







Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
目录
2.4.2 专用描述(Specialized Captions)
6.1 引导与步数蒸馏(CFG + Step Distillation)
1. 简介
Seedream 2.0 是一款中英双语的文本生成图像基础模型,旨在解决当前主流模型在审美偏差、文本渲染能力弱、以及中国文化理解不足等问题。
该模型整合自研双语大模型作为文本编码器,融合 ByT5 字符级建模及多阶段优化策略(包括监督微调 SFT 和人类反馈强化学习 RLHF),展现出在中英文提示理解、美学质量、结构正确性和文本渲染方面的 SOTA 性能。
2. 数据预处理
2.1 数据组成
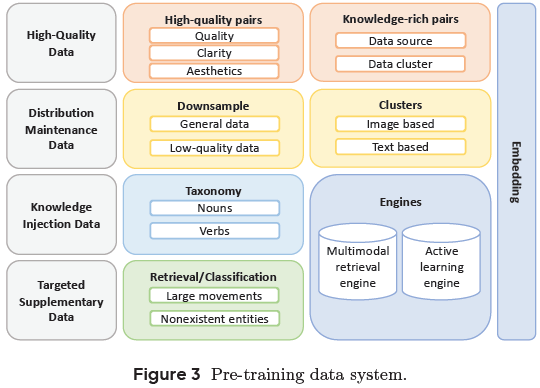
Seedream 2.0 的训练数据由四类组成:
-
高质量数据(High-Quality Data):具有高图像清晰度、美学质量和丰富语义信息的数据,来自图像与文本的高质量对,通过视觉美感和语义知识评估筛选而成。
-
分布维护数据(Distribution Maintenance Data):用于保持原始数据的多样性,通过数据源下采样与语义聚类抽样控制数据比例,避免过度偏向某一类语义或风格。
-
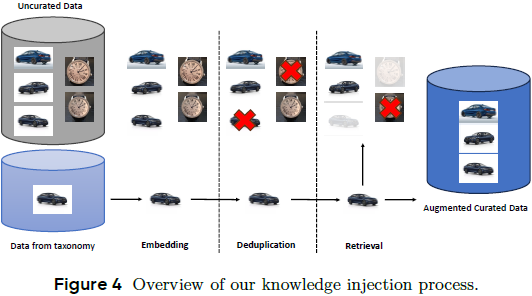
知识注入数据(Knowledge Injection Data):通过多模态检索引擎和人工收集,特别强化中国本土内容(如动植物、建筑、风俗),提升模型的文化适应能力。
-
目标补充数据(Targeted Supplementary Data):重点补充模型薄弱区域(如复杂动作、反事实设定等),通过主动学习挑选 “难例” 样本以提升泛化能力。
2.2 数据清洗流程
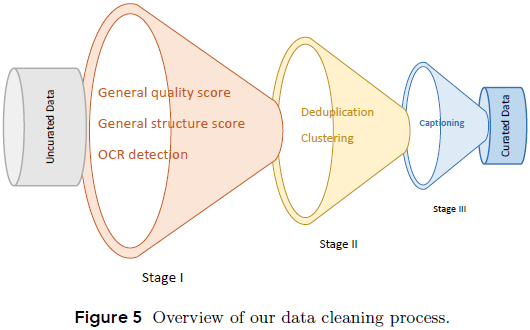
采用三阶段的数据清洗策略(如图 5):
-
第一阶段:评估图像清晰度(如模糊、无意义内容)、结构合理性(如水印、贴纸、文字遮挡)及 OCR 检测,过滤低质量图像。
-
第二阶段:应用美学打分、特征嵌入提取与语义聚类,进一步识别和分层图像内容,进行语义标签化以便后续训练数据均衡。
-
第三阶段:对筛选后的数据进行重新标注或改写,特别是针对图像语义丰富的内容提供多视角描述,以增强描述信息密度。
