







Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling

目录
1. 引言
本文提出了 Janus 的增强版本 Janus-Pro,旨在提升多模态理解和文本生成图像的能力。Janus-Pro 在三个维度上进行了改进:训练策略、数据扩展和模型规模扩展。与 Janus 相比,Janus-Pro 不仅显著提升了模型在理解和生成任务上的表现,还增强了文本生成图像的稳定性。
采用统一视觉编码策略,会在理解和生成任务中存在目标冲突,导致性能下降。为解决此问题,Janus 首创了解耦视觉编码机制。Janus-Pro 在此基础上进一步优化,扩展了训练数据和模型规模。
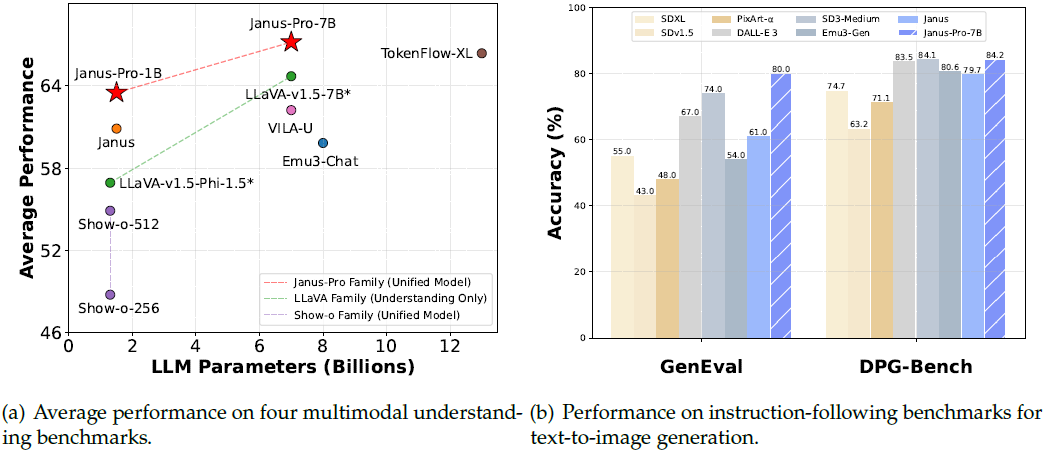
图 1:Janus-Pro 的多模态理解与视觉生成结果。
- 在多模态理解任务(a)中,我们对 POPE、MME-Perception、GQA 和 MMMU 四个基准的准确率取平均值。其中,MME-Perception 的得分被除以 20,以统一缩放至 [0, 100] 区间。
- 在视觉生成(b)方面,我们基于两个文本生成图像的指令跟随基准(GenEval 和 DPG-Bench)对模型进行评估。
- 总体来看,Janus-Pro 的性能优于以往的统一多模态模型以及部分专用任务模型。

2. 方法
2.1 架构
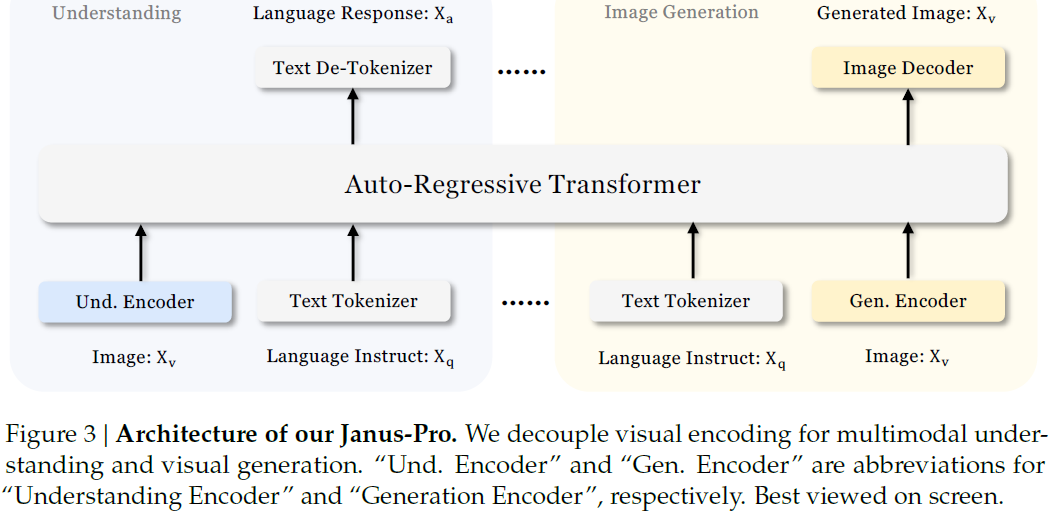
(2024|DeepSeek,为理解与生成设计独立的视觉编码路径)Janus:解耦视觉编码以实现统一的多模态理解和生成
