







Spiking Diffusion Models
![]()

目录
0. 摘要
近年来,脉冲神经网络(Spiking Neural Networks,SNNs)因其超低能耗和较高的生物合理性相较于传统人工神经网络(Artificial Neural Networks,ANNs)而备受关注。尽管 SNN 具有突出的特性,但在计算密集型的图像生成领域的应用仍处于探索阶段。在本文中,我们提出了脉冲扩散模型(Spiking Diffusion Models,SDMs),这是一类创新的基于 SNN 的生成模型,能够以显著降低的能耗生成高质量样本。具体而言,我们提出了一种时间维脉冲机制(Temporal-wise Spiking Mechanism,TSM),从生物可塑性的角度使 SNN 能够捕获更多时间特征。此外,我们提出了一种阈值引导策略,可以在无需额外训练的情况下,将性能提升多达 16.7%。我们还首次尝试使用 ANN-SNN 方法用于基于 SNN 的生成任务。广泛的实验结果表明,我们的方法不仅在较少脉冲时间步下表现出与其 ANN 对等模型相当的性能,还显著超越了以往基于 SNN 的生成模型。此外,我们还展示了 SDM 在大规模数据集(如 LSUN bedroom)上的高质量生成能力。这一发展标志着基于 SNN 生成能力的重要进步,为实现低能耗和低延迟的生成应用的未来研究开辟了新的道路。
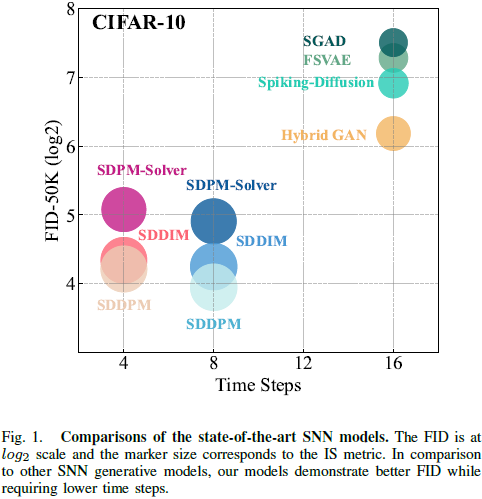
如图 1 所示,我们提出的 SDM 仅用少量脉冲时间步就显著超越了所有基于 SNN 的生成模型。
2. 相关工作
A. 脉冲神经网络的训练方法
一般而言,获取深层 SNN 模型的两种主流方式是 ANN-to-SNN 转换和直接训练:
直接训练。直接训练方法从头开始直接训练 SNN。然而,直接训练面临的固有挑战来自脉冲神经元输出的非可微性,这使得依赖连续梯度的传统反向传播技术难以应用。为了解决这一问题,直接训练方法使用替代梯度(surrogate gradients) [35], [36], [37] 进行反向传播。这些替代梯度提供了脉冲函数的平滑近似,从而促进了基于梯度的优化方法在 SNN 训练中的应用。
ANN-to-SNN。ANN-to-SNN 转换方法的基本思想 [38], [39], [40], [41] 是将 ANN 中 ReLU 激活值替换为脉冲神经元的平均发放率(average firing rates)。通常认为,与直接训练方法相比,ANN-to-SNN 转换方法可以实现更高的准确性。然而,与直接训练方法相比,ANN-to-SNN 转换方法通常需要更长的训练时间,因为转换过程需要更多时间步和额外的优化,这可能会限制其在实际 SNN 应用中的效率。
