







 该文针对图神经网络中的节点特征和拓扑结构融合问题,提出了一种名为AM-GCN的自适应多通道框架。通过两个案例分析表明现有GCN方法在融合这两类信息时存在问题。AM-GCN利用特征空间和拓扑空间的特殊卷积模块及共享权重的通用卷积模块,结合注意力机制有效融合信息,提高了模型的性能。实验结果显示AM-GCN在处理相关特征和拓扑结构时能更好地捕获与节点标签相关的信息。
该文针对图神经网络中的节点特征和拓扑结构融合问题,提出了一种名为AM-GCN的自适应多通道框架。通过两个案例分析表明现有GCN方法在融合这两类信息时存在问题。AM-GCN利用特征空间和拓扑空间的特殊卷积模块及共享权重的通用卷积模块,结合注意力机制有效融合信息,提高了模型的性能。实验结果显示AM-GCN在处理相关特征和拓扑结构时能更好地捕获与节点标签相关的信息。
前言
本文针对于图神经网络中的节点特征信息和拓扑结构信息提出了一种自适应多通道图卷积框架,相当于对传统图卷积神经网络的优化和补充
论文链接:https://arxiv.org/pdf/2007.02265v2.pdf
github:https://github.com/zhumeiqiBUPT/AM-GCN
1. Fusion Capability Of GCNs : An Experimental Investigation
作者使用两种 case 测试了现有的 GCN 方法是否可以自适应的从图中学习到节点特征信息和拓扑结构信息,并且对两者进行有效融合用于分类任务。首先作者保证一个前提:节点标签与节点本身特征和网络拓扑结构的高相关性,基于此测试现有的 GCNs 方法的表现。作者认为一个具备优良融合能力的 GCN 方法可以自适应的提取带标签节点的相关信息,并产生一个好的结果。相反如果模型在这两个 case 中性能大幅度下降,则说明GCN不能自适应地从节点特征和拓扑结构中提取信息,即使节点特征或拓扑结构与节点标签之间存在较高的相关性。
1.1 Case1:Random Topology And Correlated Node Fearures
作者随机生成了一个包含 900 个节点的网络,其中两个节点之间生成边的概率为 0.03.每一个节点含有一个 50 维的特征。为了提取节点特征,随机为 900 个节点设置了三个标签。对于具备相同标签的节点,使用同样的高斯分布生成节点特征。三种类型节点所对应的高斯分布具有相同的协方差矩阵但是三者的中心彼此远离。在这个 case 中,节点标签表现与节点特征高度相关,但是与节点拓扑结构无关。
作者对该种 case 用 GCN 和 MLP 进行了实验,具体来说,对于每一类节点,选择 20 个节点进行训练,其他 200 个节点用于测试。并且在训练过程中避免过拟合。最终 MLP 和 GCN 的准确率分别是 100% 和 75.2%