Janus-Pro 延续了 Janus 的核心架构设计,即将多模态理解与图像生成的视觉编码过程进行解耦。整体流程如下:
-
图像理解任务使用 SigLIP 编码器(Und. Encoder)将图像转化为高维语义特征,再通过 “理解适配器(understanding adaptor)” 将其映射到语言模型(LLM)的输入空间。
-
图像生成任务采用 VQ Tokenizer (Gen. Encoder)将图像编码为离散 ID 序列,再通过 “生成适配器(generation adaptor)” 将其嵌入至 LLM 的输入空间。
-
最终,所有特征(包括图像特征和文本 token)拼接为统一的多模态序列,输入至一个自回归 Transformer 中。
-
模型包含两个预测头:一个是 LLM 内建的语言预测头,另一个为图像预测任务专设的随机初始化预测头。
该架构既保持统一模型处理多任务,又通过编码器解耦避免了任务冲突。
2.2 优化训练策略
原始 Janus 使用三阶段训练流程,但存在第二阶段训练效率低下的问题,Janus-Pro 进行了以下优化:
阶段 I:延长训练步数
-
在 ImageNet 上更充分地训练适配器与图像生成头,即便冻结 LLM 参数,也能有效建立图像类别与图像之间的像素关系。
阶段 II:聚焦真实文本到图像数据
-
舍弃了 ImageNet 数据,直接使用常规的文本到图像数据,训练模型根据更丰富的文本描述生成图像。
-
这一重构的训练方式能更高效地利用文本到图像数据,从而提升训练效率与整体性能
阶段 III:调整监督微调数据比例
-
数据比例由原来的 “7:3:10(多模态理解:纯文本:图像生成)” 调整为 “5:1:4”。
-
减少图像生成数据占比,增强模型的理解能力同时仍保持生成性能。
