








GoogleNetv1全文翻译

论文结构

摘要

我们提出了一种代号为 Inception 的深度卷积神经网络架构,它负责在 2014 年 ImageNet 大规模视觉识别挑战赛(ILSVRC14)中为分类和检测设定新的技术水平。 该架构的主要特点是提高了网络内部计算资源的利用率。 这是通过精心设计的设计实现的,该设计允许增加网络的深度和宽度,同时保持计算预算不变。 为了优化质量,架构决策基于 Hebbian 原理和多尺度处理的直觉。 我们提交的 ILSVRC14 中使用的一种特殊形式称为 GoogLeNet,这是一种 22 层深度网络,其质量是在分类和检测的背景下进行评估的。

1 引言

在过去三年中,主要由于深度学习(更具体地说是卷积网络)[10]的进步,图像识别和目标检测的质量取得了巨大的进步。 一个令人鼓舞的消息是,大部分进展不仅是更强大的硬件、更大的数据集和更大的模型的结果,而主要是新想法、算法和改进的网络架构的结果。 例如,ILSVRC 2014 竞赛中的顶级参赛作品除了用于检测目的的同一竞赛的分类数据集外,没有使用任何新的数据源。 我们向 ILSVRC 2014 提交的 GoogLeNet 实际上使用的参数比两年前 Krizhevsky 等人 [9] 的获胜架构少了 12 倍,同时明显更加准确。 目标检测的最大收益并非来自单独使用深层网络或更大的模型,而是来自深层架构和经典计算机的协同作用视觉,如 Girshick 等人的 R-CNN 算法 [6]。
另一个值得注意的因素是,随着移动和嵌入式计算的持续发展,我们算法的效率(尤其是其功耗和内存使用)变得越来越重要。 值得注意的是,本文提出的深层架构设计的考虑因素包括了这个因素,而不是纯粹关注准确率数字。 对于大多数实验,模型的设计目的是在推理时保持 15 亿次乘加的计算预算,因此它们最终不会成为纯粹的学术好奇心,而是可以应用于现实世界,甚至以合理的成本处理大型数据集。

在本文中,我们将重点研究一种用于计算机视觉的高效深度神经网络架构,代号为 Inception,其名称源自 Lin 等人[12]的论文Network in network,并结合著名的“we need to go deeper” 互联网模因[1]。 在我们的例子中,“深度”这个词有两种不同的含义:首先,我们以“Inception模块”的形式引入了新的组织级别,还有更直接的增加网络的含义深度。 一般来说,人们可以将 Inception 模型视为 [12] 的逻辑巅峰,同时从 Arora 等人的理论工作中获得灵感和指导 [2]。 该架构的优点在 ILSVRC 2014 分类和检测挑战中得到了实验验证,其性能显着优于当前最先进的。
2 相关工作

从 LeNet-5 [10] 开始,卷积神经网络 (CNN) 通常具有标准结构 - 堆叠卷积层(可选地后跟对比度归一化和最大池化),后面跟着一个或多个全连接层即FC层。 这种基本设计的变体在图像分类文献中很普遍,并且在 MNIST、CIFAR 以及最引人注目的 ImageNet 分类挑战中取得了迄今为止最好的结果 [9, 21]。 对于 Imagenet 等较大的数据集,最近的趋势是增加层数 [12] 和层大小 [21, 14],同时使用 dropout [7] 来解决过拟合问题。
尽管担心最大池化层会导致准确的空间信息丢失,但与[9]相同的卷积网络架构也已成功应用于定位[9,14]、物体检测[6,14,18,5]和人类姿态估计[19]。 受到灵长类视觉皮层神经科学模型的启发,Serre 等人。 [15]使用一系列不同大小的固定Gabor滤波器来处理多个尺度,类似于Inception模型。 然而,与[15]的固定2层深度模型相反,Inception模型中的所有过滤器都是学习的。 此外,Inception 层重复多次,导致 GoogLeNet 的深度模型达到 22 层模型。
Network-in-Network 是 Lin 等人提出的一种方法 [12]为了增加神经网络的表征能力。 当应用于卷积层时,该方法可以被视为附加的 1×1 卷积层,后面通常是修正的线性激活 [9]。 这使其能够轻松集成到当前的 CNN 管道中。 我们在我们的架构中大量使用这种方法。 然而,在我们的设置中,1 × 1 卷积有双重目的:最关键的是,它们主要用作降维模块以消除计算瓶颈,否则会限制我们网络的大小。 这不仅可以增加网络的深度,还可以增加网络的宽度,而不会造成明显的性能损失。
当前目标检测的主要方法是 Girshick 等人提出的卷积神经网络区域 (R-CNN) [6]。R-CNN 将整体检测问题分解为两个子问题:首先以与类别无关的方式利用颜色和超像素一致性等低级线索来提出潜在的对象建议,然后使用 CNN 分类器来识别这些位置的对象类别。 这种两阶段方法利用了低级线索的边界框分割的准确性,以及最先进的 CNN 的强大分类能力。 我们在检测提交中采用了类似的流程,但在两个阶段都探索了增强功能,例如用于更高对象边界框召回的多框 [5] 预测,以及用于更好地对边界框建议进行分类的集成方法。
3 动机和高层考虑

提高深度神经网络性能的最直接方法是增加其规模。 这包括增加网络的深度(层数)和宽度(每层的单元数量)。 这是训练更高质量模型的一种简单且安全的方法,特别是考虑到大量标记训练数据的可用性。 然而,这个简单的解决方案有两个主要缺点。
较大的尺寸通常意味着较大的参数数量,这使得扩大的网络更容易过度拟合,特别是在训练集中标记示例的数量有限的情况下。这可能成为一个主要瓶颈,因为创建高质量训练集可能很棘手且成本高昂,特别是如果需要专业的人类评估者来区分像 ImageNet 中的细粒度视觉类别(即使在 1000 类 ILSVRC 子集中) 如图1所示