2.3 主动学习引擎
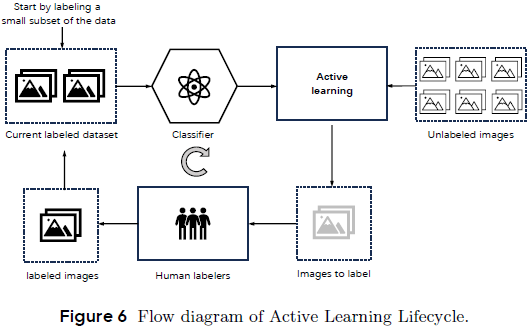
为进一步提升数据标注效率,Seedream 构建了一个主动学习系统:
-
初期手动标注小部分图像
-
使用已标注数据训练分类器
-
持续迭代地选择 “不确定” 图像供人类继续标注
-
最终实现自动化与人工标注的高效协作循环
2.4 图像标注
为训练模型具备丰富语义理解能力,采用以下策略生成图像描述:
2.4.1 通用描述(Generic Captions)
-
提供中英双语的短描述和长描述
-
短描述覆盖图像主要内容(如物体、场景)
-
长描述融合推理、想象、风格细节等
2.4.2 专用描述(Specialized Captions)
针对特定任务生成风格化标签:
-
艺术描述:专注风格、色彩、构图、光影等艺术元素
-
文本描述:专注图像中文字内容
-
超现实描述:描述幻想元素、违常组合、拟人化内容等

图 7 提供了丰富的中英文实例,包括彩色变色龙、城市夜景、蜂蜜蛋糕海报、厨房、书法牌匾、酒瓶包装、人物图像等类型。
2.5 文本渲染数据
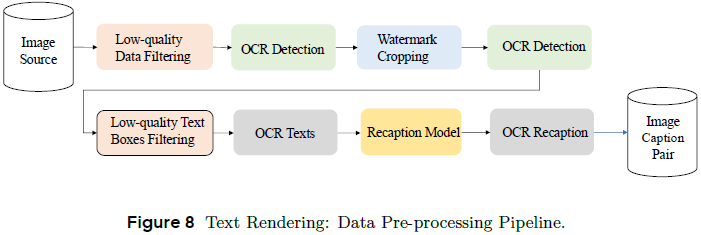
为增强模型的文字渲染能力(生成图像中文本内容的能力),Seedream 构建了大规模文本渲染训练集:
-
采用 OCR 提取内嵌文字区域,并剪裁水印
-
去除模糊与不相关文本框,保留清晰有效区域
-
利用重标注模型生成高质量图文对
-
重点处理图中文字的字体、颜色、大小与排版特征,以供字符级建模器使用
3. 模型预训练
3.1 Diffusion Transformer
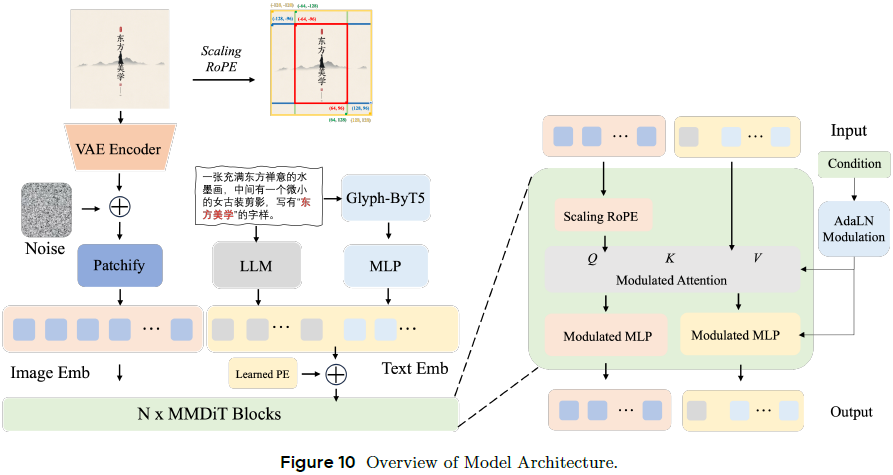
Seedream 2.0 的图像生成主干是基于 MMDiT 改进设计的 Diffusion Transformer(DiT)架构:
输入图像编码:通过自研的变分自编码器(VAE)将图像编码为潜变量 x,再分割为多个 patch,映射为图像 token。
图文联合输入:图像 token 与文本编码器输出的文本 token 拼接后输入 DiT 层,进行统一建模。
模块结构:
-
每层仅含一组自注意力机制,同时处理图像与文本 token。
-
图像与文本路径分别采用独立 MLP 结构。
-