作者认为 GCN 表现不佳的原因,GCN 提取节点特征和拓扑结构特征,但是没有将两者很好融合,导致拓扑结构特征反而影响节点特征造成不好的结果。
1.2 Case 2: Correlated Topology And Random Node Features
同样,在这种 case 中生成一个包含 900 个节点的图,其中每个节点的特征是 50 维,全部是随机生成的。对于拓扑结构,作者使用 SBM 将全部节点分成三个群体(0-299,3-599,600-899)。在每个群体中,建边的的概率为 0.03,在不同的群体之间,建边的概率为 0.0015。在这个数据集中,节点的标签与拓扑结构高度相关,因为在同一个社群中,节点标签一致。
作者分别使用 GCN 和 DeepWalk 对这个网络进行测试。最终得到的结果是 GCN:87% 和 DeepWalk:100%。GCN 表现不好的原因与上一个 case 的原因相似。
上述实现证明现有的 GCN 方法对于拓扑结构特征信息和节点特征信息无法有效融合,即使是在节点标签和节点特征和拓扑结构特征高度相关的前提下。同时在实际情况中,节点标签和特征信息可能还不具备高度相关性。基于此作者提出了 AM-GCN。
2. AM-GCN
设图可以表示为 G = ( A , X ) G=(\mathbf{A,X}) G=(A,X),其中 A ∈ R n × n \mathbf{A} \in \mathbb{R}^{n \times n} A∈Rn×n 代表对称的邻接矩阵。节点特征矩阵表示为 X ∈ R n × d \mathbf{X}\in\mathbb{R}^{n \times d} X∈Rn×d。
整个 AM-GCN 的架构如下:

AM-GCN 的特点是允许节点特征在特征空间和拓扑空间进行传播,与节点标签最相关的信息应该在这两个空间中被提取。具体来说,首先根据节点特征矩阵和代表拓扑关系的邻接矩阵生成对应的 Feature Graph 和 Topology Graph,应用特殊的卷积操作进行信息提取分别得到在特征空间的特征表示
Z
F
Z_F
ZF 和在拓扑空间的特征表示
Z
T
Z_T
ZT。同时作者考虑到在两个空间进行特征提取时,两者可能有同样的特征,因此设计了一个 Common Convolution 模块进行参数共享的图卷积来学习到相同特征角度上的嵌入
Z
C
T
Z_{CT}
ZCT 和
Z
C
F
Z_{CF}
ZCF 。并且加入合适的损失
L
\mathcal{L}
L 来保证学习结果的差异性。最终使用一个注意力模块来对学习到的嵌入进行整合,来提取到最相关的信息
Z
Z
Z 用于最终的分类任务。
2.1 Specific Convolution Module