统一增加网络规模的另一个缺点是计算资源的使用急剧增加。 例如,在深度视觉网络中,如果链接两个卷积层,则其滤波器数量的任何均匀增加都会导致计算量呈二次方增加。 如果增加的容量使用效率低下(例如,如果大多数权重最终接近于零),则会浪费大量计算。 由于在实践中计算预算始终是有限的,因此即使主要目标是提高结果质量,计算资源的有效分配也优于不加选择地增加大小。
解决这两个问题的根本方法是最终从完全连接的架构转向稀疏连接的架构,甚至在卷积内部也是如此。 除了模仿生物系统之外,由于 Arora 等人的开创性工作,这还将具有更坚实的理论基础的优势。 [2]。 他们的主要结果表明,如果数据集的概率分布可以用一个大型的、非常稀疏的深度神经网络来表示,那么通过分析最后一层激活的相关统计并对具有高度相关输出的神经元进行聚类,可以逐层构建最优网络拓扑。 尽管严格的数学证明需要非常强大的条件,但这一说法与众所周知的赫布原理(神经元一起放电、连接在一起)产生共鸣,这一事实表明,即使在不太严格的条件下,基本思想也适用于实践。
不利的一面是,当今的计算基础设施在非均匀稀疏数据结构的数值计算方面效率非常低。 即使算术运算的数量减少 100 倍,查找和缓存未命中的开销仍然占主导地位,以至于切换到稀疏矩阵不会有回报。 通过使用稳定改进、高度调整的数值库,可以利用底层 CPU 或 GPU 硬件的微小细节,实现极快的密集矩阵乘法,从而进一步拉大差距 [16, 9]。 此外,非均匀稀疏模型需要更复杂的工程和计算基础设施。 当前大多数面向视觉的机器学习系统仅通过使用卷积来利用空间域中的稀疏性。 然而,卷积被实现为与较早层中的补丁的密集连接的集合。 ConvNets传统上在特征维度上使用随机和稀疏的连接表,从[11]开始为了打破对称性和提高学习能力,趋势又回到了[9]的全连接,以便更好地优化并行计算。 结构的均匀性、大量的滤波器和更大的批量大小允许利用高效的密集计算。
这就提出了一个问题:是否有希望进行下一个中间步骤:一种利用额外稀疏性的架构,即使是在滤波器级别,正如理论所建议的,但通过利用密集矩阵上的计算来利用我们当前的硬件。 关于稀疏矩阵计算的大量文献(例如[3])表明,将稀疏矩阵聚类成相对密集的子矩阵往往可以为稀疏矩阵乘法提供最先进的实用性能。 认为在不久的将来类似的方法将被用于自动构建非均匀深度学习架构似乎并不牵强。

Inception 架构最初是作为第一作者的一个案例研究,用于评估复杂网络拓扑构建算法的假设输出,该算法试图逼近 [2] 所暗示的视觉网络,并通过密集、易于获得的结构覆盖假设结果。 尽管这是一项高度推测性的工作,但仅在对拓扑的精确选择进行两次迭代之后,我们就已经可以看到相对于基于[12]的参考架构的适度收益。 经过进一步调整学习率、超参数和改进训练后方法论中,我们确定所得到的 Inception 架构在定位和对象检测的背景下特别有用,作为 [6] 和 [5] 的基础网络。 有趣的是,虽然大多数最初的架构选择都经过了彻底的质疑和测试,但结果证明它们至少是局部最优的。
但必须谨慎:尽管所提出的架构在计算机视觉领域取得了成功,但其质量是否可以归因于其构建的指导原则仍然值得怀疑。 确保需要更彻底的分析和验证:例如,基于下述原理的自动化工具是否会为视觉网络找到类似但更好的拓扑。 最令人信服的证据是,自动化系统是否可以创建网络拓扑,从而使用相同的算法但具有非常不同的全局架构在其他领域获得类似的收益。 至少,Inception 架构的初步成功为未来在这个方向上的激动人心的工作提供了坚定的动力
稀疏矩阵



4 结构细节


Inception 架构的主要思想是基于找出如何用容易获得的密集组件来近似和覆盖卷积视觉网络中的最佳局部稀疏结构。 请注意,假设平移不变性意味着我们的网络将由卷积构建块构建。 我们所需要的只是找到最佳的局部构造并在空间上重复它。 阿罗拉等人 [2]提出了一种逐层构造,其中应该分析最后一层的相关统计数据并将它们聚类成具有高相关性的单元组。 这些簇形成下一层的单元,并连接到上一层的单元。 我们假设前一层的每个单元对应于输入图像的某个区域,并且这些单元被分组到滤波器组中。 在较低层(靠近输入的层)中,相关单元将集中在局部区域。 这意味着,我们最终会得到很多集中在单个区域中的簇,并且它们可以被下一层中的 1×1 卷积层覆盖,如 [12] 中所建议的。 然而,我们也可以预期,将会有越来越少的、在空间上更分散的簇可以被较大块上的卷积所覆盖,并且在越来越大的区域上,patches的数量将会减少。 为了避免补丁对齐问题,当前的 Inception 架构仅限于滤波器大小 1×1、3×3 和 5×5,但这一决定更多是基于便利性而非必要性。 这也意味着建议的架构是所有这些层的组合,其输出滤波器组连接成单个输出向量,形成下一阶段的输入。 此外,由于池化操作对于当前最先进的卷积网络的成功至关重要,因此建议在每个此类阶段添加替代并行池化路径也应该具有额外的有益效果(见图 2(a))

由于这些“Inception 模块”彼此堆叠,它们的输出相关统计数据必然会有所不同:随着更高抽象的特征被更高层捕获,它们的空间集中度预计会降低,这表明随着我们移动到更高层,3×3 和 5×5 卷积的比率应该增加
上述模块的一个大问题(至少在这种简单的形式中)是,即使是少量的 5×5 卷积,在具有大量滤波器的卷积层之上也可能非常昂贵。 一旦将池化单元添加到混合中,这个问题就会变得更加明显:它们的输出过滤器的数量等于前一阶段过滤器的数量。 池化层的输出与卷积层的输出的合并将导致阶段之间的输出数量不可避免地增加。 即使这种架构可能覆盖最佳稀疏结构,但它的效率非常低,导致几个阶段内的计算崩溃。


