







在深度学习的图像分类任务中,VGG是一个不可忽视的经典模型。它由牛津大学的Visual Geometry Group(视觉几何组)与2014年提出,并在当年的ImageNet挑战赛中取得了优异的成绩。接下来本文将带你一起了解VGG模型及其网络结构和代码实现。
VGG是什么?
VGG是一种用于图像分类的卷积神经网络(CNN)模型。它的名字来源于提出它的研究团队——Visual Geometry Group。VGG的核心思想是通过堆叠多个小尺寸的卷积层来构建深层网络,从而提取图像中的复杂特征。
VGG有多个版本,其中最常用的是VGG16和VGG19,数字代表网络的层数(包括卷积层和全连接层)。
VGG的特点
VGG的核心特点可以总结为以下几点:
- 小卷积核:VGG主要使用3×3的小娟集合,而不是更大的卷积核(如5×5或7×7)。小卷积核可以减少参数数量,同时通过堆叠多个小卷积核,可以达到和大卷积核相同的感受野。
- 深度堆叠:VGG通过不断堆叠卷积层和池化层,构建了一个非常深的网络(通常是16层或19层),从而能够提取更复杂的特征。
- 简单而统一的结构:VGG的结构非常规整,每一层的卷积核大小和步长都是固定的,便于理解和实现。
VGG的网络结构
VGG的网络结构可以分为两部分:卷积部分和全连接部分。
卷积部分
卷积部分由5个块(Block)组成,每个块包含多个卷积层和一个池化层。如下图所示:
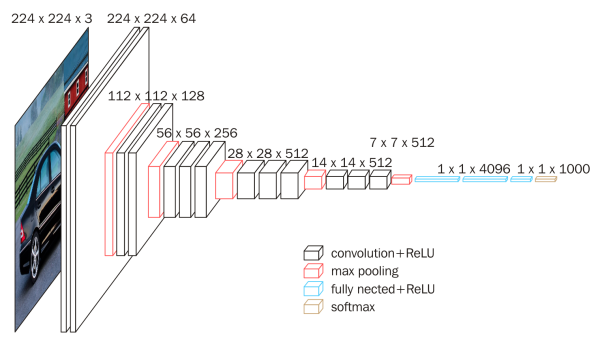
- Block1:
- 2个卷积层:
3×3卷积,64个滤波器->ReLU激活 - 1个池化层:
2×2最大池化,步长2 - 输出尺寸:
112×112×64
- 2个卷积层:
- Block2:
- 2个卷积层:
3×3卷积,128个滤波器->ReLU激活 - 1个池化层:
2×2最大池化,步长2 - 输出尺寸:
56×56×128
- 2个卷积层:
- Block3:
- 3个卷积层:
3×3卷积,256个滤波器->ReLU激活 - 1个池化层:
2×2最大池化,步长2 - 输出尺寸:
28×28×256
- 3个卷积层:
- Block4:
- 3个卷积层:
3×3卷积,512个滤波器->ReLU激活 - 1个池化层:
2×2最大池化,步长2 - 输出尺寸:
14×14×512
- 3个卷积层:
- Block5:
- 3个卷积层:
3×3卷积,512个滤波器->ReLU激活 - 1个池化层:
2×2最大池化,步长2 - 输出尺寸:
7×7×512
- 3个卷积层:
全连接部分
卷积部分的输出会通过全连接层映射到最终的类别概率。
- Flatten层:将
7×7×512的特征图展平为一个向量,长度为7×7×512=25088。 - 全连接层1:
25088->4096,接ReLU激活和Dropout。 - 全连接层2:
4096->4096,接ReLU激活和Dropout。 - 全连接层3:
4096->1000(1000是ImageNet的类别数),接Softmax激活。
VGG的作用
VGG的主要作用是提取图像的特征,并用于图像分类任务。它的优点包括:
- 结构简单,易于理解和实现。
- 通过深度堆叠,能够提取更复杂的特征。
- 在ImageNet等大型数据集上表现优异。
不过,VGG的缺点是参数量较大,计算成本较高,因此在后来的研究中被更高效的模型(如ResNet)取代。
VGG的代码实现
以下是使用PyTorch实现VGG16的代码示例:
import torch
import torch.nn as nn
class VGG16(nn.Module):
def __init__(self, num_classes=1000):
super(VGG16, self).__init__()
self.features = nn.Sequential(
# Block 1
nn.Conv2d(3,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6860
6860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