2.3 数据扩展
Janus-Pro 在数据层面进行了显著扩展:
多模态理解数据扩展:
-
在第二阶段预训练中,引入了 DeepSeek-VL2 的约 9000 万样本:包括 YFCC 图像标题(caption)数据集、Docmatix 文档理解、表格与图表数据等。
-
在第三阶段监督微调中,新增:MEME 理解数据、中文对话数据、提升对话体验的数据集等。
-
整体提升了模型的语义理解、多语言支持与任务泛化能力。
图像生成数据扩展:
-
原 Janus 使用的真实数据含有噪声,导致图像生成质量不稳定。
-
Janus-Pro 引入约 7200 万合成美学数据(如 MidJourney prompt 数据集),真实与合成数据比例调整为 1:1。
-
合成数据质量高、标注准确,有助于:模型更快收敛;输出图像更加稳定、美观,提升整体视觉体验。
2.4 模型扩展
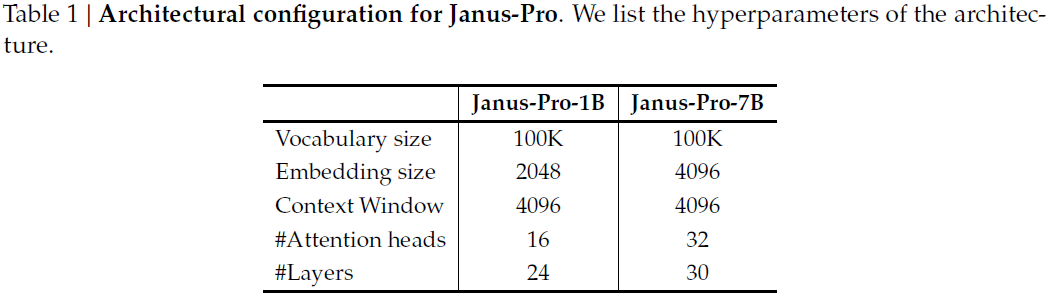
Janus 使用一个 1.5B 参数的大语言模型(LLM)验证了视觉编码解耦方法的有效性。在 Janus-Pro 中,将模型扩展至 7B 参数,并在表 1 中列出了 1.5B 和 7B 参数模型的超参数配置。
观察到,在使用更大规模的语言模型时,无论是多模态理解还是图像生成任务,其损失函数的收敛速度相比小模型都有显著提升。这一发现进一步验证了该方法在模型扩展方面具有良好的可扩展性。
3. 实验
3.1 实现细节
基础模型为 DeepSeek-LLM(1.5B 和 7B),支持最大序列长度 4096。