在我们的研究中,我们深入探讨了直接训练方法在 SNN 框架中整合扩散模型的应用,旨在降低功耗并探索 SNN 的潜在生成能力。此外,我们还扩展研究范围,包含了用于实现基于 SNN 的扩散模型的 ANN-to-SNN 转换方法,从而全面比较这两种训练范式的结果。
B. 基于生成模型的脉冲神经网络
大多数基于 SNN 的生成算法主要源自 ANN 中的生成模型,例如 VAE 和 GAN。[42], [43], [44] 提出了由 SNN 编码器和 ANN 解码器组成的混合架构。然而,这些方法依赖于 ANN 的结构,使得整个模型无法完全部署在类脑计算硬件上。
- Spiking GAN [45] 采用了完全基于 SNN 的骨干网络,并使用时间首脉冲(time-to-first-spike)编码方案。该方法显著提高了脉冲序列的稀疏性,从而实现了较大的能量节约。
- Kamata 等人 [30] 随后提出了一种完全脉冲变分自编码器(fully spiking variational autoencoder,FSVAE),可以在整个生成过程中仅通过伯努利分布采样的脉冲进行传递。
- Feng 等人 [46] 构建了一个带有注意力评分解码的脉冲 GAN(spiking GAN with attention scoring decoding,SGAD),并识别了现有脉冲 GAN 方法中固有的域外不一致性和时间不一致性问题,从而提高了性能。
- 最近,Watanabe 等人 [47] 提出了一个完全基于脉冲的去噪扩散隐式模型,通过突触电流(synaptic current)学习实现了 SNN 的高速和低能耗特性。
然而,无论所提出的模型是基于VAE/GAN,还是完全基于脉冲神经元,现有脉冲生成模型的主要限制在于其性能低下以及生成图像质量较差。这些缺点虽然具有低能耗的优势,但限制了它们在生成模型领域的竞争力。为了解决这一问题,我们引入了 SDM,不仅在现有基于 SNN 的生成模型上实现了显著改进,同时还保留了 SNN 的优势。
3. 背景
A. 脉冲神经网络
脉冲神经网络(Spiking Neural Network, SNN)是一种仿生算法,模拟了大脑中实际发生的信号传递过程。与人工神经网络(Artificial Neural Network, ANN)相比,SNN 传递稀疏脉冲而非连续表示,具有低能耗和鲁棒性等优势。在本文中,我们采用了广泛使用的泄漏积分-发放模型(Leaky Integrate-and-Fire, LIF [48], [49]),该模型有效表征了脉冲生成的动态过程,其定义如下:
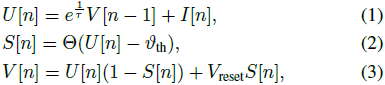
