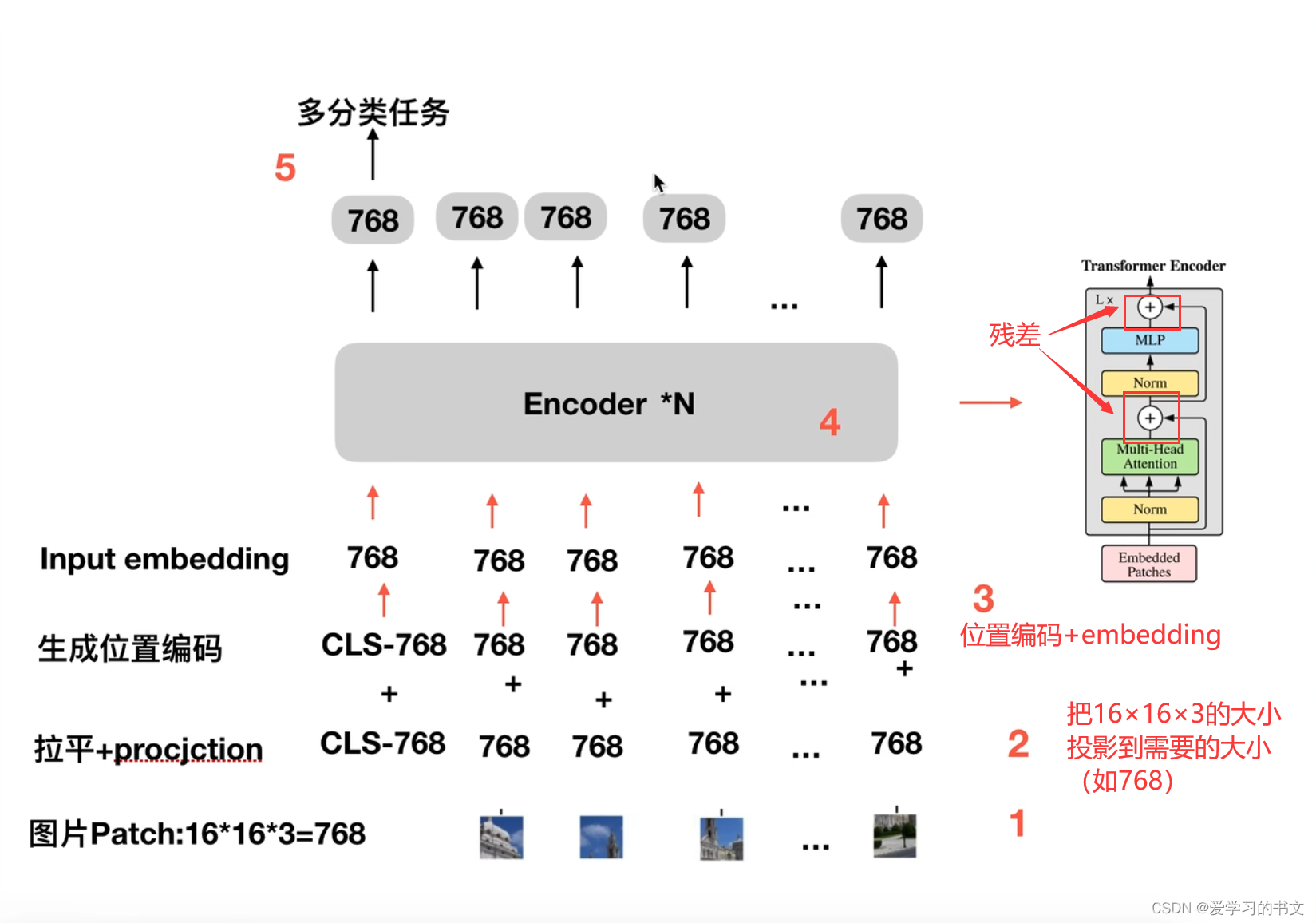
patch
将图片切割成patch,一个patch作为一个token
整体流程
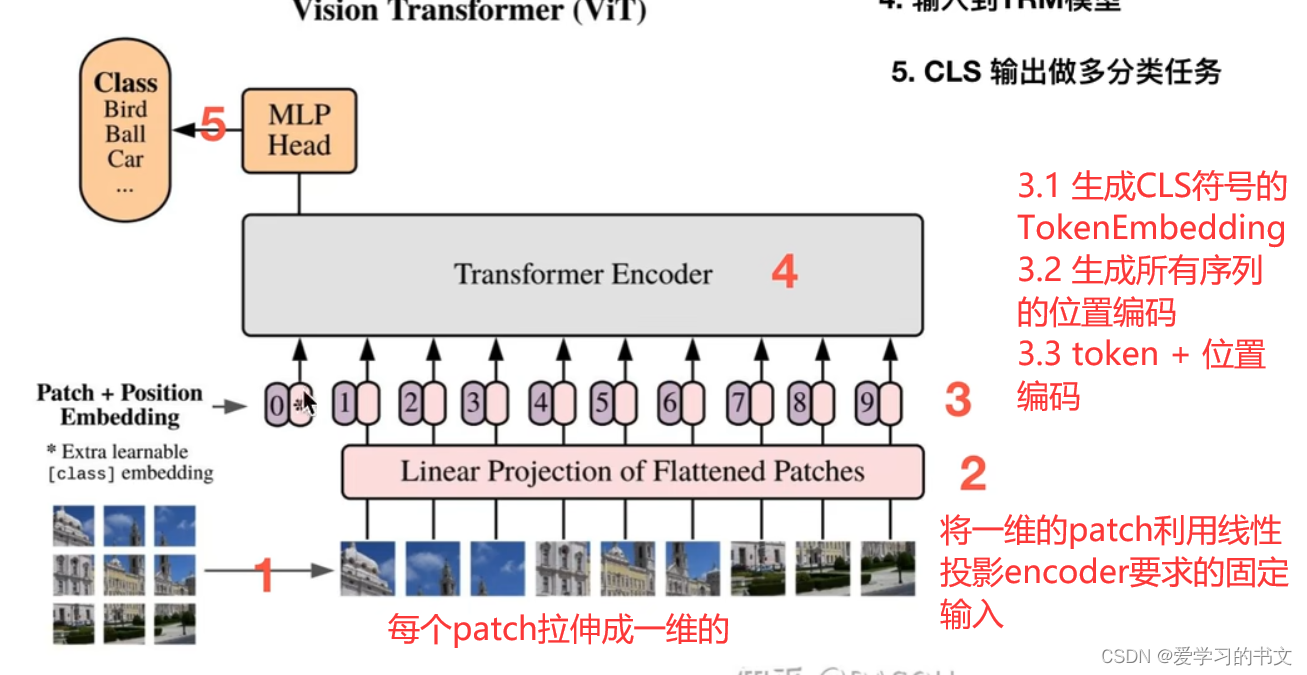
CLS