用于理解任务的视觉编码器选择的是 SigLIP-Large-Patch16-384。图像生成任务中的生成编码器使用了一个大小为 16,384 的 codebook,并将图像下采样了 16 倍。理解适配器和生成适配器均为两层的 MLP。
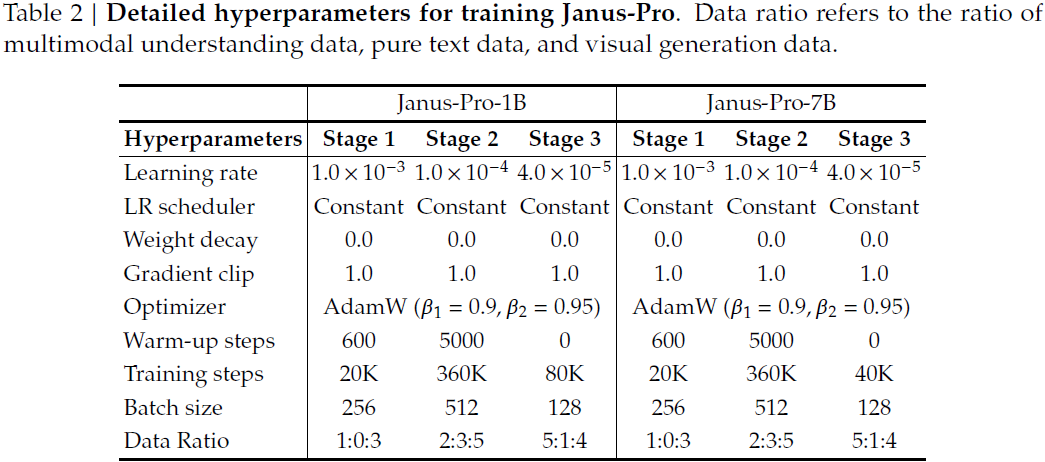
每个训练阶段的详细超参数配置见表 2。需要注意的是,在第二阶段训练中我们采用了 early stopping(提前停止)策略,在达到 270K 步时停止训练。
所有图像都被调整为 384 × 384 像素:
-
对于多模态理解数据,我们将图像的长边缩放至 384,短边使用背景色(RGB: 127, 127, 127)填充;
-
对于图像生成数据,则将短边缩放至 384,长边裁剪为 384。
训练过程中,使用 序列打包(sequence packing)来提高训练效率,并在每个训练步骤中按照预设比例混合所有数据类型。
Janus-Pro 的训练和评估基于 HAI-LLM 平台完成,该平台是构建在 PyTorch 之上的高效轻量级分布式训练框架。整个训练过程耗时如下:
-
1.5B 模型在 16 节点上训练约 9 天;
-
7B 模型在 32 节点上训练约 14 天;
- 每个节点配备 8 张 Nvidia A100(40GB)GPU。
3.2 评估设置
多模态理解:使用 GQA、POPE、MME、SEED、MMBench、MM-Vet、MMMU 等主流数据集。
图像生成:采用 GenEval 和 DPG-Bench,分别考察模型的组合生成能力与复杂指令对齐能力。
3.3 与现有方法的对比
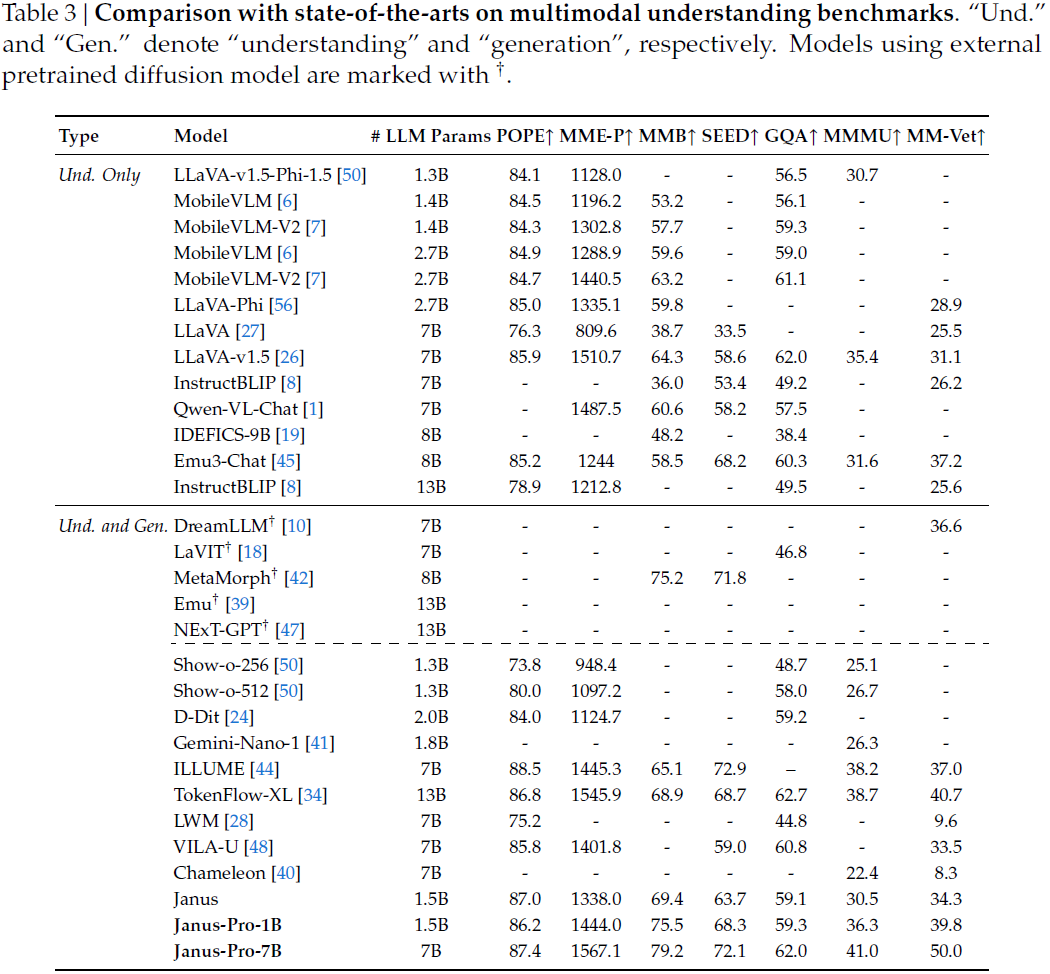
多模态理解:Janus-Pro-7B 在七项指标中有六项领先。相比 TokenFlow-XL(13B),在几乎所有任务上表现更优,显示出模型设计和训练策略的先进性。