Feature space
为了捕获节点在特征空间的依赖关系,作者选择使用 K 最近邻算法来建模拓扑结构生成 Feature Graph
G
f
=
(
A
f
,
X
)
G_f=(\mathbf{A}_f,\mathbf{X})
Gf=(Af,X)。具体来说,首先计算相似矩阵
S
∈
R
n
×
n
\mathbf{S} \in \mathbb{R}^{n \times n}
S∈Rn×n,在这里作者具体列出了两种最常用的相似度度量计算方法,其中
x
i
\mathbf{x}_i
xi 和
x
j
\mathbf{x}_j
xj 分别是节点
i
i
i 和
j
j
j 的特征向量。
- Cosine Similarity:使用两个向量夹角的余弦值来度量相似性:
S i j = x i ⋅ x j ∣ x i ∣ ∣ x j ∣ (1) \mathbf{S}_{ij}=\frac{\mathbf{x}_i\cdot\mathbf{x}_j}{|\mathbf{x}_i||\mathbf{x}_j|}\tag{1} Sij=∣xi∣∣xj∣xi⋅xj(1) - Heat Kernel: t t t 是热传导方程中的时间参数,作者设置 t = 2 t=2 t=2
S
i
j
=
e
−
∣
∣
x
i
−
x
j
∣
∣
2
t
(2)
\mathbf{S}_{ij}=e^{-\frac{||\mathbf{x}_i-\mathbf{x}_j||^2}{t}}\tag{2}
Sij=e−t∣∣xi−xj∣∣2(2)
在实验中,作者选择第一种余弦相似度的计算方式,然后为每个节点选择
k
k
k 个相似的节点对生成对应的边最终得到邻接矩阵
A
f
\mathbf{A}_f
Af
对于输入的图
(
A
f
,
X
)
(\mathbf{A}_f,\mathbf{X})
(Af,X),在特征空间
l
l
l 层的输出为
Z
f
(
l
)
\mathbf{Z}_f^{(l)}
Zf(l),可以表示为:
Z
f
(
l
)
=
R
e
L
U
(
D
~
f
−
1
2
A
~
f
D
~
f
−
1
2
Z
f
(
l
−
1
)
W
f
(
l
)
)
(3)
\mathbf{Z}_f^{(l)}=ReLU(\widetilde{\mathbf{D}}_f^{-\frac{1}{2}}\widetilde{\mathbf{A}}_f\widetilde{\mathbf{D}}_f^{-\frac{1}{2}}\mathbf{Z}_f^{(l-1)}\mathbf{W}_f^{(l)})\tag{3}
Zf(l)=ReLU(D
f−21A
fD
f−21Zf(l−1)Wf(l))(3)
就是经典的 GCN 方法。
Topology space
