







 文章提供了将大规模遥感图像检测数据集DIOR中的VOC格式标签转换为YOLO格式的Python代码。DIOR数据集包含20个类别和大量实例,代码详细解释了如何处理XML标签并生成YOLO所需的训练、验证和测试标签文件,同时调整图像到相应的训练、验证和测试子集。
文章提供了将大规模遥感图像检测数据集DIOR中的VOC格式标签转换为YOLO格式的Python代码。DIOR数据集包含20个类别和大量实例,代码详细解释了如何处理XML标签并生成YOLO所需的训练、验证和测试标签文件,同时调整图像到相应的训练、验证和测试子集。
遥感图像DIOR数据集和VOC转为yolo格式代码
DIOR数据集
DIOR是一个用于光学遥感图像目标检测的大规模基准数据集。数据集包含23463个图像和192472个实例,涵盖20个对象类。这20个对象类是飞机、机场、棒球场、篮球场、桥梁、烟囱、水坝、高速公路服务区、高速公路收费站、港口、高尔夫球场、地面田径场、天桥、船舶、体育场、储罐、网球场、火车站、车辆和风磨。
下载地址:http://www.escience.cn/people/gongcheng/DIOR.html
也可在飞桨AI Studio下载:飞桨官网
下载如下文件:
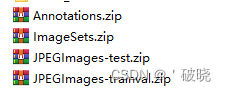
我的文件目录如下(也可以用自己的,在代码里修改即可),其中JEPGImahes文件夹里面是所有的训练、验证和测试图片(之后在代码中会随机划分为训练:验证:测试=6:2:2的数目),Annotations里面是voc格式的xml文件。
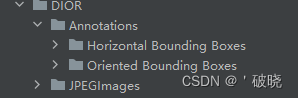
执行代码之后就会生成如下文件
VOC转yolo代码
# coding:utf-8
import os
import random
import argparse
import xml.etree.ElementTree as ET
from os import getcwd
from shutil import copyfile
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='DIOR/Annotations/Horizontal Bounding Boxes', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
opt = parser.parse_args()
sets = ['train', 'val', 'test']
classes = ['airplane', 'airport', 'baseballfield', 'basketballcourt', 'bridge', 'chimney', 'dam',
'Expressway-Service-area', 'Expressway-toll-station', 'golffield', 'groundtrackfield', 'harbor',
'overpass', 'ship', 'stadium', 'storagetank', 'tenniscourt', 'trainstation', 'vehicle', 'windmill']
abs_path = os.getcwd()
print(abs_path)
if not os.path.exists('DIOR_dataset/'):
os.makedirs('DIOR_dataset/')
if not os.path.exists('DIOR_dataset/labels/'):
os.makedirs('DIOR_dataset/labels/')
if not os.path.exists('DIOR_dataset/labels/train'):
os.makedirs('DIOR_dataset/labels/train')
if not os.path.exists('DIOR_dataset_yolo/labels/test'):
os.makedirs('DIOR_dataset/labels/test')
if not os.path.exists('DIOR_dataset_yolo/labels/val'):
os.makedirs('DIOR_dataset/labels/val')
if not os.path.exists('DIOR_dataset/images/'):
os.makedirs('DIOR_dataset/images/')
if not os.path.exists('DIOR_dataset/images/train'):
os.makedirs('DIOR_dataset/images/train')
if not os.path.exists('DIOR_dataset/images/test'):
os.makedirs('DIOR_dataset/images/test')
if not os.path.exists('DIOR_dataset/images/val'):
os.makedirs('DIOR_dataset/images/val')
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id, path):
#输入输出文件夹,根据实际情况进行修改
in_file = open('DIOR/Annotations/Horizontal Bounding Boxes/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('DIOR_dataset/labels/' + path + '/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
#difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
train_percent = 0.6
test_percent = 0.2
val_percent = 0.2
xmlfilepath = opt.xml_path
# txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
# if not os.path.exists(txtsavepath):
# os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
list_index = list(list_index)
random.shuffle(list_index)
train_nums = list_index[:int(num * train_percent)]
test_nums = list_index[int(num * train_percent): int(num * test_percent)+int(num * train_percent)]
val_nums = list_index[int(num * test_percent)+int(num * train_percent):]
for i in list_index:
name = total_xml[i][:-4]
if i in train_nums:
convert_annotation(name, 'train') # lables
image_origin_path = 'DIOR/JPEGImages/' + name + '.jpg'
image_target_path = 'DIOR_dataset/images/train/' + name + '.jpg'
copyfile(image_origin_path, image_target_path)
if i in test_nums:
convert_annotation(name, 'test') # lables
image_origin_path = 'DIOR/JPEGImages/' + name + '.jpg'
image_target_path = 'DIOR_dataset/images/test/' + name + '.jpg'
copyfile(image_origin_path, image_target_path)
if i in val_nums:
convert_annotation(name, 'val') # lables
image_origin_path = 'DIOR/JPEGImages/' + name + '.jpg'
image_target_path = 'DIOR_dataset/images/val/' + name + '.jpg'
copyfile(image_origin_path, image_target_path)

















 225
225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