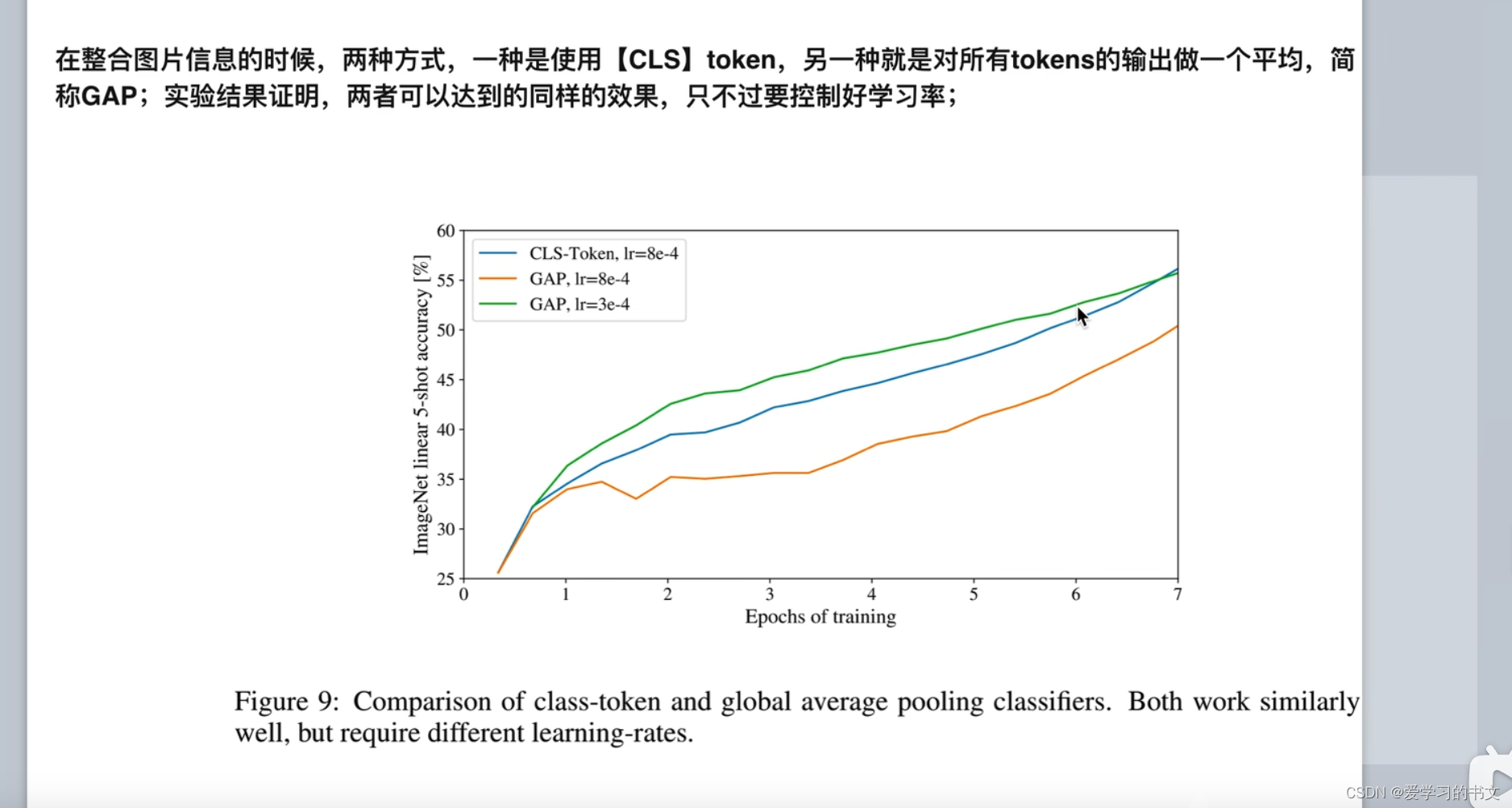
(DASOU)VIT不涉及到MLM这种形式的任务,只会有一个多分类任务,所以CLS符号不是必须的
蓝色:加CLS
绿色:不加CLS
都能达到同样的效果,就是中间的学习率不一样
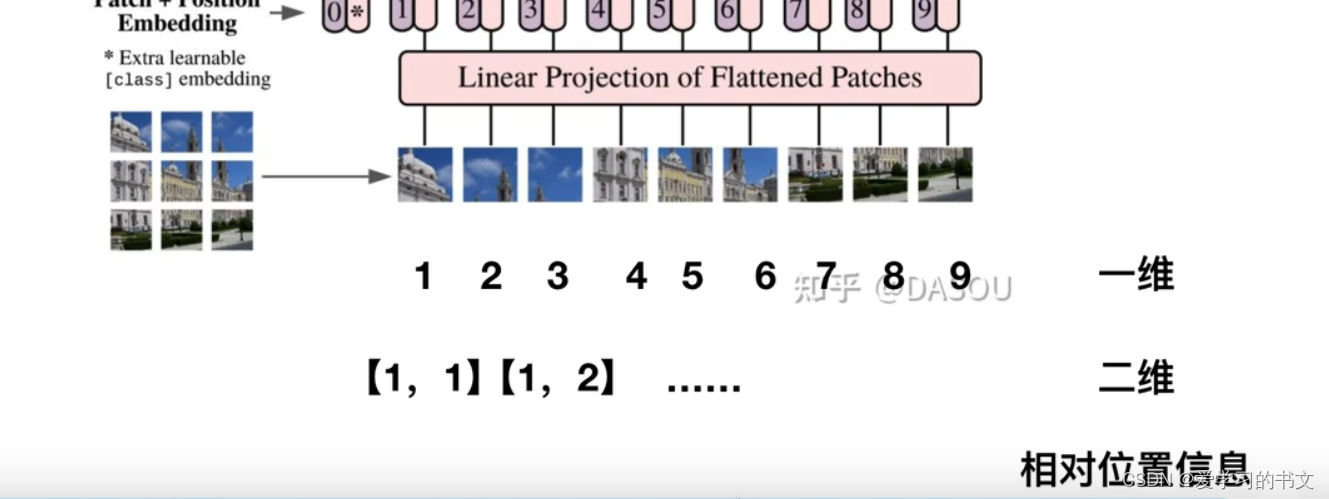