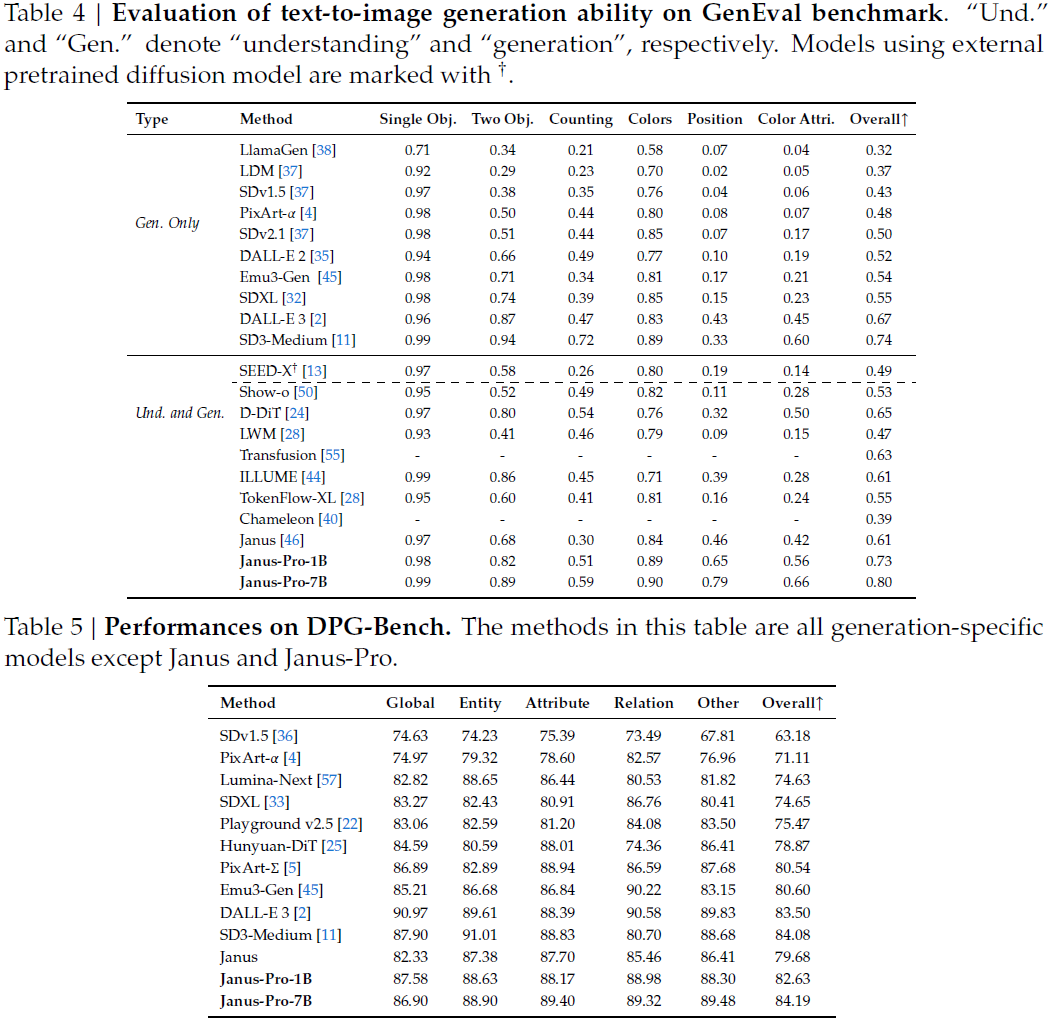
图像生成:
- 在 GenEval 上,Janus-Pro-7B 得分 0.80,优于 SD3-Medium(0.74)和 DALL-E 3(0.67)。
- 在 DPG-Bench 上,得分 84.19,领先所有比较模型,包括专为生成设计的模型。
3.4 定性结果
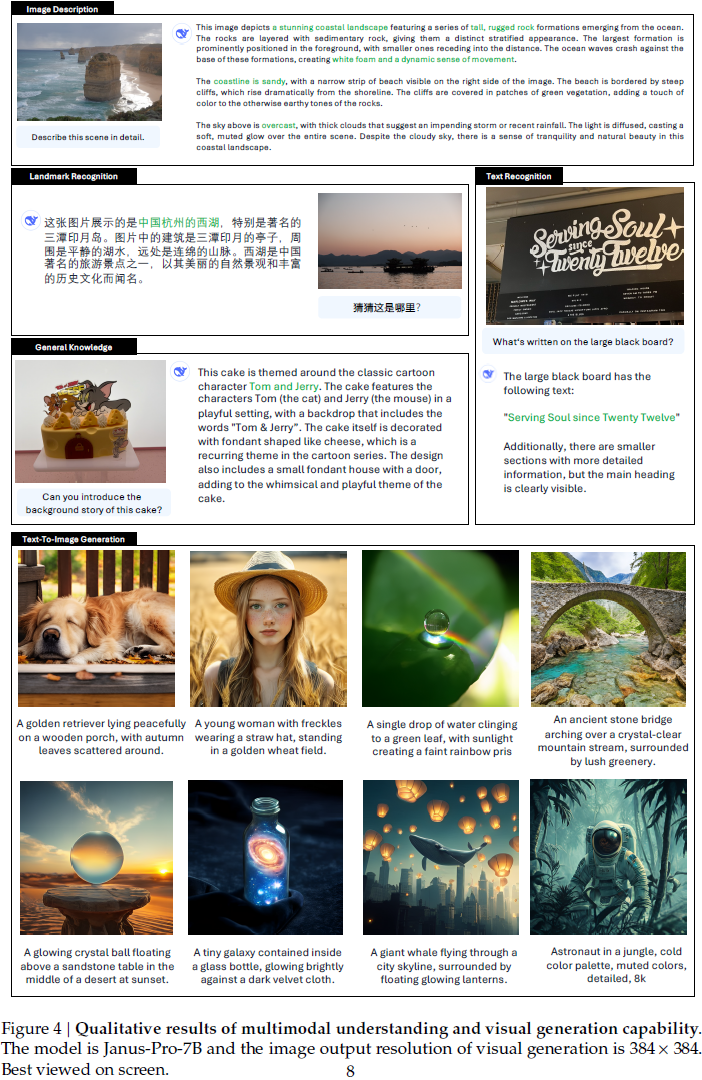
图像理解方面,Janus-Pro-7B 能准确解析场景、文本和文化背景;
图像生成方面,生成图像在低分辨率下仍保持良好的细节和美感,展现出较强的想象力与语义对齐能力,适用于现实与虚构场景的构建。
4. 结论
Janus-Pro 在 Janus 的基础上从训练策略、数据质量与数量、模型规模三个方向系统升级,显著提升了多模态理解与文本图像生成能力。特别是在多个基准任务中取得领先成绩,验证了其方法的有效性。
然而,该模型仍存在图像输入分辨率受限、细节保真度不足等问题,未来可通过提升图像分辨率与改进编码器进一步优化生成质量。
论文地址:https://arxiv.org/abs/2501.17811
项目页面:https://github.com/deepseek-ai/Janus
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群

















 3472
3472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









