







Transparent Image Layer Diffusion using Latent Transparency
公和众与号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
![]()
目录
0. 摘要
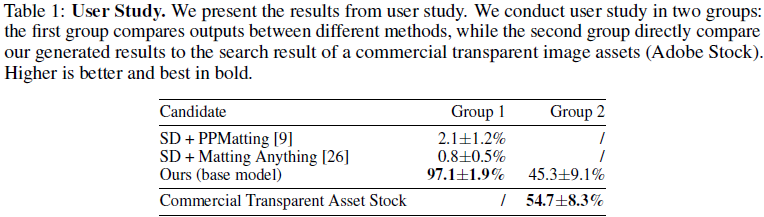
我们提出了 LayerDiffusion,一种使大规模预训练的潜在扩散模型(latent diffusion model,LDM)能够生成透明图像的方法。该方法允许生成单个透明图像或多个透明层。该方法学习了一个 “潜在透明度(latent transparency)”,将 alpha 通道透明度编码到预训练的潜在扩散模型的潜在流形中。通过将添加的透明度调节为潜在偏移(latent offset),最小限度地改变预训练模型的原始潜在分布,从而保留了大规模扩散模型的生产就绪(production-ready)质量。通过对调整后的潜在空间进行微调,以这种方式,任何潜在扩散模型都可以转换为透明图像生成器。我们使用人工参与的方案收集了 100 万透明图像层对进行模型训练。我们展示了潜在透明度可以应用于不同的开源图像生成器,或者适应于各种条件控制系统,实现诸如前景/背景条件的层生成、联合层生成、层内容的结构控制等应用。一项用户研究发现,在大多数情况下(97%),用户更喜欢我们本地(natively)生成的透明内容,而不是先生成然后进行抠图等以前的临时解决方案。用户还报告说,我们生成的透明图像的质量与像 Adobe Stock 等真实商业透明资产相媲美。

2. 相关工作
2.1 将图像隐藏在扰动内
多个领域的研究都指出了一个现象:神经网络有能力在现有特征内部 “隐藏” 特征,而不改变整体特征分布,例如通过微小而看不见的像素扰动在另一幅图像中隐藏一个图像。典型的 CycleGAN [60] 实验展示了人脸对拉面(face-to-ramen),其中人脸身份可以通过微小的不可见像素扰动隐藏在拉面图片中。类似地,可逆降尺寸(invertible downscaling) [52] 和可逆灰度(invertible grayscale) [51] 表明神经网络可以在较小的图像中隐藏一个大图像,或者在灰度图像中隐藏一个彩色图像,然后重构原始图像。在另一个扩展验证的实验中,Goodfellow 等人 [14] 展示了对抗样本信号可以隐藏在特征扰动中,以影响其他神经网络的行为。在本文中,我们提出的 “潜在透明度”利用了类似的原理:通过将透明图像特征隐藏在添加到 Stable Diffusion [43] 潜在空间的小扰动中,同时避免对潜在空间整体分布的更改。这使得从现有的非透明图像扩散模型无缝过渡到透明扩散模型,并且便于进一步的微调。
2.2 扩散概率模型和潜在扩散
(2022|CVPR,LDM)使用潜在扩散模型进行高分辨率图像合成
2.3 定制扩散模型和图像编辑