位置编码
有多种方式,如下图的:
- 一维
- 二维
- 相对
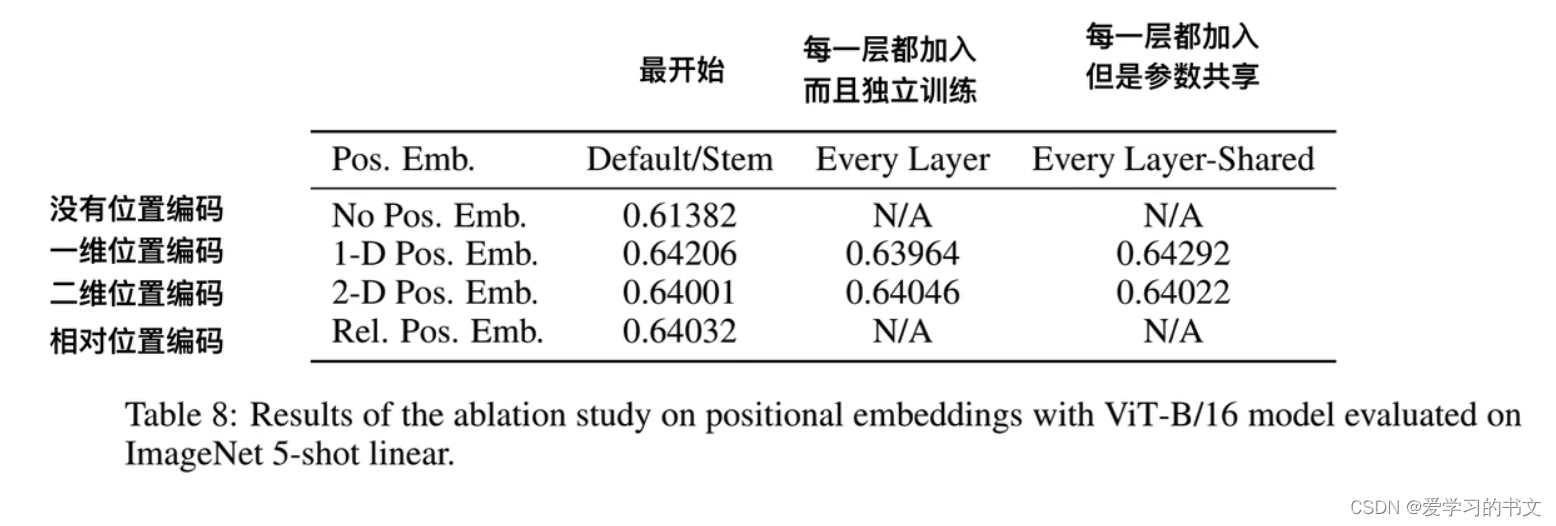
 实验结果,加入位置编码提升三个点,其他很难说了,,,
实验结果,加入位置编码提升三个点,其他很难说了,,,
