






论文和 代码放在此处,方便感兴趣者快速获取。
写在前面
- 最近随着大语言模型的火热发展,Prompt技术在LLMs中的应用也受到了大量研究学者、工程技术人员的关注,但目前在NLP领域中似乎应用的更多一些。但在当前的浪潮下,视觉大模型的崛起也是必然趋势,那么将Prompt技术应用于视觉领域进行微调,可能也会是一个让视觉大模型在特定下游任务上取得良好表现的好思路。
- Visual Prompt Tuning 这篇论文其实是2022年的作品了,所以应该这方面很可能还有更多研究投入,本人也在逐渐学习中,因此这篇文章可能会持续更新。
- Visual Prompt Tuning(视觉提示微调技术,下简称VPT)。
一图速读论文框架

- 论文贡献:
- 提出了Transformer架构下视觉大模型的两种微调方式: VPT Deep(上图(a))和VPT Shallow(上图(b))。
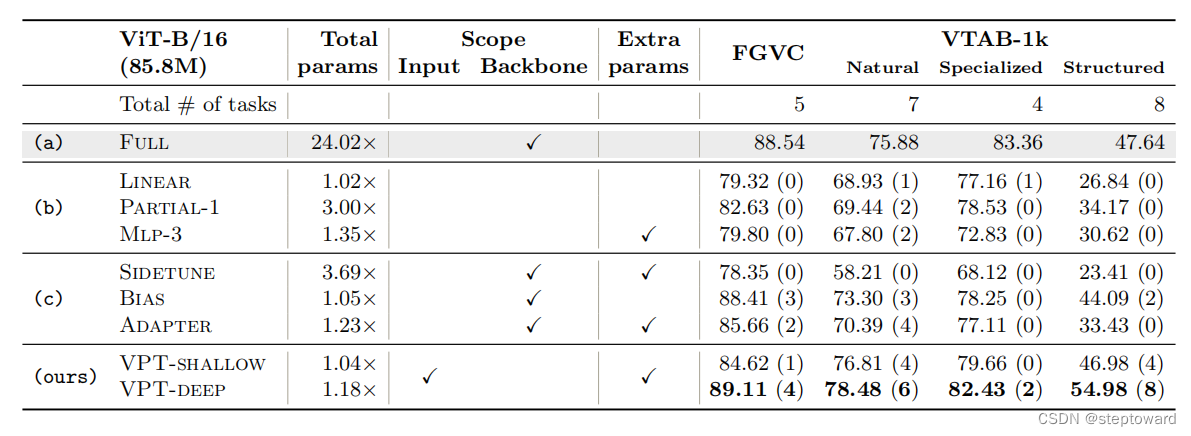
- 对FGVC和VTAB的共计24个下游任务做了VPT与其他7种微调方法的对比实验,VPT Deep在20个下游任务上的average accuracy 都优于其他微调方法,包括全参数微调,这个现象是在当时prompt技术在NLP任务中不曾表现出来过的。
- 在少量训练数据的情况下,VPT也能表现优异
- VPT可以适配ViT,Swin, 和MocoV3等Backbone模型做下游任务的微调。
微调方法对比实验
-
对比了其他哪些微调方法?
类型 方法简介 全参数微调 backbone+classifier head 分类头微调 只微调线性层 – partical-k – MLP-k 更新子集 Sidetune – Bias 引入新的可学习参数 Adapter
- 全参数微调方法:更新backbone和分类头的所有参数。
- 只微调分类头的方法:
即将预训练的骨干网络视为特征提取器,在微调过程中保持其权重不变,只更新分类头的参数。具体有以下方法:- 线性层:只使用线性层作为分类头。
- 部分-k:微调骨干网络的最后k层,同时冻结其他层,这在[85,88,60,30]中被采用。它重新定义了骨干网络和分类头之间的边界。
- 多层感知机(MLP)-k:将多层感知机(MLP)与k层代替线性层作为分类头。
- 更新backbone子集或添加新的可训练参数的方法:
- Sidetune:训练一个"side"网络,并在线性插值之前将预训练特征和side-tuned特征进行插值,然后输入到分类头。
- Bias:仅微调预训练骨干网络的偏置项。
- Adapter:在Transformer层内部插入具有残差连接的新MLP模块。
-
论文中在哪些下游任务上验证了VPT微调的有效性?
-
FGVC (Fine-Grained Visual Classification tasks) , 包含5个视觉分类任务
备注:具体为CUB-200-2011、NABirds、Oxford Flowers、Stanford Dogs、Stanford Cars五个任务
-
VTAB ,包含19个视觉分类任务,每个任务都有1000个训练样本。
备注:VTAB的19个视觉分类任务又划分为三种类型,即Natural - tasks(图片由标准相机拍摄), Specialized - tasks(由专业设备捕获的图像,如医疗和卫星图像), Structured - tasks(目标计数等), 文中给出的准确率也是按照这三种类型分别给出的。
-
-
实验设置:
- 对train set 做8/2的划分
- 最后一次evaluation时会使用全部的training data
- average accuracy是在test set上跑了三次取的均值
-
实验结果
不同微调方法在不同data scale下的表现:

不同微调方法在不同back-bone下的表现:

其他
关于Visual Prompt Tuning后续也有很多相关的研究和论文,此处列出一些供感兴趣者继续学习。
[1]: Exploring Visual Prompts for Adapting Large-Scale Models
[2]: Explicit Visual Prompting for Low-Level Structure Segmentations(CVPR 23)
















 1327
1327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