使用自适应 LayerNorm 和 QK-Norm 机制提高训练稳定性。
-
采用 Fully Sharded Data Parallel(FSDP)实现分布式训练。
位置编码设计:
-
文本 token 使用可学习位置嵌入;
-
图像 token 使用 2D Rotary Positional Embedding(RoPE);
-
提出 Scaling RoPE:通过为不同分辨率配置比例因子,使图像中心区域的 patch 在不同分辨率下拥有一致位置 ID,从而增强模型在未见分辨率下的泛化能力(图10)。
3.2 文本编码器
为提升模型的中英双语理解与生成能力,Seedream 2.0 采用自研的 decoder-only 大语言模型(LLM)作为文本编码器:
-
相比传统 CLIP 或 T5,decoder-only LLM 在复杂文本理解与多语言处理方面表现更优,尤其适合处理中文。
-
为解决 decoder-only 架构与 diffusion 模型中 embedding 分布不匹配的问题,Seedream 采用图文对数据对 LLM 进行精调,从而确保其生成的文本特征与图像特征在联合空间中对齐。
编码器具备以下特性:
-
强大的长文本理解能力
-
精确捕捉中文风格和专业术语
-
通过大量原始中英文数据学习本土知识,实现高质量语义表达与文化呈现
3.3 字符级文本编码器
为实现复杂语言(特别是中文)文本的精细渲染,Seedream 2.0 引入 ByT5 模型构建字符级编码器,并与 LLM 编码器联合工作:
文本渲染问题:单独使用 ByT5 编码渲染文本时,会出现字符重复与排布混乱问题,尤其是长文本。
解决方案:
-
将渲染文本同时输入 LLM 和 ByT5 编码器;
-
通过 MLP 层将 ByT5 的字符特征映射到与 LLM 特征一致的空间;
-
拼接后输入 DiT 块,实现一致性训练。
渲染特征建模:
-
利用 Re-caption 模型提取字体、颜色、位置等视觉属性,构建完整文本渲染特征;
-
相比如 TextDiffuser-2 等使用预设文本框布局的方法,Seedream 实现了端到端训练,使模型能直接从数据中学习文本排版与样式表达。
4. 模型后训练
4.1 持续训练
数据部分:
-
自动筛选的高质量数据:基于自研 IQA 模型(图像质量评估),从预训练数据中挑选出清晰、结构良好、无水印的图像。
-
