







Directly Denoising Diffusion Model
公众号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
![]()
![]()
目录
0. 摘要
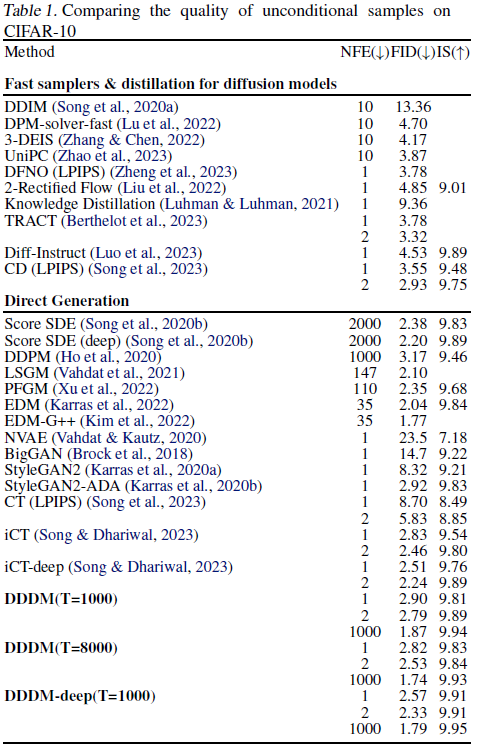
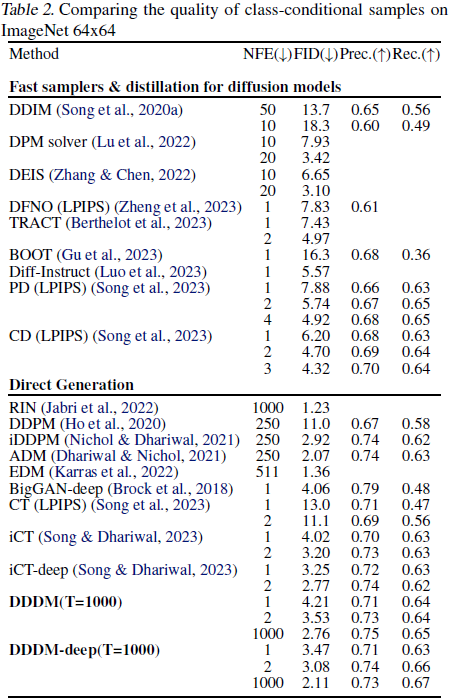
本文介绍了直接去噪扩散模型(Directly Denoising Diffusion Model,DDDM):一种简单且通用的方法,采用少步采样生成逼真的图像,同时保留了多步采样以获得更好的性能。DDDM 不需要精心设计的采样器,也不需要在预训练的蒸馏模型上进行蒸馏。DDDM 在估计的目标上训练扩散模型,该目标是由自身之前训练迭代生成的。为了生成图像,还考虑了来自上一个时间步长的样本,通过迭代地引导生成过程。我们进一步提出了 Pseudo-LPIPS,一种更稳健的度量损失,能够更好地适应各种超参数值。尽管方法简单,但在基准数据集上表现出了强大的性能。我们的模型在 CIFAR-10 数据集上实现了 FID 分数分别为 2.57 和 2.33,在一步和两步采样中,超过了来自 GAN 和基于蒸馏的模型获得的分数。通过将采样扩展到 1000 步,我们将 FID 分数进一步降低到 1.79,与文献中最先进的方法保持一致。对于 ImageNet 64x64,我们的方法与领先的模型相比具有竞争力。
(2021|ICLR,扩散先验,VE-SDE,逼真和忠实的权衡)SDEdit:使用随机微分方程引导图像合成和编辑(2024|ICLR,DDBM,基于分数的 ODE 和 SDE,Doob 的 h 变换)去噪扩散桥模型
3. 直接去噪扩散模型
求解概率流(PF)常微分方程(ODE)等价于计算以下积分:
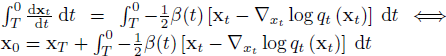
其中 x_{T} 从正态分布 N(0, I) 初始化。 为了从 DM 生成样本,我们提出了直接去噪扩散模型(DDDM),这是一个用于改进 x_{0} 估计的迭代过程。首先,我们将 f(x_{0}, x_{t}, t) 定义为从初始时间 t 到最终时间 0 的 PF ODE 的解(附录 A.1):
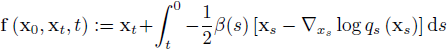
其中 x_{t} 从
![]()
中抽取。随后,我们引入了函数 F(x_{0}, x_{t}, t) 的定义如下:
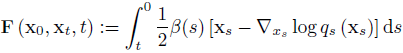
因此,我们有:
![]()
通过近似 f,我们可以恢复原始图像 x_{0}。我们定义一个由神经网络参数化的函数 f_θ,用于估计 PF ODE 的解,从而在时间 0 恢复原始图像状态。预测模型表示为:
![]()
其中 F_θ 是由权重 θ 参数化的神经网络函数。为了实现对初始状态 x_{0} 的良好恢复,需要确保
![]()