其中,n 表示时间步,U[n] 是复位前的膜电位(membrane potential),S[n] 表示输出脉冲,当脉冲发生时取值为 1,否则为 0,Θ(x) 是阶跃函数,V[n] 代表触发脉冲后的膜电位。此外,在公式 (3) 中,我们采用了 “硬复位”(hard reset)方法 [50] 用于复位膜电位。这意味着,当触发脉冲(S[n]=1)时,膜电位 V[n] 的值将重置为 V_reset=0V。
【SNN 综述
https://arxiv.org/abs/2409.02111
https://arxiv.org/abs/2408.14437
】
B. 扩散模型与无分类器引导
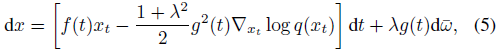
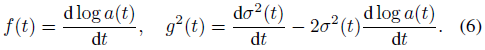
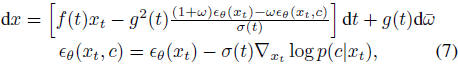
其中,α(t) 和 σ(t) 表示噪声调度(noise schedule),而 x_t 是从 q(xt∣x0)∼N(xt∣α(t)·x0, σ^2(t)·I) 中采样的样本。
4. 方法
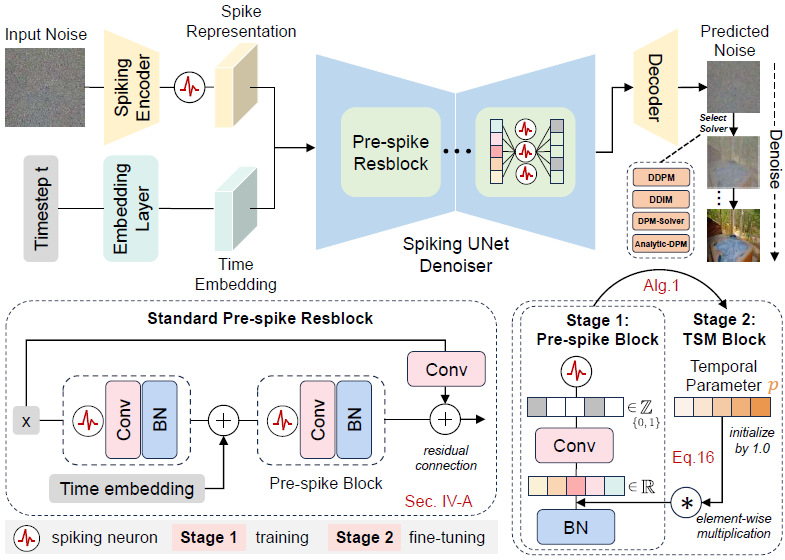
图 2. 脉冲扩散模型概览。SDM 的学习过程包括两个阶段:(1)训练阶段和(2)微调阶段。
- 在训练阶段,脉冲 UNet 采用标准的预脉冲残差块(左下,见第 4-A 节),然后将预脉冲残差块转换为时间维脉冲机制(TSM)块(右下,见第 4-B节),进入微调阶段。给定一个随机高斯噪声输入 x_t,它首先通过脉冲编码器转换为脉冲表示,然后与时间嵌入一起输入到脉冲 UNet 中。网络仅传递脉冲,这些脉冲通过 0/1 向量(∈ {0,1})表示。最后,输出的脉冲通过解码器得到预测噪声 ϵ,并计算损失以更新网络。
- 在微调阶段,我们从训练阶段加载权重,并用时间维脉冲机制(TSM)块替换预脉冲残差块,其中时序参数 p 初始化为 1.0。该阶段继续优化网络的参数,以获得更好的生成性能。
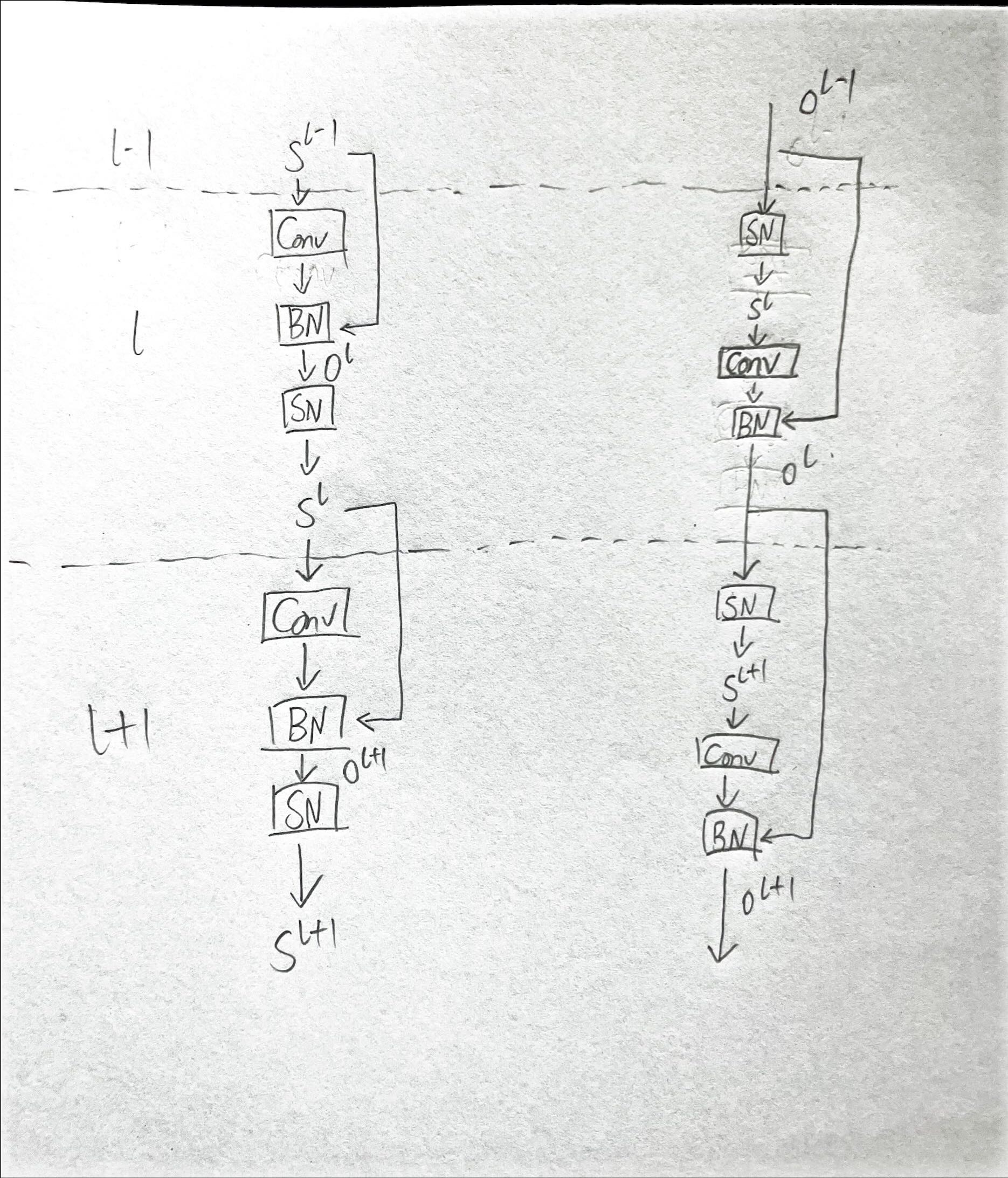
A. 预脉冲残差学习
我们首先分析了以往脉冲神经网络(SNNs)中残差学习方法的局限性和概念性不一致,特别是SEW ResNet [57] 的方法,其可以表述为:
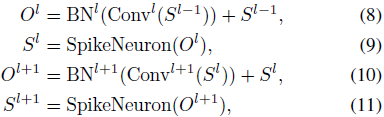
其中,O^l 表示第 l 层经过批量归一化(Batch Normalization, BN)和卷积操作后的输出,S^l 表示脉冲神经元的激活函数(见公式 (2))。这种残差结构 [58], [59], [57] 直接继承自传统人工神经网络(ANN)ResNet 架构 [60]。然而,这种方法存在一个根本性的问题,即残差块输出范围的扩展问题。