人工精选数据集:包括摄影、设计、艺术等垂类场景图像,审美质量高,人工精挑细选构建百万级别精致样本集。
训练策略:
-
使用 VMix 方法,将图像按 “颜色、光照、纹理、构图” 四个维度进行标签化,作为条件引导模型训练。
-
联合训练自动高质量数据与人工审美样本,保持多样性与鲁棒性,避免模型过拟合小样本。
4.2 监督微调(SFT)
数据构建:
-
人工构建精美图像集,并配合多轮人工修订的 caption 模型生成描述,涵盖艺术风格和细节特征。
-
每张图像附带 “风格标签 + 美学标签(同 VMix)”,全面覆盖主流视觉风格。
训练策略:
-
同时加入生成模型的 “低质量样本” 作为负样本,提升模型识别自然图像的能力。
-
引入数据重采样算法,平衡艺术表现与图文对齐能力,确保美感增强不以损害语义一致性为代价。
4.3 人类反馈对齐(RLHF)
此模块是 Seedream 的核心创新之一,通过强化学习引导模型向用户偏好靠拢。
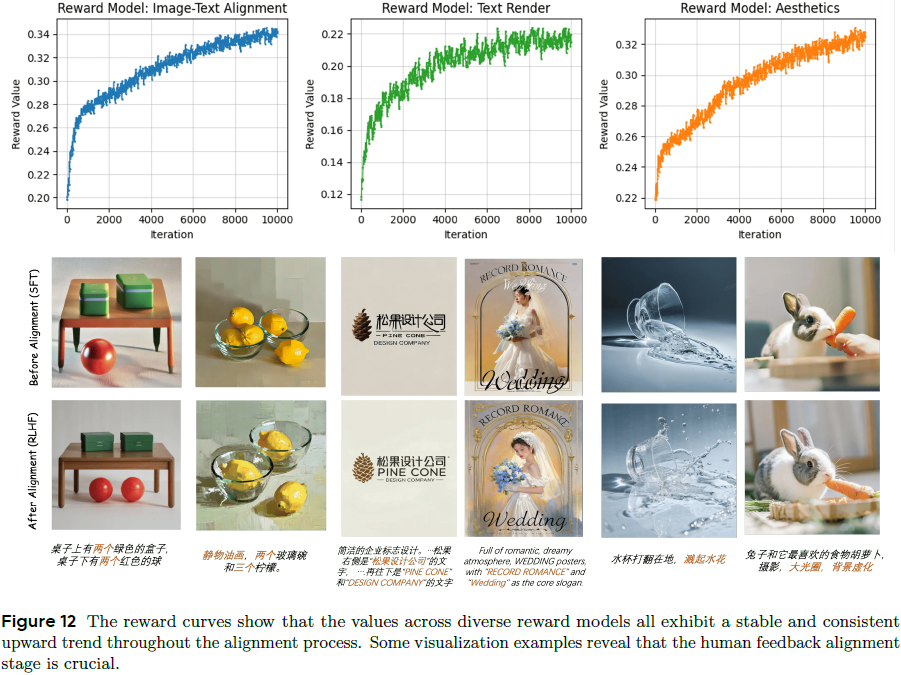
偏好数据构建:
-
Prompt 系统:构建百万级提示语料库,包含用户实际输入与训练描述,并进行清洗筛选。
-
RM 数据采集:从多个模型版本中采样生成图像,用人工标注形成跨模型/版本的数据集。
-
注释规则:融合图文匹配、美学、结构、文本渲染等维度,统一评分标准,实现多维反馈。
奖励模型(RM)设计:
-
使用支持中英文的 CLIP 模型作为基础架构,训练三类奖励模型:
-
图文对齐 RM
-
美学 RM
-
文本渲染 RM(按需激活)
-
-
奖励采用排名损失训练,避免使用额外的 Head 网络。
强化学习流程:
-
参考 REFL 框架,融合 DPO、DDPO 等方法,直接优化奖励得分。
-
精细控制学习率、噪声步长、EMA 权重等,保持训练稳定。
-
采用 多轮迭代机制:
-
基于当前 RM 优化模型;
-
新模型生成图像并重新标注;
-
更新 RM 并再次优化模型;
-
不断循环迭代,突破性能上限。
-
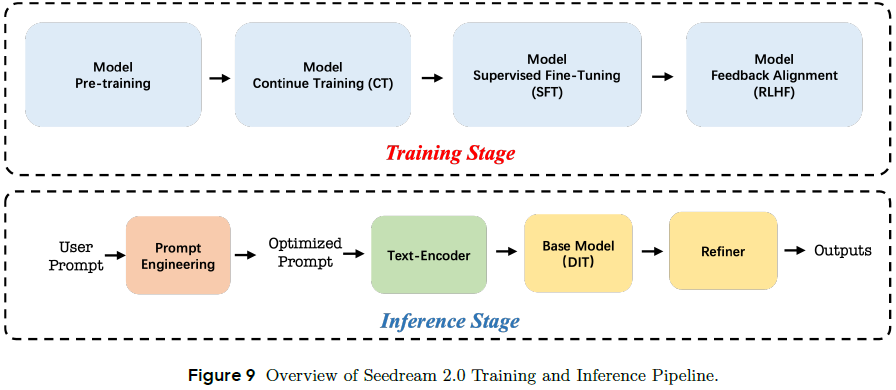
4.4 Prompt 工程(PE)
为解决用户提示过于简短、信息不足问题,Seedream 训练内置 LLM,自动扩展提示词。
微调阶段:
-
构建提示词对:
-
从用户 prompt 出发,人工修改并选出生成效果最好的版本作为参考 prompt。