3.1. 迭代求解
方程 (3) 表明,我们的神经网络 F_θ 需要 x_0 作为输入,但这在样本生成过程中不适用。为了在同一框架内统一训练和推断,我们提出了一个迭代更新规则来估计动态系统的初始状态 x_0。这个迭代过程由以下更新方程正式定义:
![]()
其中 x^(n)_0 表示第 n 个训练周期或第 n 次采样迭代的估计地面真实数据 x_0。每次更新都会调整此估计以试图收敛到真实的初始状态。为了有效地量化 DDDM 中第 n 次估计 x^(n)_0 与真实初始状态 x_0 之间的差异,我们采用以下损失函数。
定义 3.1. 第 n 次迭代中 DDDM 的损失函数定义为:
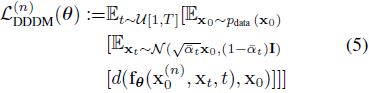
其中 U[1, T] 表示整数集合 [1, 2, ..., T] 上的均匀分布。d(·, ·) 是一个满足对于所有向量 x 和 y,d(x, y)>=0 并且 d(x, y) = 0 当且仅当 x = y 的度量函数。因此,常用的度量方法如 L_1、L_2 等可以被利用。我们将在第 4 节讨论我们选择的 d(·, ·) 。这个定义封装了估计状态 x^(n)_0 与真实初始状态 x_0 之间的预期差异,整合了数据和时间域的概率模型。
训练。每个数据样本 x_0 都是从数据集中随机选择的,遵循概率分布 p_data (x_0)。这个初始数据点构成了生成轨迹的基础。接下来,我们随机抽样一个时间步 t ∼ U[1, T],并从分布
![]()
中获取其噪声变体 x_t。我们使用重新参数化技巧来重新表示
![]()
对于当前训练周期 n,我们的模型接收噪声数据 x_t 和时间步 t,以及来自上一个周期的相应估计目标 x^(n-1)_0 作为输入,预测一个新的近似值 x^(n)_0,它将在下一个训练周期中用于相同的目标样本。DDDM 通过最小化方程 5 的损失来进行训练。DDDM 的完整训练过程总结在算法 1 中。

