







安装
pip install chromadb
你的本地电脑需要有完整的c++的环境
Building wheels for collected packages: hnswlib
Building wheel for hnswlib (pyproject.toml) ... error
error: subprocess-exited-with-error
× Building wheel for hnswlib (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [12 lines of output]
running bdist_wheel
不然在编译hnswlib库的时候会报错
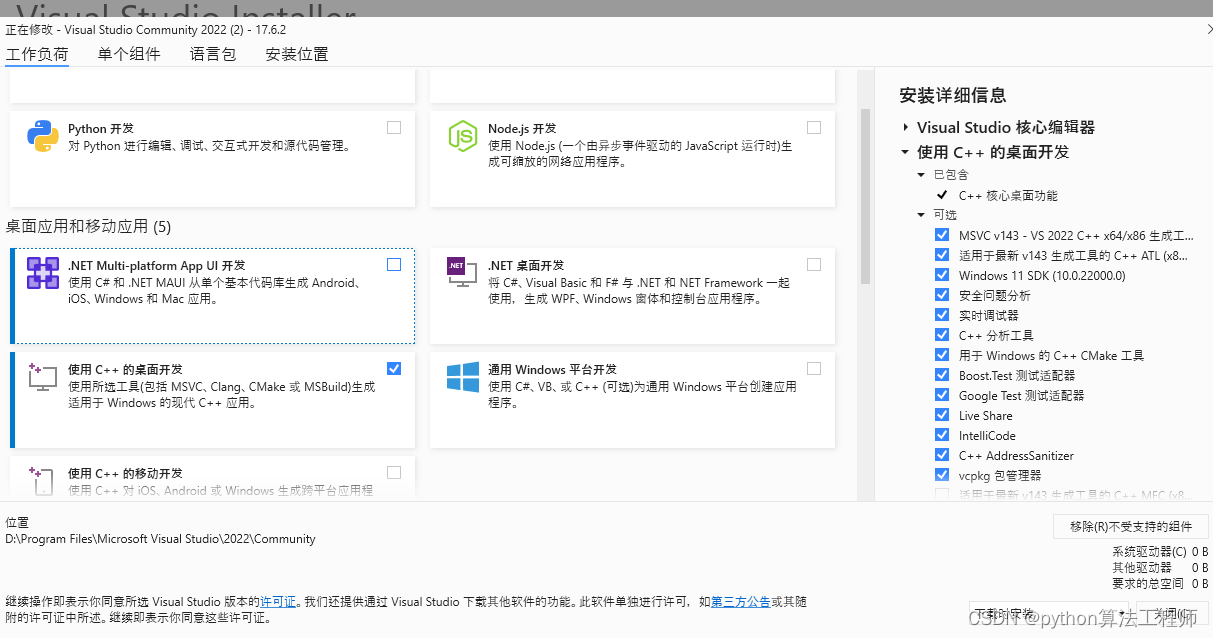
安装vs 勾选c++的桌面开发
使用教程
http://www.bimant.com/blog/chroma-vector-db/
获取chroma client对象
import chromadb
chroma_client = chromadb.Client()
#创建Chroma数据集
collection = chroma_client.create_collection(name="my_collection")
# 向Chroma数据集添加文档
collection.add(
documents=["This is a document", "This is another document"],
metadatas=[{
"source": "my_source"}, {
"source":  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