-
反向构造,即从复杂描述中剥离出 “简化用户 prompt”。
-
-
微调 LLM,使其学会从 “简单提示” 生成 “高质量提示”。
RLHF 阶段:
-
使用当前 PE 模型生成多个重写版本;
-
将这些 prompt 输入 Diffusion 模型生成图像;
-
选择优/劣配对进行偏好打分;
-
使用 SimPO 优化方法训练,使输出提示更贴合用户偏好。
效果提升:
-
美学提升:+30%
-
图文对齐:+5%
-
多样性大幅增强(生成更具变化性的图像)


4.5 Refiner 模型
基础模型输出分辨率为 512 × 512,Refiner 负责将其提升到 1024 × 1024,同时增强细节质量和结构一致性。
分辨率训练阶段:
-
使用 CT 数据集中的高分辨率图像(大于 1024)进行训练;
-
将大图缩放至 1024,保持长宽比;
-
构建专门的分辨率精修模型。
纹理 RLHF 阶段:
-
手动采集高纹理图像样本;
-
降质生成低质量图像并构造训练对;
-
训练纹理奖励模型(Texture RM);
-
通过 RLHF 优化 Refiner 生成细节丰富、纹理自然的高清图像。
5. 指令图像编辑对齐
5.1 初步设置
Seedream 将其 Diffusion 架构延伸为图像编辑系统 SeedEditV1.0,主要依托三个关键创新:
-
数据构建:结合 InstructPix2Pix 与 Jedi 等方法生成编辑数据,涵盖刚性与非刚性(rigid and non-rigid)修改类型。
-
编码架构:采用 Diffusion 模型作为图像编码器(不同于其他方法如 IP-Adaptor 使用 CLIP 或 DINO 编码器),确保生成特征与理解特征在相同潜空间中。
-
训练策略:采用迭代优化机制,增强图像与文本指令的融合表达,使编辑后图像具备更强的语义一致性与构图自然度。
结果表明,SeedEdit 在保持原图风格与语义一致性的前提下,生成了高质量编辑图像,在学术与商业系统评估中均超越现有方法。
5.2 人脸 ID 保留增强
SeedEditV1.0 在处理真实人脸图像编辑时,存在 ID 丢失问题,尤其是面部区域较小或扩散模型的文本条件偏移过大。为此,新增以下优化策略:
多专家数据融合(Multi-Expert Data Fusion)
-
引入两类真实 ID 数据集:
-