问题的核心在于脉冲神经元输出的特性(S^{l-1} 和 S^l),它们是二值脉冲序列,取值范围为 {0,1}。因此,当这些序列在残差结构中求和(即 O^l)时,求和后的输出域会扩展到 {0,1,2}。在此语境中,值 {2} 的出现是非生物的,偏离了合理的神经激活模式。这种溢出现象不仅降低了模型的生物合理性,还可能在前向传播过程中干扰信息的有效传递。
受到 [61], [62] 的启发,我们在 Spiking UNet 中采用预脉冲残差学习,其结构为 “激活-卷积-批量归一化”(Activation-Conv-BatchNorm),以解决基于卷积的 SNN 中梯度爆炸/消失和性能退化的双重挑战。在预脉冲块中,残差和输出通过浮点数加法操作相加,确保在进入下一个脉冲神经元之前表示的准确性,同时避免上述病态情况。
整个预脉冲残差学习过程可以在一个残差块(resblock)中表述为:
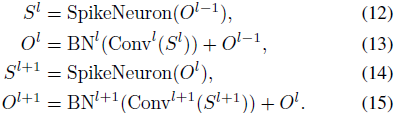
通过预脉冲残差机制,残差块的输出可以通过两个浮点数 BN^l (Conv^l (S^l)) 和 O^{l−1} 在相同的尺度下求和,然后进入下一个块的脉冲神经元,这确保了能耗仍然保持在非常低的水平。
B. 时间维脉冲机制
在本节中,我们首先从生物学的角度回顾了传统 SNN 的不足,并提出了一种新颖的时间维脉冲机制(Temporal-wise Spiking Mechanism, TSM),通过引入时间参数来微调权重,从而捕捉时间动态。
考虑第 l 层的脉冲输入为
![]()
其中 N 表示 minibatch 大小。对于每个时间步 n∈{1,2,...,T},神经元将通过公式 (1) 更新其暂时的膜电位,其中
![]()
![]()
表示第 l 层卷积层的权重矩阵。
传统的 SNN [58] 在执行膜电位更新时会将输入的 T 和 C 维度融合为
![]()
然后通过二维卷积操作进行计算。这导致每个时间步的输入都由相同的权重矩阵操作。然而,在真实的神经系统中,皮层金字塔细胞(cortical pyramidal cells)在常规网络活动中会接收到强烈的兴奋性和抑制性突触后电位的冲击 [63]。此外,不同的觉醒状态可以改变膜电位并影响突触整合 [64]。这些研究共同表明,每个时刻神经元的输入会由于网络状态和其他因素而经历显著的波动,而不仅仅是由固定的突触权重主导。
为了通过时间提供更多动态信息,我们提出了时间维脉冲机制(TSM,见图 3),该机制确保每个时刻的输入信息都通过与时间步 n 相关的时间参数 p[n]∈P(P ∈ R^T)来计算:
![]()
