







Parameter-Efficient Fine-Tuning for Pre-Trained Vision Models: A Survey
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
大规模预训练视觉模型(pre-trained vision models,PVMs)展现出在各种下游视觉任务中的强大适应性潜力。然而,随着最先进的 PVMs 的参数增长到数十亿甚至数万亿,由于高计算和存储需求,标准的完全微调范式变得难以持续。作为回应,研究人员正在探索参数高效微调(parameter-efficient finetuning,PEFT),旨在通过最小化参数修改来超越完全微调的性能。这份调查提供了对视觉 PEFT 的全面概述和未来方向,系统性地回顾了最新的进展。首先,我们提供了 PEFT 的正式定义,并讨论了模型预训练方法。然后,我们将现有方法分类为三类:基于添加(addition-based)的方法,基于分部(partial-based)的方法和基于统一(unified-based)的方法。最后,我们介绍了常用的数据集和应用,并提出潜在的未来研究挑战。
资源集合:https://github.com/synbol/Awesome-Parameter-Efficient-Transfer-Learning

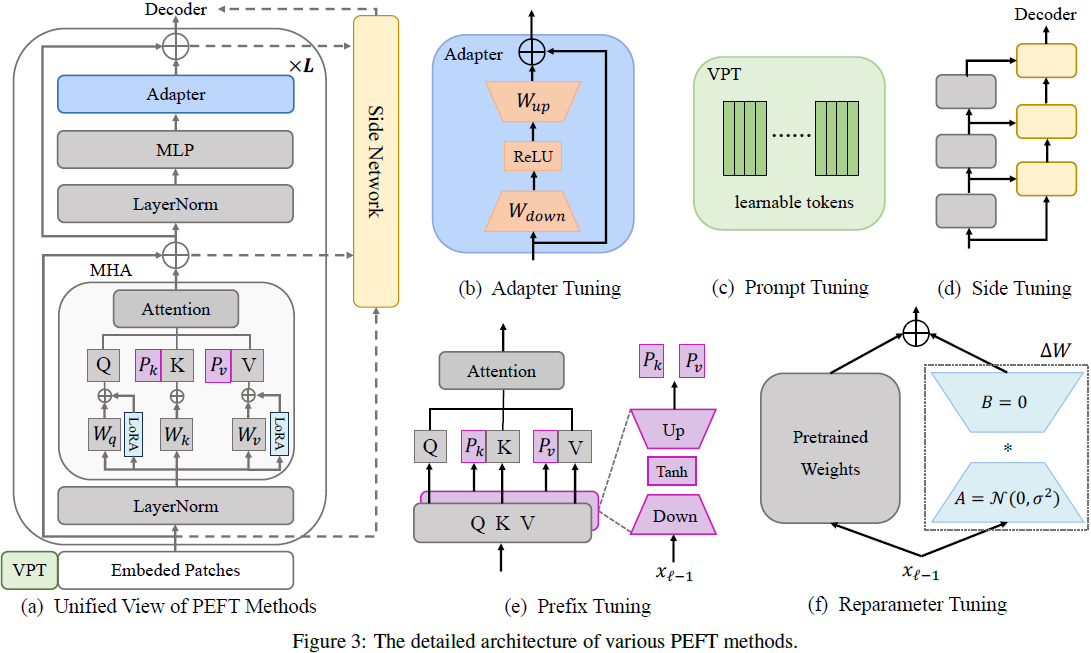
2. 基础
定义1.(参数高效微调)。给定一个由 θ 参数化的预训练模型 M,以及一个下游任务
![]()
其中 (xi, yi) 充当任务 D 的地面真实输入-输出对,参数高效微调的目标是使 θ 适应任务 D,其中引入了特定任务的参数增量 Δθ,满足 |Δθ| ≪ |θ|。通过在任务 D 上优化损失 L 来找到最优参数:
![]()
3. 方法
3.1 基于添加的方法
基于添加的方法(addition-based)涉及将额外的可训练模块或参数合并到原始的 PVMs 中,以学习任务特定的信息。本小节讨论了基于添加的方法的四个主要分支:适配器微调、提示微调、前缀微调和侧向微调。
适配器微调(Adapter Tuning)。该方法将小型神经模块,称为适配器(adapter),集成到 Transformer 层中。在适应过程中,只有这些适配器被微调。
计算机视觉领域中的适配器微调方法可以大致分为两类:1)为各种视觉任务(例如图像分类、视频理解等)设计特定的适配器架构,以及2)采用先进的优化技术来减少适配器中的可训练参数。
提示微调(Prompt Tuning)。视觉提示微调提供了一种替代方法将可学习模块注入到 Transformer 模型。在这种方法中,原始输入,无论是图像嵌入还是实际图像,都与视觉提示打包。这些提示由额外的可训练参数或扰动组成。它们是独特的可适应参数,并且可以根据特定任务和训练数据进行优化。主要目标是通过任务特定的提示将输入分布与原始预训练数据对齐。