引入1x1卷积核可以减少通道数






这引出了所提出的架构的第二个想法:在计算需求会增加太多的地方明智地应用降维和投影。 这是基于嵌入的成功:即使是低维嵌入也可能包含有关相对较大的图像块的大量信息。 然而,嵌入以密集、压缩的形式表示信息,并且压缩信息更难建模。 我们希望在大多数地方保持我们的表示稀疏(根据[2]的条件要求),并且仅在信号必须聚合时才压缩信号。 也就是说,1×1 卷积用于在昂贵的 3×3 和 5×5 卷积之前计算降维。 除了用作降维之外,它们还包括使用校正线性激活,这使得它们具有双重用途。 最终结果如图2(b)所示。
一般来说,Inception 网络是由上述类型的模块相互堆叠组成的网络,偶尔有步幅为 2 的最大池层,以使网格的分辨率减半。 出于技术原因(训练期间的内存效率),仅在较高层开始使用 Inception 模块,同时保持较低层采用传统的卷积方式似乎是有益的。 这并不是绝对必要的,只是反映了我们当前实施中的一些基础设施效率低下。
这种架构的主要优点之一是它允许显着增加每个阶段的单元数量,而不会导致计算复杂性不受控制地激增。 降维的普遍使用允许将最后一级的大量输入滤波器屏蔽到下一层,首先降低它们的维度,然后再用大块大小对它们进行卷积。 这种设计的另一个实际有用的方面是,它符合直觉,即视觉信息应该在不同尺度上进行处理,然后进行聚合,以便下一阶段可以同时从不同尺度中提取特征。
计算资源的改进使用允许增加每个阶段的宽度以及阶段的数量,而不会陷入计算困难。 利用inception架构的另一种方法是创建其性能稍差但计算成本更低的版本。 我们发现,所有包含的旋钮和控制杆都可以实现计算资源的受控平衡,从而使网络比具有非 Inception 架构的类似性能网络快 2 − 3 倍,但这需要仔细的手动设计 。
5 GoogleNet

我们选择 GoogLeNet 作为 ILSVRC14 比赛中的队名。 这个名字是对 Yann LeCuns 开创性的 LeNet 5 网络 [10] 的致敬。 我们还使用 GoogLeNet 来指代我们在竞赛提交中使用的 Inception 架构的特定化身。 我们还使用了更深、更宽的 Inception 网络,其质量稍差,但将其添加到集成中似乎略微改善了结果。 我们省略了该网络的细节,因为我们的实验表明,确切的架构参数的影响相对较小。 出于演示目的,表 1 中描述了最成功的特定实例(名为 GoogLeNet)。 我们的集成中 7 个模型中有 6 个使用了完全相同的拓扑(使用不同的采样方法进行训练)。



所有卷积,包括 Inception 模块内的卷积,都使用修正线性激活。 我们网络中感受野的大小为 224×224,采用均值减法的 RGB 颜色通道。 “#3×3 reduce”和“#5×5 reduce”代表3×3和5×5卷积之前使用的减少层中1×1过滤器的数量。 在 pool proj 列中内置最大池化之后,可以看到投影层中 1×1 滤波器的数量。 所有这些reduction/projection层也使用修正线性激活。
该网络的设计考虑到了计算效率和实用性,因此推理可以在单个设备上运行,甚至包括计算资源有限的设备,尤其是内存占用较低的设备。 当仅计算带参数的层时,网络深度为 22 层(如果我们还计算池化,则网络深度为 27 层)。 用于构建网络的层(独立构建块)总数约为 100。然而,这个数字取决于所使用的机器学习基础设施系统。 分类器之前使用平均池是基于[12],尽管我们的实现不同之处在于我们使用了额外的线性层。 这使得我们可以轻松地针对其他标签集调整和微调我们的网络,但这主要是为了方便,我们预计它不会产生重大影响。 研究发现,从全连接层到平均池化的转变将 top-1 准确率提高了约 0.6%,但是即使在删除全连接层之后,dropout 的使用仍然至关重要。
考虑到网络的深度相对较大,以有效的方式将梯度传播回所有层的能力是一个问题。 一个有趣的见解是,相对较浅的网络在这项任务上的强劲表现表明,网络中间层产生的特征应该非常具有辨别力。 通过添加连接到这些中间层的辅助分类器,我们希望鼓励分类器较低阶段的区分,增加传播回来的梯度信号,并提供额外的正则化。 这些分类器采用较小的卷积网络的形式,置于 Inception (4a) 和 (4d) 模块的输出之上。 在训练期间,它们的损失以折扣权重添加到网络的总损失中(辅助分类器的损失按 0.3 加权)。 在推理时,这些辅助网络将被丢弃。

侧面额外网络的具体结构,包括辅助分类器,如下:
- 平均池化层的过滤器大小为 5×5,步长为 3,导致 (4a) 阶段的输出为 4×4×512,(4d) 阶段的输出为 4×4×528。
- 具有 128 个滤波器的 1×1 卷积,用于降维和修正线性激活。
- 具有 1024 个单元和修正线性激活的全连接层。
- dropout输出比例为 70% 的dropout层。
- 以 softmax 损失作为分类器的线性层(预测与主分类器相同的 1000 个类,但在推理时删除)
图 3 描绘了所得网络的示意图。


Figure 3: GoogLeNet network with all the bells and whistles


6 训练方法

我们的网络使用 DistBelief [4] 分布式机器学习系统进行训练,使用适量的模型和数据并行性。 尽管我们仅使用基于 CPU 的实现,但粗略估计表明,GoogLeNet 网络可以在一周内使用少量高端 GPU 进行训练以达到收敛,主要限制是内存使用。 我们的训练使用动量为 0.9 的异步随机梯度下降[17],固定学习率计划(每 8 个周期将学习率降低 4%)。 Polyak 平均 [13] 用于创建推理时使用的最终模型。