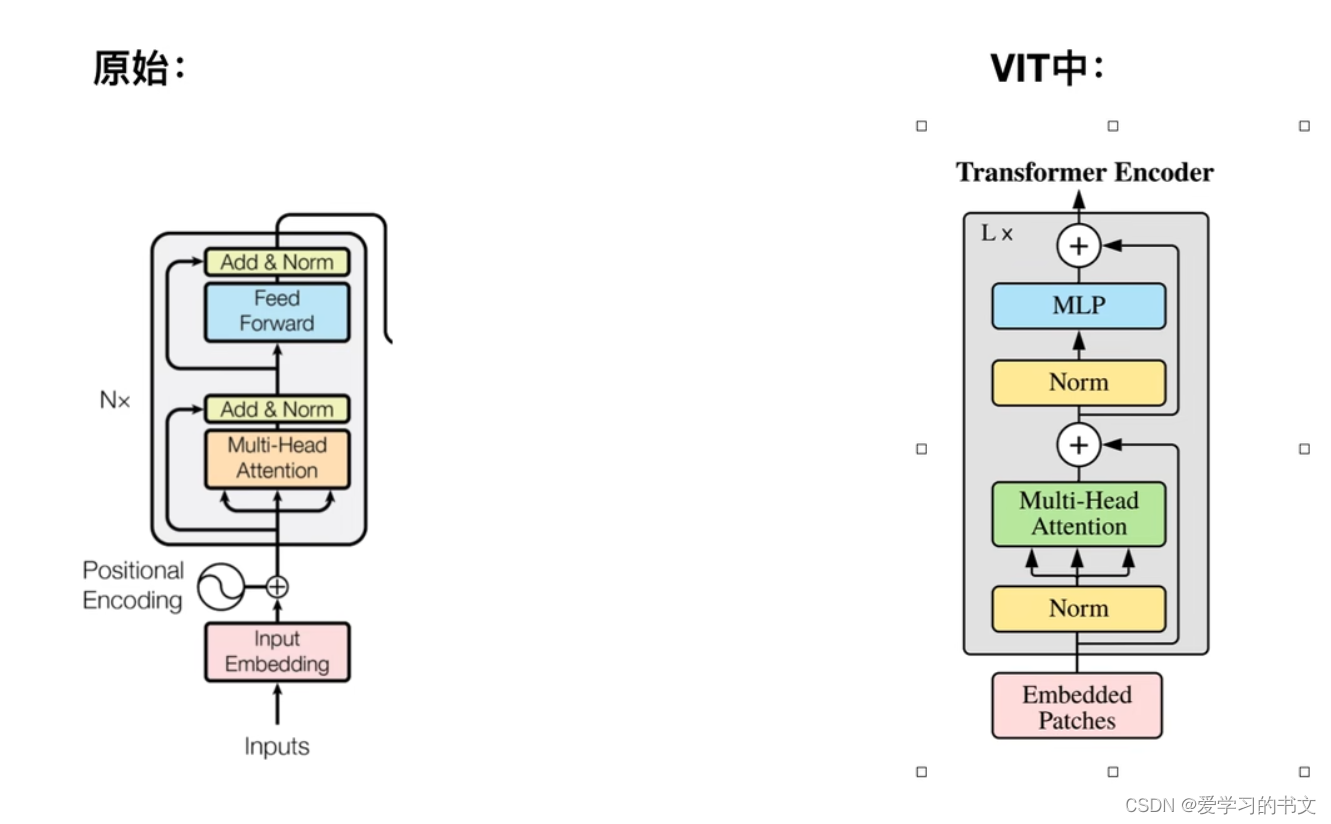
编码器
和原来Transformer的略有不同
- Norm提前了,变成了先Norm再Attention
- 和CV相比,不需要padding操作了,因为输入网络是靠线性投影来固定大小的
例子
代码
等DASOU回代码再更,꒰⑅•ᴗ•⑅꒱

DASOU老哥太强了,每次讲的深入浅出,基本上了解ViT咋回事了。✧(≖ ◡ ≖✿)
















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