(2023,ControlNet,CFGRW,diffusion,控制组合)向文本到图像扩散模型添加条件控制
2.4 透明图像处理
透明图像处理与图像分解、图层提取、调色板处理以及图像抠图(matting) [49, 2, 1] 等密切相关。典型的基于颜色的分解可以看作是一个 RGB 颜色空间几何问题 [45, 46, 47, 48, 11]。这些思想也被扩展到更高级的图像层混合[25]。基于解混的颜色分离也有助于图像分解 [3],并且语义特征可以用于图像软分割 [4]。在我们的实验和讨论中,我们将我们的方法与几种最先进的基于深度学习的抠图方法进行比较。PPMatting [9] 是一个从头开始使用标准抠图数据集训练的神经网络图像抠图模型。Matting Anything [26] 是使用 Segment Anything Model(SAM)[22] 作为骨干的图像抠图模型。VitMatte [56] 是一种使用 Vision Transformer(ViT)的基于 trim-map 的抠图方法。
3. 方法
我们的方法使 Latent Diffusion Model(LDM),如 Stable Diffusion,能够生成透明图像,并进一步扩展模型以共同生成多个透明图层。
定义。为了清晰起见,我们首先定义一些术语。对于任何具有 RGBA 通道的透明图像 I_t ∈ R^(h×w×4),我们将前 3 个 RGB 颜色通道表示为 Ic ∈ R^(h×w×3),将 alpha 通道表示为 Iα ∈ R^(h×w×1)。由于在 alpha 值严格为零的像素处颜色在物理上未定义,因此在本文中,Ic 中的所有未定义区域始终由迭代高斯滤波(附录 A)填充,以避免失真和不必要的边缘模式。我们称 Ic 为“填充的 RGB 图像”(图 2)。可以将 I_t 转换为 “预乘图像(premultiplied image)”,即 I = Ic ∗ Iα,其中 ∗ 表示逐像素乘法。在本文中,所有 RGB 值都在范围 [-1, 1](与 Stable Diffusion 一致),而所有 alpha 值都在范围 [0, 1]。预乘图像 I 可以看作是一个常规的非透明 RGB 图像,可以由任何 RGB 格式的神经网络处理。这些图像的可视化显示在图 2 中。
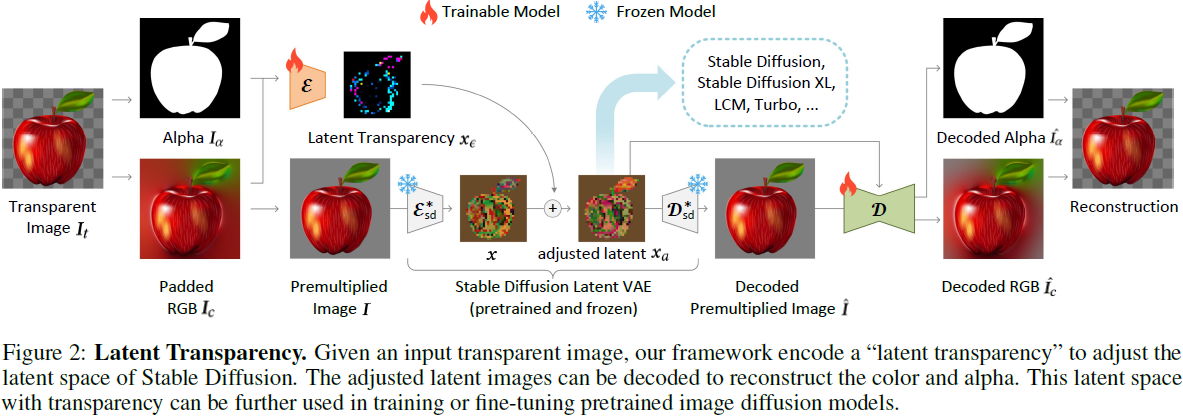
3.1 潜在透明度
我们的目标是为大规模潜在扩散模型(如 Stable Diffusion,SD)添加透明度支持,该模型通常使用潜在编码器(VAE)将 RGB 图像转换为潜在图像,然后将其馈送到扩散模型。在这里,VAE 和扩散模型应共享相同的潜在分布,因为任何主要(major)不匹配都可能显著降低潜在扩散框架的推断/训练/微调。当我们调整潜在空间以支持透明度时,必须尽可能保留原始潜在分布。这个看似不明确的目标可以通过一个简单的测量来确定:我们可以检查修改后的潜在分布如何被原始预训练的冻结潜在解码器解码——如果解码修改后的潜在图像会导致严重的伪影,那么潜在分布是不匹配或破损的。