内部面部专家生成数据(如 ID/IP 引导模型、背景替换模型)
-
多环境、不同光照下的人像照片集
-
-
按照 Prompt 前缀有条件地融合这些数据,以维持原始分布与编辑特性。
人脸感知损失(Face-Aware Loss)
-
对于人脸保持较好的图像对,引入额外的感知损失,采用人脸相似度模型(如 AdaFace)计算差异。
-
在训练中融合原有 Diffusion Loss 与 Face Loss,有效提升人脸特征保真度。
数据优化
-
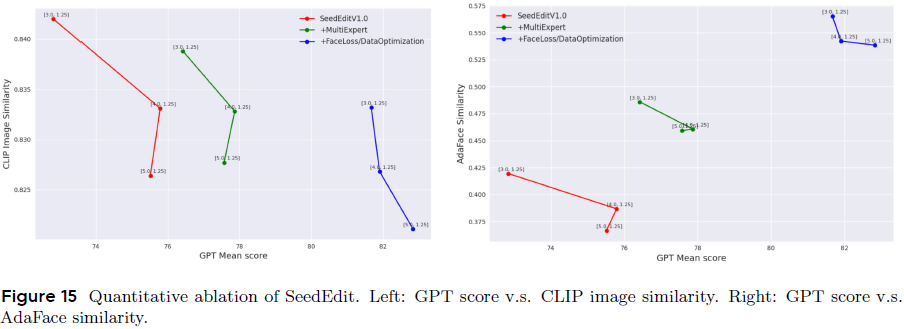
提升训练数据质量,强化过滤机制与采样策略,构建多样性强的编辑验证集(160 张图,含真实与合成图像)。
-
Ablation 实验(图15)表明上述改进显著提升了 ID 保留效果。

该编辑模块可实现如 “更换背景至纽约天际线” 或 “将人物头发变为蓝紫色短发” 等操作,且在保持构图一致性与局部精修上优于传统方法(图16)。
6. 模型加速
为提升推理效率,Seedream 2.0 在两方面进行了优化:
6.1 引导与步数蒸馏(CFG + Step Distillation)
问题:传统 Classifier-Free Guidance(CFG)每步需两次推理,效率低。
解决:引入“引导嵌入+ 轨迹分段一致性蒸馏(Trajectory Segmented Consistency Distillation,TSCD)”方法,分阶段压缩推理步数(从 16→1 步),保持生成质量同时显著加速。
6.2 模型量化
对核心算子(Attention、GEMM)进行融合优化,提升运行效率。
采用混合比特量化(不同层不同精度)+ 轻量量化微调(几小时完成),降低内存需求,保持性能稳定。
7. 模型性能
7.1 人工评估
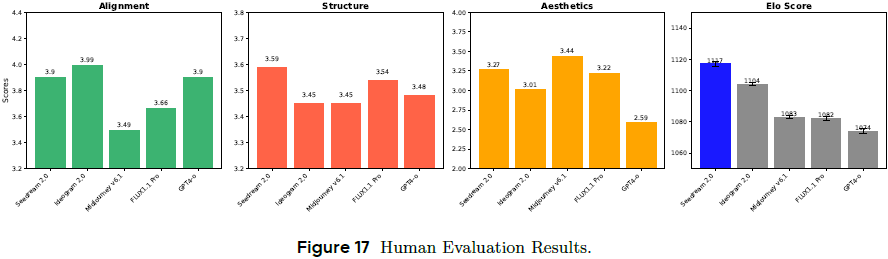
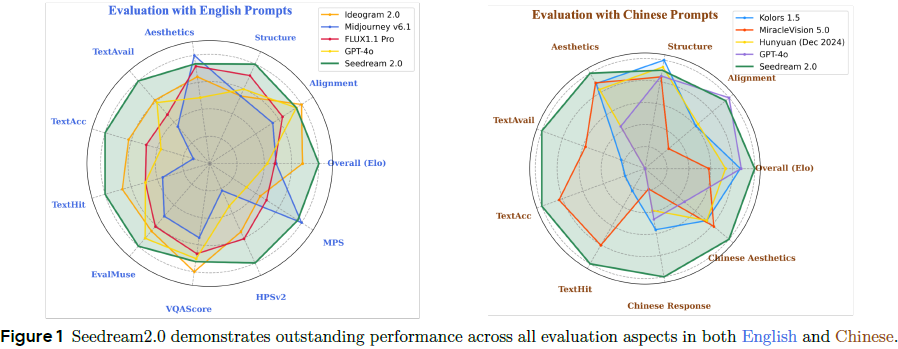
使用 Bench-240(240条中英文 prompt)进行专家打分与公众偏好投票。
Seedream 在 图文对齐、结构、审美质量 均为第一或第二。
ELO 总分排名全场最高,综合表现最优,超越 GPT-4o、Midjourney v6.1、Ideogram 2.0 等模型。
7.2 自动评估
7.2.1 图文对齐