在比赛前的几个月里,我们的图像采样方法发生了很大的变化,并且已经融合的模型接受了其他选项的训练,有时还结合了改变的超参数,如 dropout 和学习率,因此很难给出明确的指导训练这些网络的最有效的单一方法。 更复杂的是,受[8]的启发,一些模型主要针对较小的相关crops进行训练,其他模型则针对较大的crops进行训练。 尽管如此,赛后验证效果非常好的一个方案是对图像的各种大小的块进行采样,其大小均匀分布在图像区域的 8% 到 100% 之间,其长宽比在 3/4 到 3/4 之间随机选择。 此外,我们发现 Andrew Howard [8] 的光度扭曲在某种程度上有助于对抗过度拟合。 此外,我们开始使用随机插值方法(双线性、面积、最近邻和三次,等概率)来调整大小,相对较晚,并与其他超参数变化相结合,因此我们无法确定最终结果是否受到其使用的积极影响。

7 ILSVRC 2014 分类挑战赛设置和结果

ILSVRC 2014 分类挑战涉及将图像分类为 Imagenet 层次结构中 1000 个叶节点类别之一的任务。 大约有 120 万张图像用于训练,50,000 张图像用于验证,100,000 张图像用于测试。 每张图像都与一个真实类别相关联,并且根据最高得分的分类器预测来衡量性能。 通常会报告两个数字:top-1 准确率(将真实情况与第一个预测类别进行比较)和 top-5 错误率(将真实情况与前 5 个预测类别进行比较:如果ground truth位于前 5 名之列,无论其排名如何,图像被视为正确分类)。该挑战使用前 5 个错误率进行排名。
我们参加了挑战,没有使用外部数据进行训练。 除了本文提到的训练技术之外,我们在测试过程中还采用了一组技术来获得更高的性能,我们将在下面详细说明。
- 我们独立训练了同一 GoogLeNet 模型的 7 个版本(包括一个更宽的版本),并用它们进行了集成预测。 这些模型使用相同的初始化(即使具有相同的初始权重,主要是由于oversight)和学习率策略进行训练,它们仅在采样方法和看到输入图像的随机顺序上有所不同。

- 在测试过程中,我们采用了比 Krizhevsky 等人更激进的裁剪方法 [9]。 具体来说,我们将图像大小调整为 4 个比例,其中较短的尺寸(高度或宽度)分别为 256、288、320 和 352,取这些调整大小图像的左、中、右正方形(在竖向图像的情况下,我们取顶部、中心和底部的方块)。 然后,对于每个正方形,我们采用 4 个角和中心 224×224 裁剪以及调整大小为 224×224 的正方形及其镜像版本。 这导致每张图像有 4×3×6×2 = 144 种裁剪。 Andrew Howard [8] 在前一年的文章中使用了类似的方法,我们根据经验验证了该方法的性能比提议的方案稍差。 我们注意到,在实际应用中,这种激进的cropping可能没有必要,因为在存在合理数量的crops后,更多crops的好处就变得微乎其微(正如我们稍后将展示的那样)。

- Softmax 概率对多种crops和所有单独的分类器进行平均以获得最终预测。 在我们的实验中,我们分析了验证数据的替代方法,例如crops上的最大池化和分类器上的平均,但它们导致性能比简单平均差。

在本文的其余部分中,我们分析了影响最终提交的整体性能的多个因素。
我们最终提交的挑战赛在验证和测试数据上均获得了 6.67% 的 top-5 错误率,在其他参赛者中排名第一。 与 2012 年的 SuperVision 方法相比,相对减少了 56.5%,与上一年的最佳方法 (Clarifai) 相比,相对减少了约 40%,这两种方法都使用外部数据来训练分类器。 下表显示了一些表现最佳的方法的统计数据。
我们还通过改变下表中预测图像时使用的模型数量和裁剪数量来分析和报告多个测试选择的性能。 当我们使用一种模型时,我们选择验证数据上 top-1 错误率最低的模型。 所有数字都在验证数据集上报告,以免与测试数据统计数据过度拟合。


8 ILSVRC 2014检测挑战赛设置和结果

ILSVRC 检测任务是在 200 个可能的类别中的图像中的对象周围生成边界框。 如果检测到的对象与真实类别匹配并且其边界框重叠至少 50%(使用 Jaccard 索引),则视为正确。 无关的检测被视为误报false positive并受到处罚。 与分类任务相反,每个图像可能包含许多对象或不包含对象,并且它们的尺度可能从大到小不等。 使用平均精度 (mAP) 报告结果。


GoogLeNet 所采用的检测方法与 [6] 中的 R-CNN 类似,但使用 Inception 模型作为区域分类器进行了增强。 此外,通过将选择性搜索 [20] 方法与多框 [5] 预测相结合,改进了区域提议步骤,以实现更高的对象边界框召回率。 为了减少误报false positive数量,超像素大小增加了 2 倍。 这使得来自选择性搜索算法的提案减半。 我们添加了来自 multi-box [5] 结果的 200 个区域提案,总共占 [6] 使用的提案的约 60%,同时将覆盖范围从 92% 增加到 93%。 通过增加覆盖率来减少提议数量的总体效果是单个模型案例的平均精度mAP提高了 1%。 最后,我们在对每个区域进行分类时使用 6 个 ConvNet 的集合这将结果准确率从 40% 提高到 43.9%。 请注意,与 R-CNN 相反,由于时间不够,我们没有使用边界框回归。
我们首先报告最重要的检测结果,并显示自第一版检测任务以来的进展情况。 与 2013 年的结果相比,准确率几乎翻了一番。 表现最好的团队都使用卷积网络。 我们在表 4 中报告了官方得分以及每个团队的常见策略:使用外部数据、集成模型或上下文模型。 外部数据通常是 ILSVRC12 分类数据,用于预训练模型,然后根据检测数据进行细化。 一些团队还提到了本地化数据的使用。 由于定位任务边界框的很大一部分不包含在检测数据集中,因此可以使用该数据预训练通用边界框回归器,就像使用分类进行预训练一样。 GoogLeNet条目没有使用本地化数据进行预训练。
在表 5 中,我们仅比较使用单个模型的结果。 表现最好的模型来自 Deep Insight,令人惊讶的是,在 3 个模型的集成中仅提高了 0.3 个点,而 GoogLeNet 在集成中获得了明显更强的结果。

