







 本文指导读者正确配置YOLOv9模型,包括使用YAML文件、注意中文字符和表情符号对编码的影响,以及train.py与train_dual.py、train_triple.py之间的区别和使用场景。作者提供了关于Silence模块和编码问题的解决方案。
本文指导读者正确配置YOLOv9模型,包括使用YAML文件、注意中文字符和表情符号对编码的影响,以及train.py与train_dual.py、train_triple.py之间的区别和使用场景。作者提供了关于Silence模块和编码问题的解决方案。
🥑 Welcome to Aedream同学 's blog! 🥑
文章目录
✨✨✨✨立志真正解决大家问题,只写精品博客文章,感谢关注,共同进步✨✨✨✨
前言
YOLOv9提出后部分博主发布了训练教程,但真的质量堪忧,甚至train.py, train_dual.py or train_triple.py该使用哪个都不对,因此报错❗❗。
所以制作本期教程以供大家参考,如有错误欢迎指正交流🤝🤝
基本操作
代码链接:👿 https://github.com/WongKinYiu/yolov9
- 配置环境
- 下载代码
- 解压,如果训练models/detect/yolov9-c.yaml,配置train_dual.py。
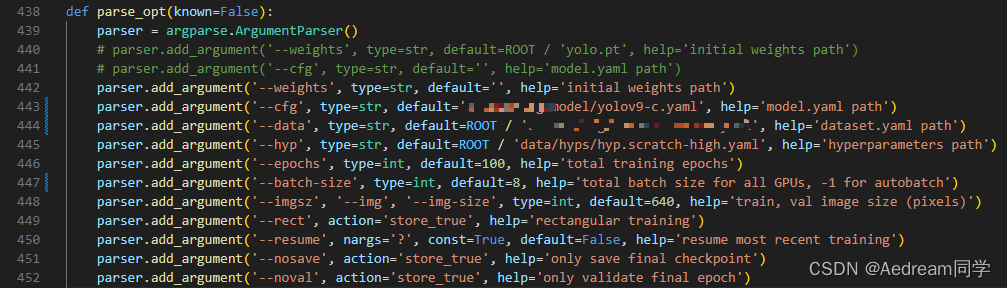
YAML文件解析
部分人疑惑yolov9-c.yaml中的Silence是什么
根据models/common.py
class Silence(nn.Module):
def __init__(self):
super(Silence, self).__init__()
def forward(self, x):
return x
Silence 就是无操作,输入x,输出还是x
主要是为了在后续调用原输入
注意事项❗❗❗
‘gbk’ codec can’t decode byte 0x80 in position 238: illegal multibyte sequence
检测数据集配置文件的yaml文件中是否存在中文或表情符号等,将其删除。
train.py, train_dual.py or train_triple.py
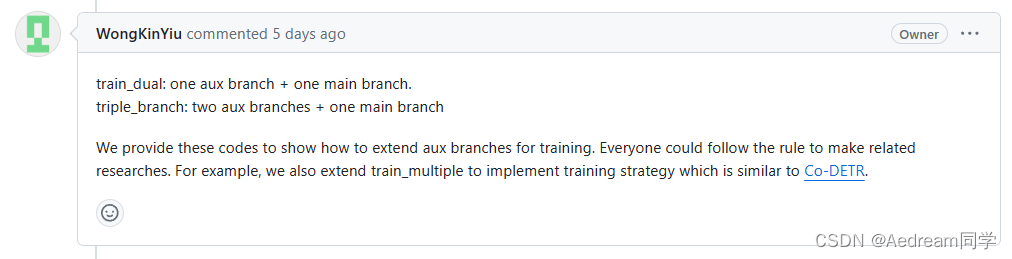
提供作者的原回复做参考。
- train_dual:1 个辅助分支 + 1 个主分支。
- Triple_branch:两个辅助分支 + 一个主分支
我们提供这些代码来展示如何扩展辅助分支进行训练。 大家可以按照规则进行相关研究。 例如,我们还扩展了train_multiple来实现类似于Co-DETR的训练策略。
所以理论上可根据train_dual.py和 train_triple.py自己研究n个辅助分支 + 一个主分支如何训练。
AttributeError: ‘list’ object has no attribute ‘view’
使用train.py训练yolov9-c.yaml就会报错
AttributeError: ‘list’ object has no attribute ‘view’ · Issue #22 · WongKinYiu/yolov9 (github.com)
问题描述:
In loss_tal.py: pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1)
The error is as follows:
AttributeError: 'list' object has no attribute 'view'
作者回复:
YOLOv9 models should be trained with train_dual.py




















 5362
5362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











