







目录
Abstract
在本文中,通过移除非线性和折叠权重矩阵来降低原来的GCN中额外的复杂性。本文从理论上分析了所得到的线性模型,并表明它对应于一个固定的低通滤波器和一个线性分类器。
实验评估表明,这些简化对许多下游应用的准确性都不会产生负面影响。此外,生成的模型可以扩展到更大的数据集,具有自然的可解释性,与FastGCN相比,可以产生高达两个数量级的加速比。
Introduction
GCNs将学习的一阶谱滤波器堆叠在一起,然后使用非线性激活函数来学习图形表示。 我们提出了SGC,通过反复消除GCN层之间的非线性,并将生成的函数折叠为单个线性变换,来降低GCN的过度复杂性。最终的线性模型在各种任务上表现出与GCN相当甚至更高的性能,同时计算效率更高,拟合的参数更少。
Simple Graph Convolution
定义 G = ( V , A ) G=(V,A) G=(V,A), V V V为顶点集, A A A为邻接矩阵, D D D为顶点度矩阵。每个顶点 v i v_i vi有一个对应的 d d d维的特征向量 x i x_i xi,所有特征向量为 X X X。每个顶点都属于 C C C类中的一个, Y Y Y表示类别标签集合。
对于所有顶点集,我们知道子集标签,并希望预测未知标签。
GCN
GCN为每个节点的特征 x i x_i xi学习一种新的特征表示,随后将其用作线性分类器的输入。在每个图卷积层中,节点表示在三个方向更新:特征传播、线性变换和逐点非线性激活 。
Feature propagation
在每个层的开始处,每个节点 v i v_i vi的特征 h i h_i hi用其局部邻域中的特征向量进行平均:
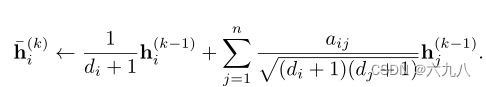
表示为矩阵运算为:
S = D ~ − 1 / 2 A ~ D ~ − 1 / 2 S=\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2} S=D~−1/2A~D~−1/2
其中 A ~ = A + I \tilde{A}=A+I A~=A+I, D ~ \tilde{D} D~为对应的度矩阵。
因此所有顶点的更新为:
H ˉ ( k ) ← S H ( k − 1 ) \bar{H}^{(k)}\gets SH^{(k-1)} Hˉ(k)←SH(k−1)
Feature transformation and nonlinear transition
局部平滑后,GCN层与标准MLP相同。每一层都与一个学习的权重矩阵相关联,在输出特征表示之前,逐点应用非线性激活函数,如ReLU 。
H ( k ) ← R e L U ( H ˉ ( k ) Θ ( k ) ) H^{(k)}\gets ReLU(\bar{H}^{(k)}\Theta^{(k)}) H(k)←ReLU(Hˉ(k)Θ(k))
第k层的逐点非线性变换之后是第(k+1)层的特征传播。
Classifier
对于节点分类,与标准MLP类似,GCN的最后一层使用softmax分类器预测标签
Y ^ G C N = s o f t m a x ( S H ( k − 1 ) Θ ( k ) ) \hat
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2077
2077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