邻接矩阵和特征矩阵就是原图,可以理解为在拓扑空间进行图卷积就是传统 GCN。
2.2 Common Convolution Module
方法如下:
Z
c
t
(
l
)
=
R
e
L
U
(
D
~
t
−
1
2
A
~
t
D
~
t
−
1
2
Z
c
t
(
l
−
1
)
W
c
(
l
)
)
(4)
\mathbf{Z}_{ct}^{(l)}=ReLU(\widetilde{\mathbf{D}}_t^{-\frac{1}{2}}\widetilde{\mathbf{A}}_t\widetilde{\mathbf{D}}_t^{-\frac{1}{2}}\mathbf{Z}_{ct}^{(l-1)}\mathbf{W}_c^{(l)})\tag{4}
Zct(l)=ReLU(D
t−21A
tD
t−21Zct(l−1)Wc(l))(4)
Z
c
f
(
l
)
=
R
e
L
U
(
D
~
f
−
1
2
A
~
f
D
~
f
−
1
2
Z
c
f
(
l
−
1
)
W
c
(
l
)
)
(5)
\mathbf{Z}_{cf}^{(l)}=ReLU(\widetilde{\mathbf{D}}_f^{-\frac{1}{2}}\widetilde{\mathbf{A}}_f\widetilde{\mathbf{D}}_f^{-\frac{1}{2}}\mathbf{Z}_{cf}^{(l-1)}\mathbf{W}_c^{(l)})\tag{5}
Zcf(l)=ReLU(D
f−21A
fD
f−21Zcf(l−1)Wc(l))(5)
最主要的就是分享权重,剩下的就是两个图各自的输入,其实也就是邻接矩阵存在差异,一个是原始的邻接矩阵,一个是经过
k
k
k 近邻算法的相似度计算得到的。最终两者的结果进行加权得到:
Z
C
=
(
Z
C
T
+
Z
C
F
)
/
2
(6)
\mathbf{Z}_C=(\mathbf{Z}_{CT}+\mathbf{Z}_{CF})/2\tag{6}
ZC=(ZCT+ZCF)/2(6)
2.3 Attention Mechanism
注意力机制实现方法如下(实质就是求解归一化的注意力权重系数,然后加权的到最终结果):
(
α
t
,
α
c
,
α
f
)
=
a
t
t
(
Z
T
,
Z
C
,
Z
F
)
(7)
(\alpha_t,\alpha_c,\alpha_f) = att(\mathbf{Z}_T,\mathbf{Z}_C,\mathbf{Z}_F)\tag{7}
(αt,αc,αf)=att(ZT,ZC,ZF)(7)
ω
T
i
=
q
T
⋅
t
a
n
h
(
W
⋅
(
z
T
i
)
T
+
b
)
(8)