目标检测的平均精度和 mAP
为了计算物体检测的AP,我们首先需要了解IoU。 IoU 由预测边界框和真实边界框的交集面积与并集面积之比给出。


IoU 将用于确定预测的边界框 (BB) 是 TP、FP 还是 FN。不评估 TN,因为假设每个图像中都有一个对象。让我们考虑下图:

该图像包含一个人和马及其相应的地面真实边界框。让我们暂时忽略那匹马。我们在此图像上运行对象检测模型,并收到该人的预测边界框。传统上,如果 IoU > 0.5,我们将预测定义为 TP。下面描述了可能的情况



当我们的对象检测模型错过目标时,它将被视为漏报。两种可能的情况如下:
- 当根本没有检测到的时候。
- 当预测的 BB IoU > 0.5 但分类错误时,预测的 BB 将为 FN。

9 总结

我们的结果似乎提供了坚实的证据,表明通过现成的密集构建块来近似预期的最佳稀疏结构是改进计算机视觉神经网络的可行方法。 与较浅且较不宽的网络相比,该方法的主要优点是在计算要求适度增加的情况下获得显着的质量增益。 另请注意,尽管我们既不利用上下文也不执行边界框回归,我们的检测工作仍然具有竞争力,这一事实进一步证明了 Inception 架构的优势。 尽管预计可以通过相似深度和宽度的更昂贵的网络来实现相似质量的结果,但我们的方法提供了确凿的证据,表明转向稀疏架构总体上是可行且有用的想法。 这表明未来有望在 [2] 的基础上以自动化方式创建更稀疏和更精细的结构。