我们可以将这个 “有害性” 度量数学地表示如下。给定一个 RGB 图像 I,预训练且冻结的 Stable Diffusion 潜在编码器 E*_sd(·) 和解码器 D*_sd(·),其中 * 表示冻结的模型,我们将潜在图像表示为 x = E*_sd(I)。假设这个潜在图像 x 被任何偏移 x_ϵ 修改,产生了调整后的潜在 x_a = x + x_ϵ。然后,解码的 RGB 重建可以写成 ˆI = D*_sd(x_a),我们可以评估偏移 x_ϵ 的 “有害性” 如下:
![]()
其中,∥⋅∥_2 是 L2 范数距离(均方误差)。直观地说,如果 L_identity 相对较高,x_ϵ 可能是有害的,可能破坏了 SD 编码器-解码器的重建功能;否则,如果 L_identity 相对较低,偏移 x_ϵ 不会破坏潜在重建,修改后的潜在仍然可以由预训练的 Stable Diffusion 处理。
我们利用潜在偏移 x_ϵ 来建立用于编码/解码透明图像的 “潜在透明度”。更具体地说,我们从头开始训练一个潜在透明度编码器 E(·, ·),它将 RGB 通道 Ic 和 alpha 通道 Iα 作为输入,将像素空间的透明度转换为潜在偏移 xϵ:
![]()
然后,我们从头开始训练另一个潜在透明度解码器 D(·, ·),它将调整后的潜在 xa = x + xϵ 和前述的 RGB 重建 ˆI = D*_sd(xa) 作为输入,从调整后的潜在空间中提取透明图像:
![]()
其中,ˆIc, ˆIα 是重建的颜色和 alpha 通道。E(·, ·) 和 D(·, ·) 的神经网络层架构详见附录 B。我们使用以下公式评估重建:
![]()
并且实验证明通过引入 PatchGAN 判别器损失,结果质量可以进一步提高:
![]()
其中,L_disc(⋅,⋅) 是来自 5 层 Patch 判别器的 GAN 目标(详见附录 C)。最终目标可以联合写成:
![]()
其中,λ... 是权重参数,默认情况下我们使用 λrecon=1, λidentity=1, λdisc=0.01。通过使用 L_vae 训练这个框架,可以从透明图像中编码出调整后的潜在 xa,反之亦然,并且这些潜在图像可以用于微调 Stable Diffusion。我们在图 2 中可视化了这个流程。
3.2 具有潜在透明度的扩散模型
由于潜在透明度的调整潜在空间明确受到规范以与原始预训练潜在分布对齐(式 1),因此 Stable Diffusion 可以直接在调整后的潜在空间上进行微调。给定调整后的潜在 xa,扩散算法逐渐向图像添加噪音并生成由 t 表示添加噪音次数的噪音图像 xt。当 t 足够大时,潜在图像逼近纯噪音。考虑一组条件,包括时间步长 t 和文本提示 ct,图像扩散算法学习一个网络 ϵθ,该网络预测添加到噪音潜在图像 xt 的噪音,具体如下:
![]()
其中 L 是整个扩散模型的总体学习目标。这个训练过程在图 3-(a) 中可视化。