视觉提示微调的研究通常分为两大类:1)向图像嵌入空间注入一组可学习参数,以及2)在原始输入图像的边界周围注入可学习的扰动。
前缀微调(Prefix Tuning)。受提示微调成功的启发,前缀微调在 PVM 的多头注意力(MHA)模块中引入了可学习的前缀矩阵。它涉及将两个随机初始化的前缀矩阵 Pk,Pv 添加到 MHA 中的 key 和 value 之前,使得注意力计算为:
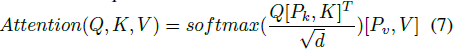
侧向微调(Side Tuning)。与先前的 PEFT 方法不同,通常涉及在 PVM 内部插入额外的模块或参数,侧向微调使用侧向网络,这是一个较小且独立的网络,与 PVM 并行操作,如图 3(d) 所示。
先前的侧向微调方法集中在参数效率上,重点关注如何设计侧向网络。除了优先考虑参数效率外,随后的研究发现,通过创新设计,侧向微调还可以提高 GPU 内存的效率。
3.2 基于分部的方法
基于部分的方法(partial-based)集中于在适应过程中仅更新一小部分固有参数,同时保持大多数模型参数不变。这些方法不试图改变模型的内部结构。本节将涵盖两种策略:规范微调和重新参数调整。
规范微调(Specification Tuning)。规范微调是一种直接修改 PVM 中特定参数子集的高效方法,例如 bias 和 LayerNorm,这对下游任务至关重要。该方法集中于重要参数,同时舍弃那些被认为不太相关的参数。尽管概念简单,但已被证明非常有效。
重新参数微调(Reparameter Tuning)。重新参数调整方法在训练阶段也引入了新的可学习参数,而这些参数可以通过重新参数化在推断阶段集成到原始 PVMs 中。LoRA 是一个显著的例子,其中可训练的低秩矩阵被注入到 Transformer 层中,以近似对权重的更新。
3.3 基于统一的微调
基于统一的方法(unified-based)提供了一个统一的框架,将各种微调方法整合到一个单一、协调的体系结构中。这种方法简化了流程,提高了微调的整体效率和效果。例如,NOAH 将适配器、LoRA 和 VPT 集成到每个 Transformer 块中,并采用神经架构搜索(NAS)来确定特定下游任务的最佳设计。这种方法通过结合多种技术,代表了优化微调的综合方法。
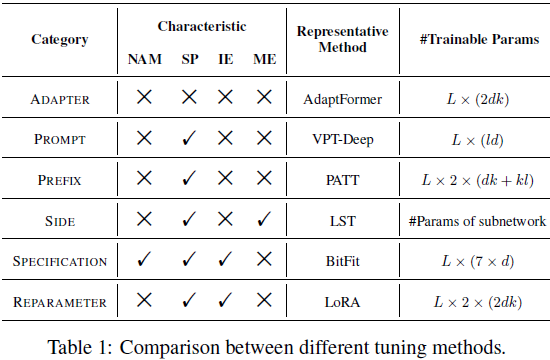
3.4 讨论
特征分析。我们总结了所有 PEFT 方法的特征,如表 1 所示。这些方法在 4 个方面进行了比较。
- 无额外模块(No-Additional Modules,NAM):规范微调是唯一不引入新模块的方法,而其他方法或多或少地引入了额外的模块或参数。
- 结构保持(Structure Preserving,SP):适配器微调改变了 PVM 的结构。相反,提示微调、前缀微调、侧向微调和重新参数微调保持了原始 PVM 的结构,同时引入了新模块。规范微调直接优化了 PVM 的一部分参数,因此不改变模型结构。
- 推断高效(Inference Efficient,IE):额外的模块通常会增加推断延迟,而重新参数调整是一个例外,由于其缓解重新参数化技术。