我们在算法 1 中精确描述了 SDM 的整个学习过程。具体而言,学习流程包括(1)训练阶段和(2)微调阶段,在训练阶段我们首先使用预脉冲块训练SDM,然后利用 TSM 块微调模型。我们只使用少量迭代(少于 10 次训练迭代)来微调我们的模型。值得注意的是,由于 p[t] 仅为一个标量,因此 TSM 引入的额外计算成本可以忽略不计。通过计算 LMSE,我们可以进一步优化 W 和 P 的参数,以获得令人满意的网络。SNN-UNet 和 p[t] 的详细学习规则可以在附录中找到。

总之,TSM 使得膜电位在时间域上动态更新,从而提高了捕捉潜在时间依赖特征的能力。随后的实验表明,TSM 机制优于传统的固定更新机制。我们还在第 7-F 节中可视化了 P 以进行详细分析。
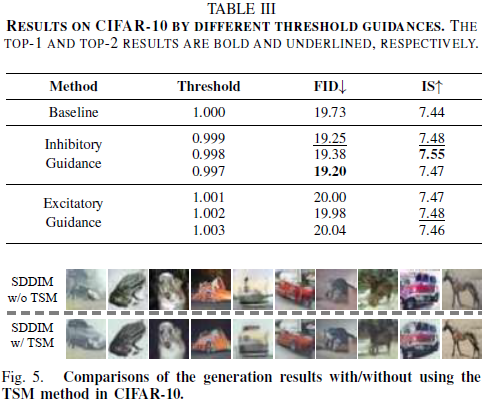
C. SDMs 中的阈值引导
如在第 3-B 节中所述,采样可以通过将得分
![]()
替换为得分网络 sθ(xt,t) 或缩放噪声网络
![]()
来实现,同时对反向 SDE 进行离散化,如公式(5)所示。由于网络估计的不准确性,我们知道在大多数情况下,
![]()
因此,为了获得更好的采样结果,我们可以离散化以下修正的反向 SDE:
![]()
其中,sθ(xt,t) 表示得分网络或缩放噪声网络,而
![]()
代表原始反向 SDE 的修正项。忽略修正项 cθ(xt,t) 会导致离散化误差降低,从而提高采样性能。然而,由于其难以处理,计算 cθ(xt,t) 存在挑战。
考虑到存在估计误差,公式(17)促使我们探讨是否可以通过计算 cθ(xt,t) 来增强采样性能,而无需额外的训练。SNN 中的一个关键参数是脉冲阈值,表示为 ϑ_th,它直接影响 SNN 的输出。例如,较小的阈值会促进更多脉冲的发生,而较大的阈值则抑制这种发生。在训练过程之后,我们可以调整 SNN 中的阈值,以估计修正项 cθ(xt,t),如下所示:
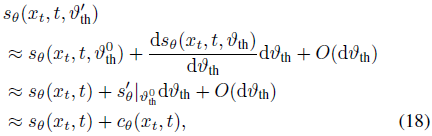
其中,ϑ^0_th 是训练阶段使用的阈值,而 ϑ'_th 是推理阶段使用的调整阈值。第一个等式通过泰勒展开获得。公式(18)表明,当导数项与修正项相关时,调整阈值可以提高最终的采样结果。我们将阈值降低的情况称为抑制性引导(inhibitory guidance),而相反的情况称为兴奋性引导(excitatory guidance)。
5. 理论能耗计算
在本节中,我们描述了计算脉冲 UNet 架构理论能耗的方法。该计算包括两个主要步骤:首先确定架构中每个模块的突触操作(synaptic operations,SOP),然后基于这些操作估算总体能耗。脉冲 UNet 中每个模块的突触操作可以如下量化 [8]:
![]()
其中,l 表示脉冲 UNet 中的模块编号,fr 是模块输入脉冲序列的触发频率,T 是脉冲神经元的时间步长,FLOPs(l) 指的是模块 l 的浮点操作数,即乘加(MAC)操作的次数。而 SOPs 则是基于脉冲的累加(AC)操作的次数。