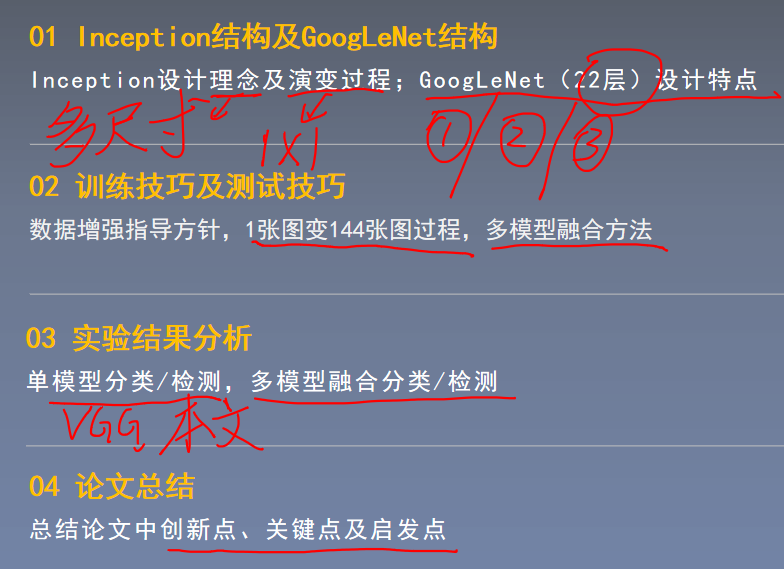
论文研究背景、成果及意义


1*1卷积可以大大减少网络参数,压缩特征图厚度





论文图表





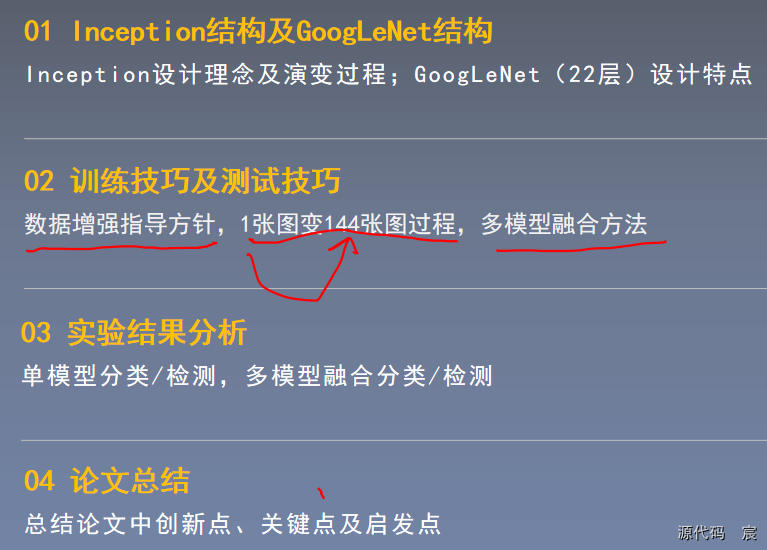
论文代码复现准备工作

GoogleNetv1推理代码及运行结果

googlenet_inference.py
# -*- coding: utf-8 -*-
import os
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
import time
import json
import torch.nn as nn
import torch
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
import torchvision.models as models
from tools.common_tools import get_googlenet
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def img_transform(img_rgb, transform=None):
"""
将数据转换为模型读取的形式
:param img_rgb: PIL Image
:param transform: torchvision.transform
:return: tensor
"""
if transform is None:
raise ValueError("找不到transform!必须有transform对img进行处理")
img_t = transform(img_rgb)
return img_t
def process_img(path_img):
# hard code
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
inference_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop((224, 224)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# path --> img
img_rgb = Image.open(path_img).convert('RGB')
# Image.open()得到的是PIL的图片格式
# img --> tensor
img_tensor = img_transform(img_rgb, inference_transform)
img_tensor.unsqueeze_(0) # chw --> bchw
img_tensor = img_tensor.to(device)
return img_tensor, img_rgb
def load_class_names(p_clsnames, p_clsnames_cn):
"""
加载标签名
:param p_clsnames:
:param p_clsnames_cn:
:return:
"""
with open(p_clsnames, "r") as f:
class_names = json.load(f)
with open(p_clsnames_cn, encoding='UTF-8') as f: # 设置文件对象
class_names_cn = f.readlines()
return class_names, class_names_cn
if __name__ == "__main__":
# config
path_state_dict = os.path.join(BASE_DIR, "..", "data", "googlenet-1378be20.pth")
# 图片路径
path_img = os.path.join(BASE_DIR, "..", "..", "alexNet/data", "Golden Retriever from baidu.jpg")
# path_img = os.path.join(BASE_DIR, "..", "data", "tiger cat.jpg")
path_classnames = os.path.join(BASE_DIR, "..", "data", "imagenet1000.json")
path_classnames_cn = os.path.join(BASE_DIR, "..", "data", "imagenet_classnames.txt")
# load class names
cls_n, cls_n_cn = load_class_names(path_classnames, path_classnames_cn)
# 1/5 load img
img_tensor, img_rgb = process_img(path_img)
# 2/5 load model
# 与论文不同处:5*5用3*3代替,所有卷积之后加入BN,
googlenet_model = get_googlenet(path_state_dict, device, True)
# 3/5 inference tensor --> vector
with torch.no_grad():
time_tic = time.time()
outputs = googlenet_model(img_tensor)
time_toc = time.time()
# 4/5 index to class names
_, pred_int = torch.max(outputs.data, 1)
_, top5_idx = torch.topk(outputs.data, 5, dim=1)
pred_idx = int(pred_int.cpu().numpy()[0])
pred_str, pred_cn = cls_n[pred_idx], cls_n_cn[pred_idx]
print("img: {} is: {}\n{}".format(os.path.basename(path_img), pred_str, pred_cn))
print("time consuming:{:.2f}s".format(time_toc - time_tic))
# 5/5 visualization
plt.imshow(img_rgb)
plt.title("predict:{}".format(pred_str))
top5_num = top5_idx.cpu().numpy().squeeze()
text_str = [cls_n[t] for t in top5_num]
for idx in range(len(top5_num)):
plt.text(5, 15+idx*30, "top {}:{}".format(idx+1, text_str[idx]), bbox=dict(fc='yellow'))
plt.show()
common_tools.py
# -*- coding: utf-8 -*-
import numpy as np
import torch
import os
import random
from PIL import Image
from torch.utils.data import Dataset
import torchvision.models as models
def get_googlenet(path_state_dict, device, vis_model=False):
"""
创建模型,加载参数
:param path_state_dict:
:return:
"""
model = models.googlenet(init_weights=False)
if path_state_dict:
pretrained_state_dict = torch.load(path_state_dict)
model.load_state_dict(pretrained_state_dict)
model.eval()
if vis_model:
from torchsummary import summary
summary(model, input_size=(3, 224, 224), device="cpu")
model.to(device)
return model