- 内存高效(Memory Efficient,ME):侧向微调独特地实现了内存高效,因为其梯度反向传播不涉及 PVM。
总体而言,每种 PEFT 方法都具有独特的优势和局限性,没有完全完美的 PEFT 方法。
参数分析。为了准确计算可训练参数的数量,我们选择了每个分类法的一个具体代表性工作,如表 1 所示。
- 观察到 BitFit 具有最少的可训练参数,因为它只更新 PVM 中的 bias 项。
- 相比之下,由于其并行子网络,LST 具有最多的可训练参数,但它可以实现内存高效。将来优化子网络结构可能至关重要。
- 此外,AdaptFormer、PATT 和 LoRA 具有相似的参数数量,因为它们都在每个Transformer 层中注入了相似的结构。
- VPT-Deep 的参数计数略高于 BitFit。
在实际应用中,与完全微调相比,这些方法仅占可训练参数的 0.05% 到 10%,但它们在下游任务上实现了可比较甚至更好的性能。
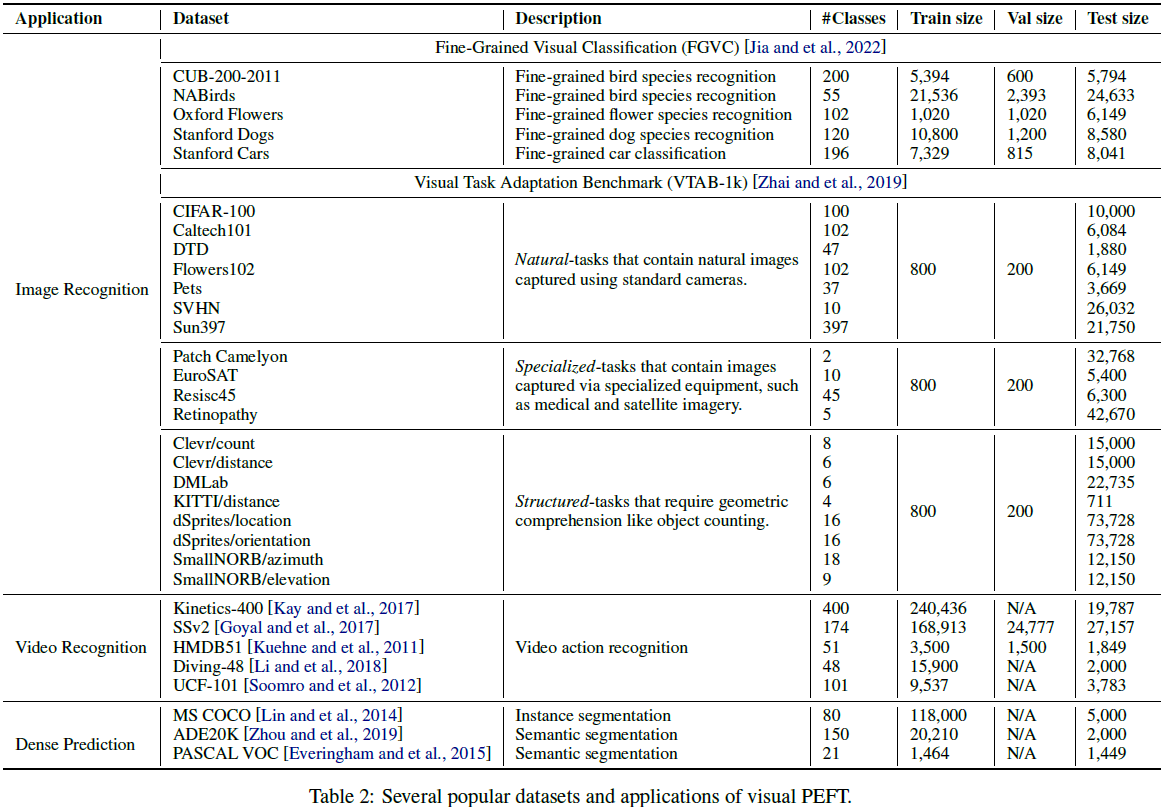
4. 数据集和应用
5. 未来研究挑战
视觉 PEFT 方法的可解释性。尽管取得了显著的进展,但视觉 PEFT 方法有效性的基本原因仍然不清楚,特别是在视觉提示的可解释性方面。在自然语言处理(NLP)领域,我们可以解释提示为更好、更直观的描述。而在计算机视觉领域,主要的挑战是视觉提示被学习为无序的基于标记的提示,这很难转化为可理解的格式。适配器和前缀等其他微调技术在可解释性方面也面临挑战。这些方法努力减少调整大模型以适应特定任务所需的参数数量。因此,提高 PEFT 的可解释性是未来研究的一个关键领域。
面向生成和多模态模型的 PEFT。在计算机视觉领域,大多数 PEFT 方法专为判别性任务定制,例如图像分类和视频动作识别。然而,在生成任务中探索它们的应用非常有前景。借助适配器和提示,研究人员已经为预训练生成模型 [Xie等,2023] 开发了几种 PEFT 方法,尤其是稳定的扩散模型。尽管如此,这些模型仍有很大的深度探索空间。另一方面,大型多模态模型通常需要比单模态模型更多的计算和内存资源。因此,在多模态领域研究 PEFT 方法也是可取的。此外,PEFT 方法可以促进跨模态对齐,从而在下游多模态任务中取得显著的改进。因此,对这两个领域的进一步探索代表着未来研究的一个有前途的方向。
构建视觉 PEFT 库。尽管已经提出了大量用于视觉领域的 PEFT 方法,但它们的直接应用或比较并不常规。相比之下,自然语言处理领域已经发展了综合的库,如 PEFT 库(网页:https://github.com/huggingface/peft),它整合了各种 PEFT 方法和大型语言模型(LLMs),以促进它们在下游任务中的应用。因此,有望开发一个用于视觉领域甚至整合多模态领域的库,这有助于推动 PEFT 的发展。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