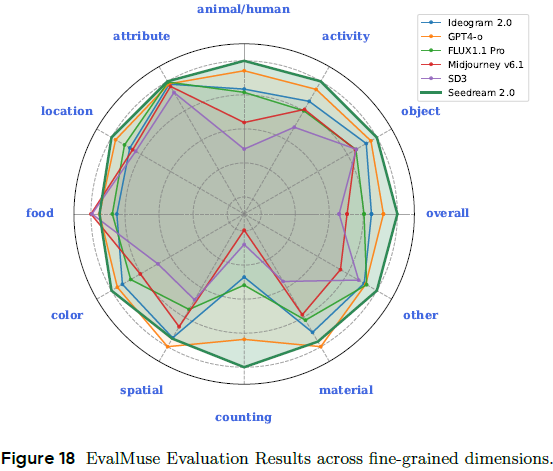
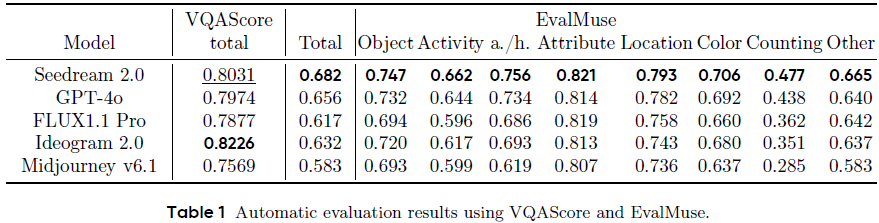
使用 EvalMuse 和 VQAScore:
-
Seedream 在计数、动作、物体等维度精度领先;
-
VQAScore 中总分排名第二,仅次于 Ideogram。
7.2.2 图像质量
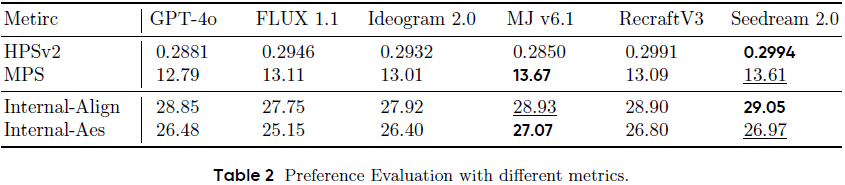
使用 HPSv2、MPS 等指标:
-
Seedream 在 HPSv2 得分第一;
-
MPS 得分次于 Midjourney,但领先其他模型;
-
内部 Align/Aesthetic 得分稳定高。
7.3 文本渲染
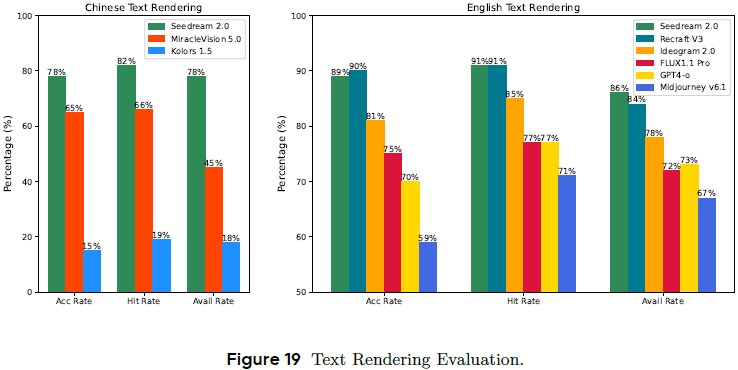
在 360 条中英文本渲染任务中评估:
-
中文准确率 78%,命中率 82%,明显领先 Kolors、MiracleVision;(定义见原论文)
-
英文表现亦超越 Recraft、Midjourney、GPT-4o 等;
-
支持复杂布局、字体风格、诗句、成语等文本生成。
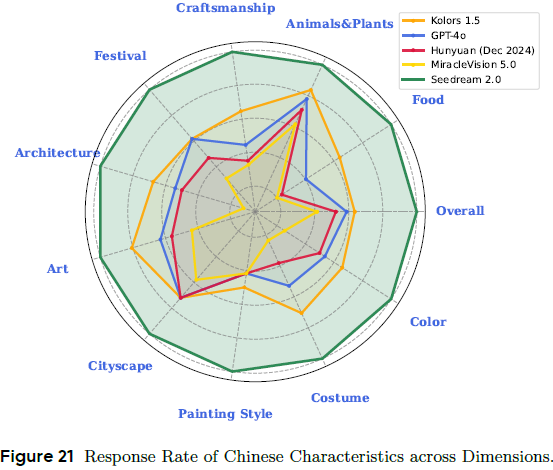
7.4 中国文化表达
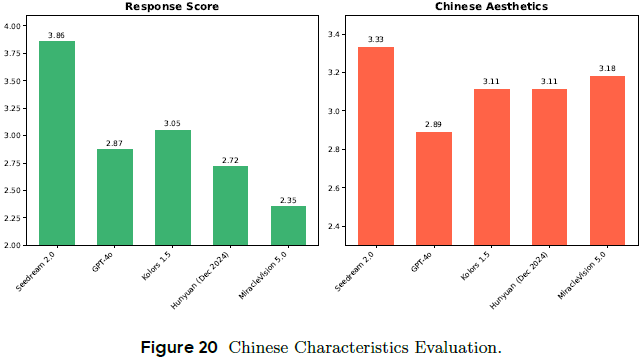
在 350 条涵盖传统服饰、建筑、饮食、技法等 prompt 上评估:
-
Seedream 得分 3.86,显著领先 GPT-4o(2.87)、Kolors(3.05)等模型;
-
能细腻表现唐宋元明清等历史风格与语境。

8. 结论
Seedream 2.0 凭借自研双语 LLM 和高质量多模态数据支持,在中英文文本到图像任务中展现出领先性能,尤其擅长文本渲染与中国文化表达,具备广阔应用潜力。
论文地址:https://arxiv.org/abs/2503.07703
项目页面:https://team.doubao.com/tech/seedream
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群

















 476
476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