为了估算脉冲扩散的理论能耗,我们假设 MAC 和 AC 操作是在 45 纳米硬件上实现的,其能耗分别为 E_MAC = 4.6pJ 和 E_AC = 0.9pJ。根据 [65]、[66],脉冲扩散的理论能耗计算公式为:
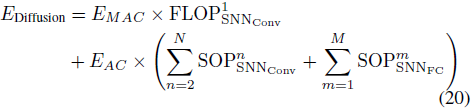
其中,N 和 M 分别表示卷积(Conv)层和全连接(FC)层的总层数。E_MAC 和 E_AC 分别是 MAC 和 AC 操作的能耗成本。FLOP_{SNN_Conv} 指的是第一层卷积(Conv)层的浮点运算次数,SOP_{SNN_Conv} 和 SOP_{SNN_FC} 分别是第 n 层卷积(Conv)和第 m 层全连接(FC)层的突触操作(SOP)次数。
6. 通过 ANN-SNN 转换实现脉冲扩散模型
在本文中,我们首次成功地利用 ANN-SNN 方法实现了 SNN 扩散模型。我们采用了 Fast-SNN 方法 [67] 来构建量化 ANN 和 SNN 之间的转换。由于这个实现不是我们论文的主要贡献,我们简要描述了 ANN-SNN 的原理,更多细节可以参考文献 [67]。
从 ANN 到 SNN 转换的核心思想是将量化 ANN 的整数激活值 0, 1, ..., 2^b − 1 映射为脉冲计数 {0, 1, ..., T},即将 T 转换为 2^b − 1。构建具有整数激活的量化 ANN 本质上等同于使用量化函数压缩激活值,该函数输出均匀分布的值。这样的函数空间上离散化了 ANN 中第 l 层神经元 i 的全精度激活值 x^l_i,表示为:
![]()
其中 Q^l_i 表示空间量化后的值,b 表示位数(精度),状态的数量为 2^b - 1,round(⋅) 是四舍五入操作,s_l 表示确定输入 x^l_i 剪裁范围的阈值,clip(x,min,max) 是将 x 裁剪到范围 [min,max] 内的操作。
在 SNN 中,脉冲的积分-发放(Integrate-and-Fire,IF)神经元本质上将膜电位 U^l_i 量化为由发放脉冲率 r^l_i 表示的量化值:
![]()
其中 ~Q^l_i 表示基于尖峰的量化值,floor(⋅) 表示向下取整操作。假设膜电位的值始终满足 U^l_i = T·I^l_i,比较公式 (22) 和 (21),我们令 μ^l = θ^l / 2, T = 2^b − 1, θ^l = s^l。由于向下取整操作可以转换为四舍五入操作:floor(x+0.5) = round(x),通过在下一层中将权重缩放为 s^l·W^{l+1},我们将公式 (22) 重写为:
![]()