googlenet.py
import warnings
from collections import namedtuple
from functools import partial
from typing import Any, Callable, List, Optional, Tuple
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
from ..transforms._presets import ImageClassification
from ..utils import _log_api_usage_once
from ._api import register_model, Weights, WeightsEnum
from ._meta import _IMAGENET_CATEGORIES
from ._utils import _ovewrite_named_param, handle_legacy_interface
__all__ = ["GoogLeNet", "GoogLeNetOutputs", "_GoogLeNetOutputs", "GoogLeNet_Weights", "googlenet"]
GoogLeNetOutputs = namedtuple("GoogLeNetOutputs", ["logits", "aux_logits2", "aux_logits1"])
GoogLeNetOutputs.__annotations__ = {"logits": Tensor, "aux_logits2": Optional[Tensor], "aux_logits1": Optional[Tensor]}
# Script annotations failed with _GoogleNetOutputs = namedtuple ...
# _GoogLeNetOutputs set here for backwards compat
_GoogLeNetOutputs = GoogLeNetOutputs
class GoogLeNet(nn.Module):
__constants__ = ["aux_logits", "transform_input"]
def __init__(
self,
num_classes: int = 1000,
aux_logits: bool = True,
transform_input: bool = False,
init_weights: Optional[bool] = None,
blocks: Optional[List[Callable[..., nn.Module]]] = None,
dropout: float = 0.2,
dropout_aux: float = 0.7,
) -> None:
super().__init__()
_log_api_usage_once(self)
if blocks is None:
blocks = [BasicConv2d, Inception, InceptionAux]
if init_weights is None:
warnings.warn(
"The default weight initialization of GoogleNet will be changed in future releases of "
"torchvision. If you wish to keep the old behavior (which leads to long initialization times"
" due to scipy/scipy#11299), please set init_weights=True.",
FutureWarning,
)
init_weights = True
if len(blocks) != 3:
raise ValueError(f"blocks length should be 3 instead of {len(blocks)}")
conv_block = blocks[0]
inception_block = blocks[1]
inception_aux_block = blocks[2]
self.aux_logits = aux_logits
self.transform_input = transform_input
self.conv1 = conv_block(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = conv_block(64, 64, kernel_size=1)
self.conv3 = conv_block(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = inception_block(192, 64, 96, 128, 16, 32, 32)
self.inception3b = inception_block(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = inception_block(480, 192, 96, 208, 16, 48, 64)
self.inception4b = inception_block(512, 160, 112, 224, 24, 64, 64)
self.inception4c = inception_block(512, 128, 128, 256, 24, 64, 64)
self.inception4d = inception_block(512, 112, 144, 288, 32, 64, 64)
self.inception4e = inception_block(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.inception5a = inception_block(832, 256, 160, 320, 32, 128, 128)
self.inception5b = inception_block(832, 384, 192, 384, 48, 128, 128)
if aux_logits:
self.aux1 = inception_aux_block(512, num_classes, dropout=dropout_aux)
self.aux2 = inception_aux_block(528, num_classes, dropout=dropout_aux)
else:
self.aux1 = None # type: ignore[assignment]
self.aux2 = None # type: ignore[assignment]
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=dropout)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
torch.nn.init.trunc_normal_(m.weight, mean=0.0, std=0.01, a=-2, b=2)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _transform_input(self, x: Tensor) -> Tensor:
if self.transform_input:
x_ch0 = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_ch1 = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_ch2 = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat((x_ch0, x_ch1, x_ch2), 1)
return x
def _forward(self, x: Tensor) -> Tuple[Tensor, Optional[Tensor], Optional[Tensor]]:
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
aux1: Optional[Tensor] = None
if self.aux1 is not None:
if self.training:
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
aux2: Optional[Tensor] = None
if self.aux2 is not None:
if self.training:
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
return x, aux2, aux1
@torch.jit.unused
def eager_outputs(self, x: Tensor, aux2: Tensor, aux1: Optional[Tensor]) -> GoogLeNetOutputs:
if self.training and self.aux_logits:
return _GoogLeNetOutputs(x, aux2, aux1)
else:
return x # type: ignore[return-value]
def forward(self, x: Tensor) -> GoogLeNetOutputs:
x = self._transform_input(x)
x, aux1, aux2 = self._forward(x)
aux_defined = self.training and self.aux_logits
if torch.jit.is_scripting():
if not aux_defined:
warnings.warn("Scripted GoogleNet always returns GoogleNetOutputs Tuple")
return GoogLeNetOutputs(x, aux2, aux1)
else:
return self.eager_outputs(x, aux2, aux1)
class Inception(nn.Module):
def __init__(
self,
in_channels: int,
ch1x1: int,
ch3x3red: int,
ch3x3: int,
ch5x5red: int,
ch5x5: int,
pool_proj: int,
conv_block: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
if conv_block is None:
conv_block = BasicConv2d
# 1x1
self.branch1 = conv_block(in_channels, ch1x1, kernel_size=1)
# 3x3
self.branch2 = nn.Sequential(
conv_block(in_channels, ch3x3red, kernel_size=1), conv_block(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
# 5x5
self.branch3 = nn.Sequential(
conv_block(in_channels, ch5x5red, kernel_size=1),
# Here, kernel_size=3 instead of kernel_size=5 is a known bug.
# Please see https://github.com/pytorch/vision/issues/906 for details.
conv_block(ch5x5red, ch5x5, kernel_size=3, padding=1),
)
# pooling
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1, ceil_mode=True),
conv_block(in_channels, pool_proj, kernel_size=1),
)
def _forward(self, x: Tensor) -> List[Tensor]:
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return outputs
def forward(self, x: Tensor) -> Tensor:
outputs = self._forward(x)
return torch.cat(outputs, 1)
class InceptionAux(nn.Module):
def __init__(
self,
in_channels: int,
num_classes: int,
conv_block: Optional[Callable[..., nn.Module]] = None,
dropout: float = 0.7,
) -> None:
super().__init__()
if conv_block is None:
conv_block = BasicConv2d
self.conv = conv_block(in_channels, 128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x: Tensor) -> Tensor:
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = F.adaptive_avg_pool2d(x, (4, 4))
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
# N x 1024
x = self.dropout(x)
# N x 1024
x = self.fc2(x)
# N x 1000 (num_classes)
return x
class BasicConv2d(nn.Module):
def __init__(self, in_channels: int, out_channels: int, **kwargs: Any) -> None:
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x: Tensor) -> Tensor:
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
class GoogLeNet_Weights(WeightsEnum):
IMAGENET1K_V1 = Weights(
url="https://download.pytorch.org/models/googlenet-1378be20.pth",
transforms=partial(ImageClassification, crop_size=224),
meta={
"num_params": 6624904,
"min_size": (15, 15),
"categories": _IMAGENET_CATEGORIES,
"recipe": "https://github.com/pytorch/vision/tree/main/references/classification#googlenet",
"_metrics": {
"ImageNet-1K": {
"acc@1": 69.778,
"acc@5": 89.530,
}
},
"_ops": 1.498,
"_file_size": 49.731,
"_docs": """These weights are ported from the original paper.""",
},
)
DEFAULT = IMAGENET1K_V1
@register_model()
@handle_legacy_interface(weights=("pretrained", GoogLeNet_Weights.IMAGENET1K_V1))
def googlenet(*, weights: Optional[GoogLeNet_Weights] = None, progress: bool = True, **kwargs: Any) -> GoogLeNet:
"""GoogLeNet (Inception v1) model architecture from
`Going Deeper with Convolutions <http://arxiv.org/abs/1409.4842>`_.
Args:
weights (:class:`~torchvision.models.GoogLeNet_Weights`, optional): The
pretrained weights for the model. See
:class:`~torchvision.models.GoogLeNet_Weights` below for
more details, and possible values. By default, no pre-trained
weights are used.
progress (bool, optional): If True, displays a progress bar of the
download to stderr. Default is True.
**kwargs: parameters passed to the ``torchvision.models.GoogLeNet``
base class. Please refer to the `source code
<https://github.com/pytorch/vision/blob/main/torchvision/models/googlenet.py>`_
for more details about this class.
.. autoclass:: torchvision.models.GoogLeNet_Weights
:members:
"""
weights = GoogLeNet_Weights.verify(weights)
original_aux_logits = kwargs.get("aux_logits", False)
if weights is not None:
if "transform_input" not in kwargs:
_ovewrite_named_param(kwargs, "transform_input", True)
_ovewrite_named_param(kwargs, "aux_logits", True)
_ovewrite_named_param(kwargs, "init_weights", False)
_ovewrite_named_param(kwargs, "num_classes", len(weights.meta["categories"]))
model = GoogLeNet(**kwargs)
if weights is not None:
model.load_state_dict(weights.get_state_dict(progress=progress, check_hash=True))
if not original_aux_logits:
model.aux_logits = False
model.aux1 = None # type: ignore[assignment]
model.aux2 = None # type: ignore[assignment]
else:
warnings.warn(
"auxiliary heads in the pretrained googlenet model are NOT pretrained, so make sure to train them"
)
return model