\omega_{T}^i=\mathbf{q}^T\cdot tanh(\mathbf{W}\cdot(\mathbf{z}_T^{i})^T+\mathbf{b})\tag{8}
ωTi=qT⋅tanh(W⋅(zTi)T+b)(8)
α
T
i
=
s
o
f
t
m
a
x
(
ω
T
i
)
=
e
x
p
(
ω
T
i
)
e
x
p
(
ω
T
i
)
e
x
p
(
ω
C
i
)
e
x
p
(
ω
F
i
)
(9)
\alpha_T^{i}=softmax(\omega_T^i)=\frac{exp(\omega_T^i)}{exp(\omega_T^i)exp(\omega_C^i)exp(\omega_F^i)}\tag{9}
αTi=softmax(ωTi)=exp(ωTi)exp(ωCi)exp(ωFi)exp(ωTi)(9)
Z
=
α
T
⋅
Z
T
+
α
C
⋅
C
T
+
α
F
⋅
F
T
(10)
\mathbf{Z}=\alpha_T\cdot\mathbf{Z}_T + \alpha_C\cdot\mathbf{C}_T + \alpha_F\cdot\mathbf{F}_T\tag{10}
Z=αT⋅ZT+αC⋅CT+αF⋅FT(10)
2.4 损失函数
这里没什么可以说的,比较有意思的是一个判断相关性的指标:HSIC,与互信息一样可以评判两个变量之间的相关性,具体可以参考:
https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/101400126
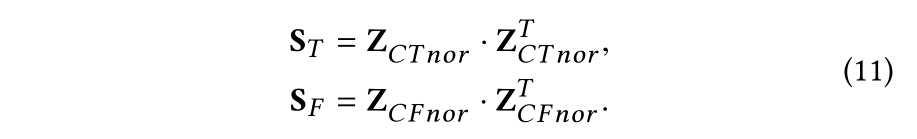
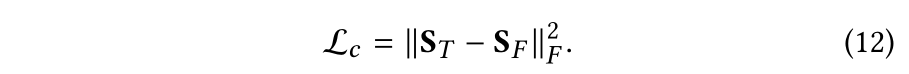
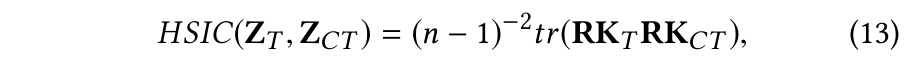
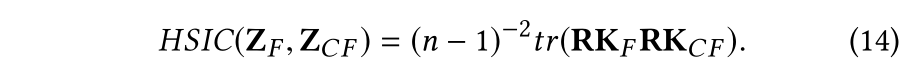
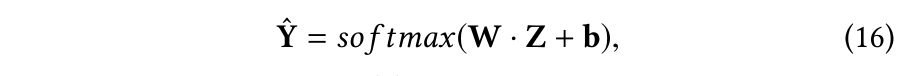
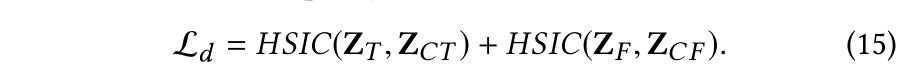
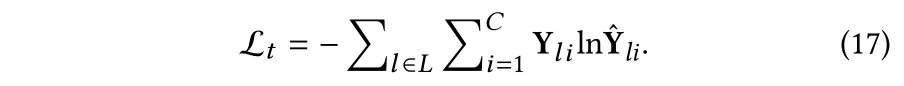
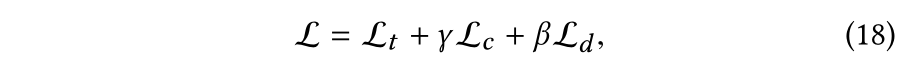
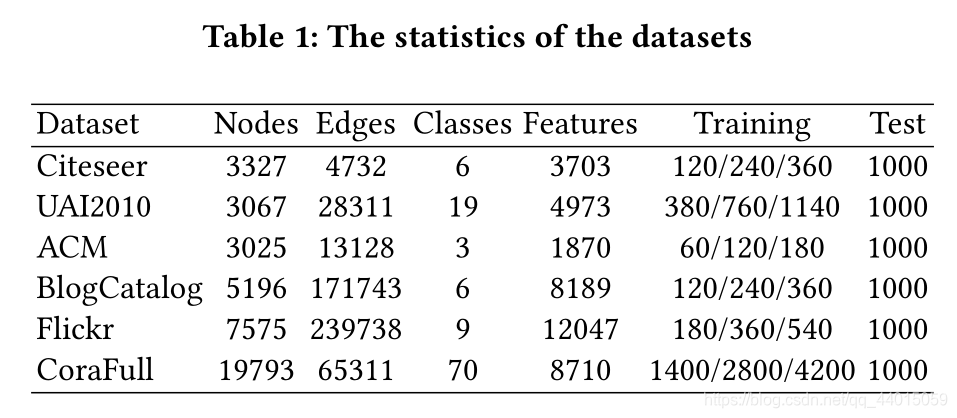
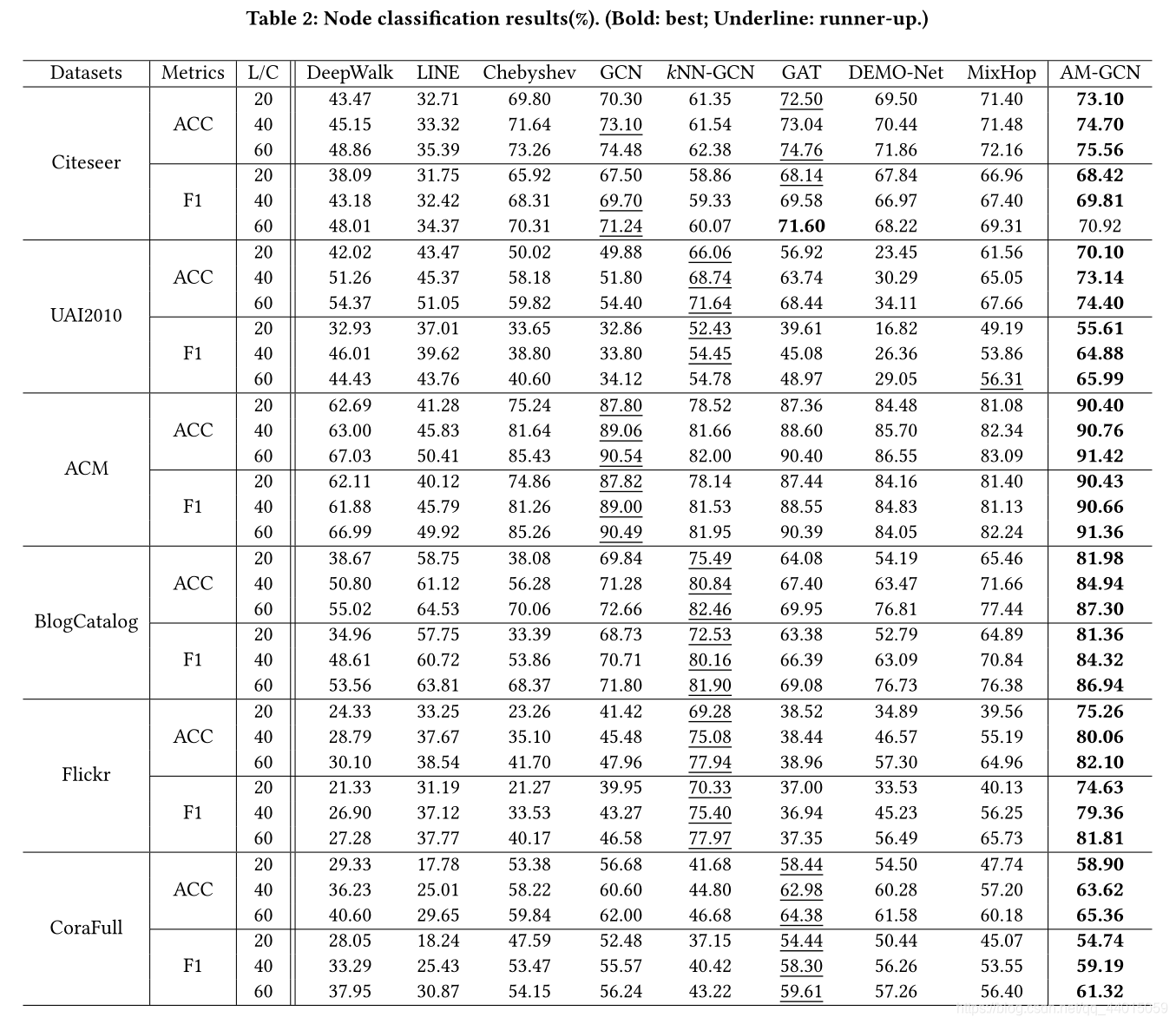
3. Experiments

















 1588
1588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