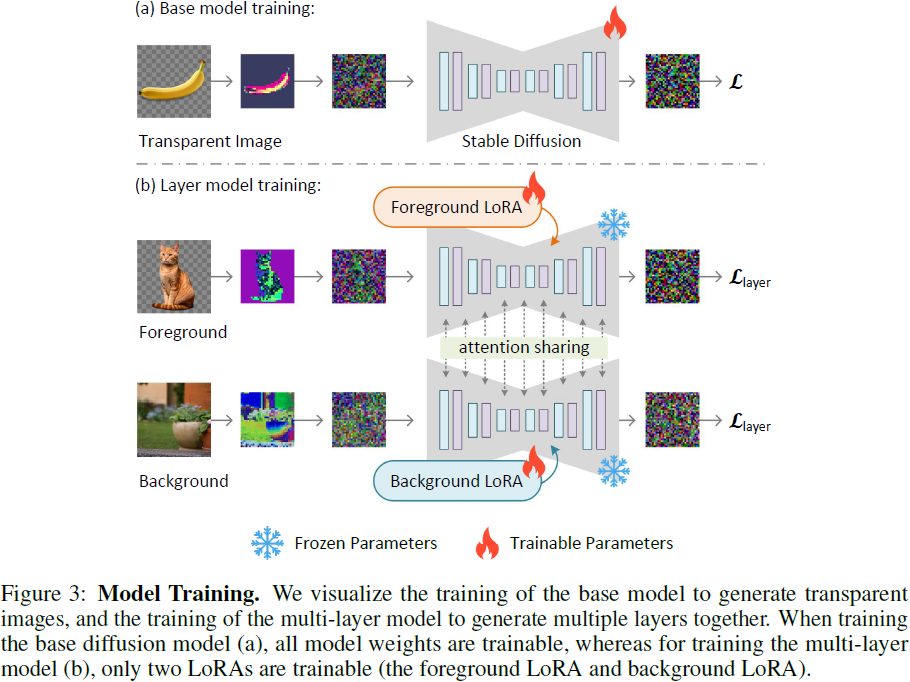
3.3 生成多个图层
我们通过使用注意力共享和 LoRAs([17])将基本模型扩展为多层模型,如图 3-(b) 所示。我们将前景噪音潜在表示为 xf,背景表示为 xb,并训练两个 LoRA 模型,一个由 θf 参数化的前景 LoRA 和一个由 θb 参数化的背景 LoRA,以去噪潜在图像。如果两个模型独立地去噪两个图像,我们具有以下两个目标:
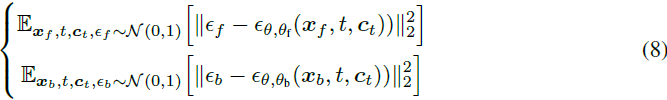
其中,ϵf,ϵb 是前景和背景的潜在噪音。然后,我们合并两个独立的扩散过程以实现协同生成。对于扩散模型中的每个注意力层,我们将由两个图像激活的所有 {key, query, value} 向量连接起来,以便两个传递可以合并为一个联合优化的大模型 ϵθ,θf,θg(·)。我们将合并的噪声表示为连接的 ϵm = [ϵf, ϵb],并且我们有最终目标:
![]()
以协同生成多个图层。我们还可以对此目标进行简单修改以支持条件图层生成(例如,以前景为条件的背景生成,或以背景为条件的前景生成)。更具体地说,通过对前景使用干净的潜在而不是噪音潜在(即始终设置 ϵf = 0),模型将不会对前景进行去噪,该框架将成为前景条件生成器。类似地,通过设置 ϵb = 0,该框架将成为背景条件生成器。我们在实验中实现了所有这些条件变体。
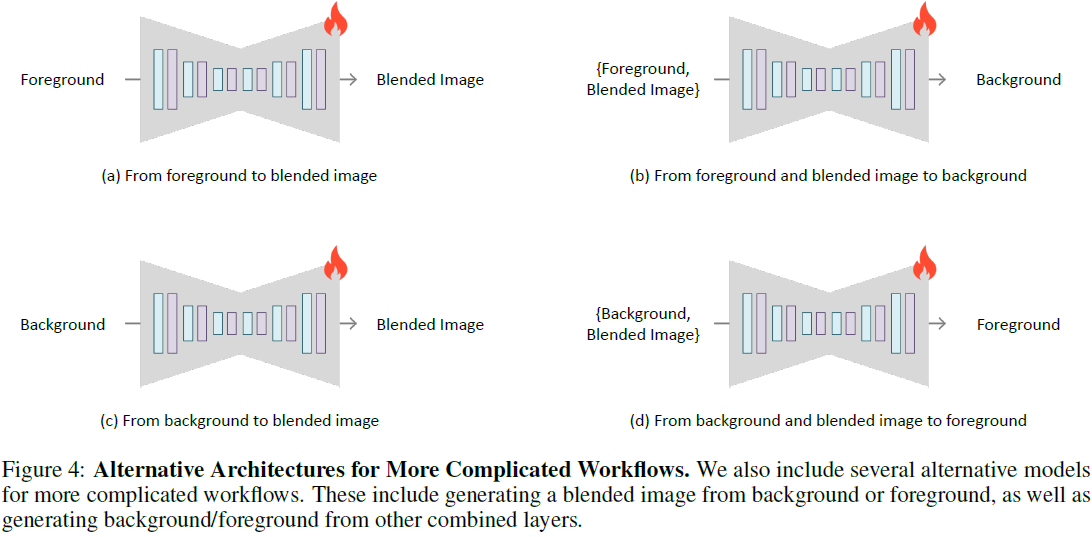
我们还在图 4 中引入了几种更复杂工作流的替代架构。我们可以向 UNet 添加零初始化的通道并使用 VAE(具有或没有潜在透明度)将前景、背景或图层组合编码成条件,并训练模型生成前景或背景(例如,图 4-(b, d)),或直接生成混合图像(例如,图 4-(a, c))。
4. 实验










4.10 限制
正如图 15 所示,我们的框架存在 “生成 ‘清晰透明元素’” 和 “和谐混合” 的权衡。例如,如果透明图像是一个没有任何特殊照明或阴影效果的清晰可重复使用的元素,生成一个可以与前景和谐混合的背景可能非常具有挑战性,模型可能无法在所有情况下成功(图 15-(c) 是一个失败的案例)。如果我们只使用背景作为条件来生成前景,以迫使和谐混合,可以在一定程度上解决这种现象(图 15-(d))。然而,这也会导致照明影响透明对象,使透明对象的可重复使用性降低。有人可能会认为图 15-(a) 中的图像对设计师和野外应用更具可重复性,而图 15-(d) 中的透明图像包含许多与背景相关的特定图样。
附录
A. 补零的 RGB 通道
在透明 RGBA 图像的 RGB 通道中,我们将完全不可见的像素称为 “未定义” 像素,即 alpha 值严格等于零的像素。由于这些像素是绝对不可见的,用任意颜色处理它们不会影响经过 alpha 混合后图像的外观。然而,由于神经网络往往会在图像边缘产生高频图样(pattern),我们避免在 RGB 通道中出现不必要的边缘,以避免潜在的伪影。我们定义一个局部高斯滤波器:
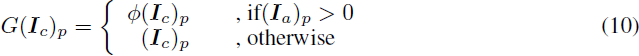
其中,ϕ(·) 是具有 13x13 内核的标准高斯滤波器,p 是像素位置。我们对此滤波器执行 64 次,以完全传播颜色到所有“未定义”像素。
B. 神经网络架构
潜在透明度编码器与 Stable Diffusion 潜在 VAE 编码器 [31] 具有完全相同的神经网络架构(但输入包含 4 个通道,对应 RGBA)。该模型是从头开始训练的。输出卷积层被零初始化,以避免初始有害噪音。
潜在透明度解码器是一个 UNet。这个 UNet 的编码部分具有与 Stable Diffusion 潜在 VAE 编码器相同的架构,而解码部分具有与 Stable Diffusion VAE 解码器相同的架构。输入潜在被添加到中间块,所有编码器的特征图通过跳跃连接添加到每个解码器块的输入。具体而言,假设输入图像是 512 × 512 × 3,输入潜在是 64 × 64 × 4,特征图经过以下过程:
512×512×3→512×512×128→256×256×256→128×128×512→64×64×512512×512×3→512×512×128→256×256×256→128×128×512→64×64×512
其中每个 → 是两个 ResNet 块。然后,输入潜在通过卷积层投影以匹配通道,然后添加到中间特征。然后解码器经过以下过程:
64×64×512→128×128×512→256×256×256→512×512×128→512×512×364×64×512→128×128×512→256×256×256→512×512×128→512×512×3
在这里,每个 → 还将对应于编码器的层的跳跃特征添加到解码器的输入。
C. PatchGAN 判别器
我们使用与 Latent Diffusion VAE[34] 相同的 PatchGAN 判别器架构、学习目标和训练调度。我们直接使用其官方代码库中的 Python 类 LPIPSWithDiscriminator(输入通道设置为 4)。生成器侧的目标(来自[34])可以表示为:
![]()
其中 z 是形状为 h × w × 4 的矩阵,relu(⋅) 是修正线性单元。Ddisc(⋅) 是一个具有 5 个卷积-归一化-SiLU 层的神经网络,结构为 512×512×3→512×512×64→256×256×128→128×128×256→64×64×512→64×64×1512×512×3→512×512×64→256×256×128→128×128×256→64×64×512→64×64×1
最后一层是一个面向补丁的真/假分类层。最后一层不使用归一化和激活。

















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