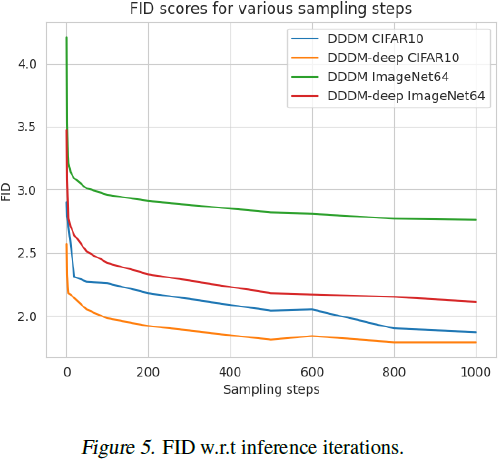
采样。样本的生成通过一个训练良好的 DDDM 来实现,记为 fθ(·, ·).。该过程从初始高斯分布抽样开始,其中 x^(0)_0 和 x^(T)_0 都从 N(0, I) 中抽样。随后,这些噪声向量和 T 的嵌入被通过 DDDM 模型,以获得 x^est_0 = fθ(x^(0)_0 , x_T , T)。这种方法值得注意的是其效率,因为它只需要对模型进行一次前向传播。我们的模型还支持多步采样过程,以提高样本质量。详细信息可以在算法 2 中找到。 在这里,我们提供了我们方法收敛的理论证明(见原论文)。
4. Psuedo-LPIPS 指标
在图像生成中,图像质量的评估变得越来越关键。可学习感知图像补丁相似度(LPIPS,Zhang 等人(2018))指标已经成为提高生成图像质量的重要工具。然而,在实践中,LPIPS 仍然不足以应对异常值。受 Song & Dhariwal (2023) 最近使用 Psuedo-Huber 损失显著提高训练一致性模型鲁棒性的启发,我们提出了 LPIPS 指标的修改版本,称为 Psuedo-LPIPS:
![]()
其中 c 是一个可调节的超参数。与 Psuedo-Huber 指标类似,Psuedo-LPIPS 指标中的项 c^2 和随后的平方根转换旨在提供更平衡和感知上一致的度量。这种方法减轻了对较大误差的过度强调,并增加了度量在识别图像感知差异方面的灵敏度和准确性。Psuedo-LPIPS 指标的优点如下:
- 对感知差异的敏感度增强:修改后的指标对轻微的感知差异进行了精细调整,这些差异常常被传统指标忽略。在需要高精度图像质量的领域,如医学成像或高保真渲染中,这种敏感性尤为宝贵。
- 平衡的错误强调:它在各种错误大小上提供了更公平的强调,与 L2 范数倾向于过度惩罚较大误差形成对比。
- 适应性:常数 c 的引入使得该指标具有灵活性,使得该指标适用于不同的情景和数据集。
- 提高的稳健性:该指标对异常值和异常情况更具稳健性,通过平方根转换,解决了 Psuedo-Huber 损失中的一个常见缺陷。
与 L2 范数和 Psuedo-Huber 损失相比,修改后的 LPIPS 与人类感知判断更为接近。L2 范数在数学形式上虽然简单,但通常无法准确地代表人类视觉。Psuedo-Huber 损失虽然试图将 L1 范数和 L2 范数的优点合并起来,但有时在提供平衡的感知质量表示方面存在不足。通过其细致的制定,Psuedo-LPIPS 有效地弥合了这些差距,提供了一种既具有感知意义又在数学上合理的指标。
5. 实验


7. 讨论和局限性
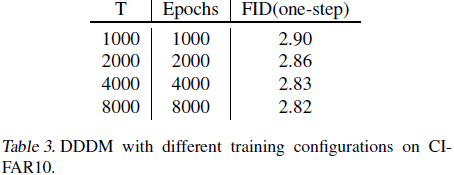
由于 DDDM 为数据集中的每个样本跟踪 x^(n)_0,在训练过程中会消耗额外的内存。具体来说,它需要额外的 614MB 用于 CIFAR-10 和 29.5GB 用于 ImageNet 64x64。尽管可以通过使用 FP16 数据类型将内存需求减半,但这种内存需求对于更大数据集或高分辨率图像数据集来说仍可能是一个挑战。
我们还注意到,评估过程中可能存在偏差,因为在 LPIPS 和用于 FID 的 Inception 网络中都使用了 ImageNet。LPIPS 中 ImageNet 特征的意外泄露可能会导致 FID 得分的虚高。需要采用其他评估指标,如人工评估,以进一步验证我们的模型。此外,研究针对 DDDM 的无偏损失也是未来研究的一个有趣方向。

















 160
160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