GoogleNetv1训练代码及运行结果
关于os.walk的详细用法可看这篇博客
train_googlenet.py
# -*- coding: utf-8 -*-
import os
import numpy as np
import torch.nn as nn
import torch
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
import torchvision.models as models
from tools.my_dataset import NCFMDataSet
from tools.common_tools import get_googlenet
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if __name__ == "__main__":
# config
data_dir = os.path.join(BASE_DIR, "..", "..", "NCFM", "train")
path_state_dict = os.path.join(BASE_DIR, "..", "data", "googlenet-1378be20.pth")
# path_state_dict = False
num_classes = 8
MAX_EPOCH = 100
BATCH_SIZE = 64
LR = 0.001
log_interval = 1
val_interval = 1
start_epoch = -1
lr_decay_step = 1
# ============================ step 1/5 数据 ============================
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((256)), # (256, 256) 区别
transforms.CenterCrop(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
normalizes = transforms.Normalize(norm_mean, norm_std)
valid_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.TenCrop(224, vertical_flip=False),
transforms.Lambda(lambda crops: torch.stack([normalizes(transforms.ToTensor()(crop)) for crop in crops])),
])
# 构建MyDataset实例
train_data = NCFMDataSet(data_dir=data_dir, mode="train", transform=train_transform)
valid_data = NCFMDataSet(data_dir=data_dir, mode="valid", transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=4)
# ============================ step 2/5 模型 ============================
googlenet_model = get_googlenet(path_state_dict, device, False)
num_ftrs = googlenet_model.fc.in_features
googlenet_model.fc = nn.Linear(num_ftrs, num_classes)
num_ftrs_1 = googlenet_model.aux1.fc2.in_features
googlenet_model.aux1.fc2 = nn.Linear(num_ftrs_1, num_classes)
num_ftrs_2 = googlenet_model.aux2.fc2.in_features
googlenet_model.aux2.fc2 = nn.Linear(num_ftrs_2, num_classes)
googlenet_model.to(device)
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss()
# ============================ step 4/5 优化器 ============================
# 冻结卷积层
flag = 0
# flag = 1
if flag:
fc_params_id = list(map(id, googlenet_model.classifier.parameters())) # 返回的是parameters的 内存地址
base_params = filter(lambda p: id(p) not in fc_params_id, googlenet_model.parameters())
optimizer = optim.SGD([
{'params': base_params, 'lr': LR * 0.1}, # 0
{'params': googlenet_model.classifier.parameters(), 'lr': LR}], momentum=0.9)
else:
optimizer = optim.SGD(googlenet_model.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_decay_step, gamma=0.1) # 设置学习率下降策略
# scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(patience=5)
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(start_epoch + 1, MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
googlenet_model.train()
for i, data in enumerate(train_loader):
# 1. forward
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = googlenet_model(inputs)
# 2. backward
optimizer.zero_grad()
loss_main, aug_loss1, aug_loss2 = criterion(outputs[0], labels), criterion(outputs[1], labels), \
criterion(outputs[2], labels)
loss = loss_main + (0.3 * aug_loss1) + (0.3 * aug_loss2)
loss.backward()
# 3. update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs[0].data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().cpu().sum().numpy()
# 打印训练信息
loss_mean += loss_main.item()
train_curve.append(loss_main.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss_main:{:.4f} Acc:{:.2%} lr:{}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total, scheduler.get_last_lr()))
loss_mean = 0.
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
googlenet_model.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
bs, ncrops, c, h, w = inputs.size()
outputs = googlenet_model(inputs.view(-1, c, h, w))
outputs_avg = outputs.view(bs, ncrops, -1).mean(1)
loss = criterion(outputs_avg, labels)
_, predicted = torch.max(outputs_avg.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().cpu().sum().numpy()
loss_val += loss.item()
loss_val_mean = loss_val/len(valid_loader)
valid_curve.append(loss_val_mean)
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val_mean, correct_val / total_val))
googlenet_model.train()
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
my_dataset.py
# -*- coding: utf-8 -*-
import numpy as np
import torch
import os
import random
from PIL import Image
from torch.utils.data import Dataset
random.seed(1)
class_name = ["ALB", "BET", "DOL", "LAG", "NoF", "OTHER", "SHARK", "YFT"]
class NCFMDataSet(Dataset):
def __init__(self, data_dir, mode="train", split_n=0.9, rng_seed=620, transform=None):
"""
鱼类分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.mode = mode
self.data_dir = data_dir
self.rng_seed = rng_seed
self.split_n = split_n
self.data_info = self._get_img_info() # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
if len(self.data_info) == 0:
raise Exception("\ndata_dir:{} is a empty dir! Please checkout your path to images!".format(self.data_dir))
return len(self.data_info)
def _get_img_info(self):
img_path = []
for root, dirs, files in os.walk(self.data_dir):
for name in files:
if name.endswith(".jpg"):
img_path.append(os.path.join(root, name))
random.seed(self.rng_seed)
random.shuffle(img_path)
img_labels = [class_name.index(os.path.basename(os.path.dirname(p))) for p in img_path]
split_idx = int(len(img_labels) * self.split_n)
# split_idx = int(100 * self.split_n)
if self.mode == "train":
img_set = img_path[:split_idx] # 数据集90%训练
label_set = img_labels[:split_idx]
elif self.mode == "valid":
img_set = img_path[split_idx:]
label_set = img_labels[split_idx:]
else:
raise Exception("self.mode 无法识别,仅支持(train, valid)")
path_img_set = [os.path.join(self.data_dir, n) for n in img_set]
data_info = [(n, l) for n, l in zip(path_img_set, label_set)]
return data_info





之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!















 2392
2392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