因此,通过建立离散的 ReLU 值与脉冲发放率的等价关系(公式 (24)),我们在量化 ANN 和 SNN 之间架起了桥梁。需要注意的是,U^l_i = T·I^l_i 的假设仅在直接接收电流作为输入的第一层脉冲层中成立。然而,随着网络的加深,膜电位与输入电流之间的相互作用变得更加复杂,偏离了简单的线性关系。这种复杂性是 ANN-SNN 转换过程中逐渐增加的误差积累的根本原因之一。
7. 实验
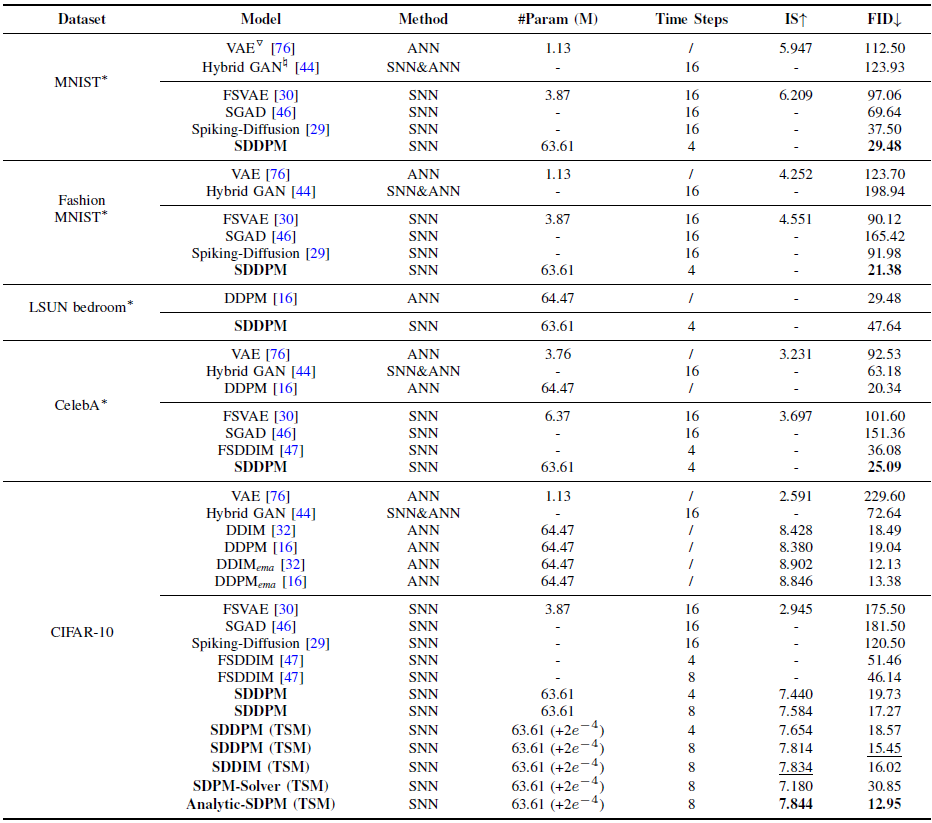
表 I 不同数据集的结果。
- 在所有数据集中,SDMs(我们的方法)在样本质量方面超越了所有 SNN 基线,甚至超越了一些 ANN 模型,质量主要通过 FID 和 IS 来衡量。
- ▽ 的结果取自[30],♮ 的结果取自 [46]。
- EMA 表示使用了 EMA [75] 方法。
- 为了公平比较,我们使用与 SDMs 相同的 UNet 架构重新评估了 DDPM [16] 和 DDIM [32] 的结果。
- * 表示仅使用 FID 来评估 MNIST、Fashion-MNIST 和 CelebA,因为它们的数据分布远离 ImageNet,使得 Inception Score 的意义较小。
- Top-1 和 Top-2 的结果分别用粗体和下划线标出。
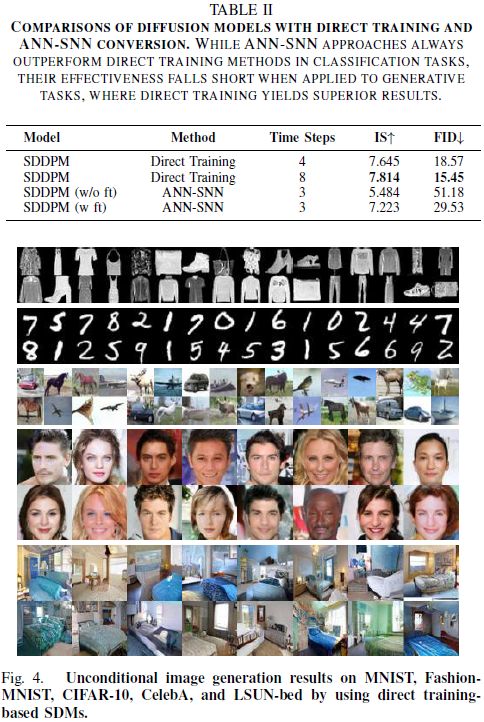
8. 讨论与结论
在本研究中,我们提出了一种基于 SNN 的新型扩散模型家族——脉冲扩散模型(SDMs),它将 SNN 的能效与卓越的生成性能相结合。SDMs 在 SNN 基线模型中以较少的脉冲时间步数实现了最先进的结果,并且与 ANN 相比,达到了较低能耗下的竞争性结果。SDMs 主要受益于两个方面:(1)时间维脉冲机制(TSM),使去噪网络 SNN-UNet 的突触电流能够在每个时间步收集更多的动态信息,而不是像传统 SNN 那样受固定突触权重的支配;(2)无训练阈值引导(TG),通过调整脉冲阈值进一步提高采样质量。然而,我们工作的一个局限性是 SNN-UNet 的时间步较小,尚未充分挖掘 SDMs 的全部潜力。此外,未来应该考虑在更高分辨率的数据集(例如 ImageNet)上进行测试。未来的研究中,我们计划进一步探索 SDMs 在生成领域的应用,例如文本图像生成,并尝试将其与先进的语言模型结合,以实现更有趣的任务。
论文地址:https://arxiv.org/abs/2408.16467
项目页面:https://github.com/AndyCao1125/SDM
公号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
加 VX 群请备注学校 / 单位 + 研究方向
CV 进计算机视觉群
KAN 进 KAN 群

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









