







文献阅读:Unsupervised Label Noise Modeling and Loss Correction
Abstract
- CNN网络一般有这个性质,在面对有噪声的数据时,一般先拟合干净数据,再拟合噪声数据。
- 基于每个样本的简单但有效的无监督噪声标签建模。
- 一种损失校正方法,利用无监督标签噪声模型来校正每个样本损失,从而防止对标签噪声的过度拟合。
- 加入一个混合增强模型能够更一步提高精度
一般的分类损失
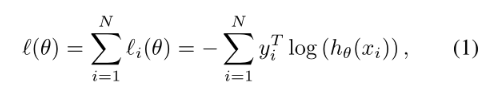
1.随机的标签比干净的标签训练时间更长。
2.并且随机的标签在刚开始训练的时候有更大的损失。
混合模型是一种广泛使用的无监督建模技术

高斯分布对干净集分布的近似很差,Clean集表现出向零的高度偏斜。β混合模型(BMM)更好地近似了干净样本和噪声样本混合物的损失分布(图2)。
通俗来说:
第一步:通过cross-entropy得到的loss分布来判断样本是noisy还是clean的概率
第二步:使用这个概率来动态地调整loss function,使用该loss来训练
使用BMM来建模,也就是贝塔混合模型
K=2, 也就是有两种情况,一个是干净的标签,一个是噪声标签。


总体的混合分布如上,我们给定每个 k 的贝塔参数和 loss 值,就可以得到这个 loss 值对应的总体的分布了:
当我们赋予这个BMM初始的 α 和 β 值后,如何根据观测到的损失值更新这两个值呢?
这里我们就有一种EM算法,来专门拟合这种含有隐变量的概率分布问题:
E-STEP
- 表示出后验分布,也就是给定loss, 判断这个loss是属于clean-label还是noisy-label
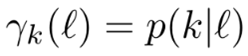

M-STEP
估计分布参数
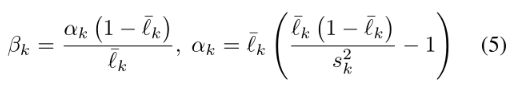
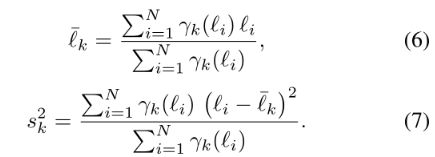
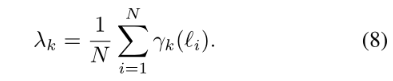

然后重复上述E和M步骤,直到达到收敛或最大迭代次数
k=0(1) 分别代表干净(噪声样本)
直接使用分类损失会导致病态的拟合,因为它拟合了噪音标签。
所以采用static hard bootstrapping, 它可以通过添加一个额外的项去处理噪音标签。(模型预测zi,softmax probabilities hi)
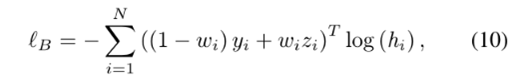
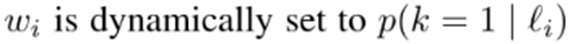
- 干净的样本依赖于它们的真值标签yi(1−wi较大)
- 而有噪声的样本则让它们的损失由它们的类别预测zi(wi较大)
混淆数据增强

混淆机制和bootstrapping结合
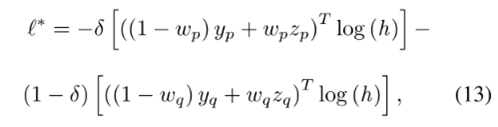

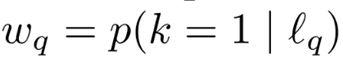
这种组合使网络正则化,并且远离了振荡。这种组合提供了一种组合干净和噪声样本的机制。即使这两个组合的情况都是噪声,也有效,因为这是两组数据融合,一组数据的标签可能就是另一组数据的标签。并且这种机制能够防止对噪音数据的过拟合。
在高噪声的情况下,我们得到的两组混淆数据都存在噪声是普遍的情况。所以我们将混淆机制和bootstrapping融合。这可以利用两者的好处:
mixup:使得网络正则化,远离震荡。
bootstrapping:加入了网络自己预测的标签,可以改善随机选取的两组数据都是噪声的情况。
防止网络倾向于预测相同的标签
在高噪声水平下,大多数样本由网络在损失中的预测引导,鼓励网络预测相同的类别以最小化损失。使用正则化项去避免这种情况
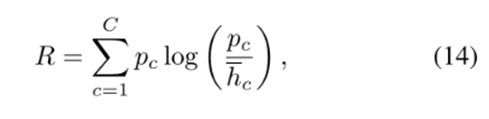
pc表示c类的先验概率分布, 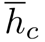 是数据集中所有样本中c类模型的平均软最大概率。Pc = 1 / C
是数据集中所有样本中c类模型的平均软最大概率。Pc = 1 / C
Experiment

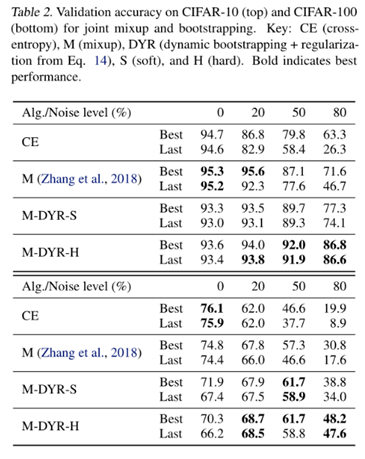

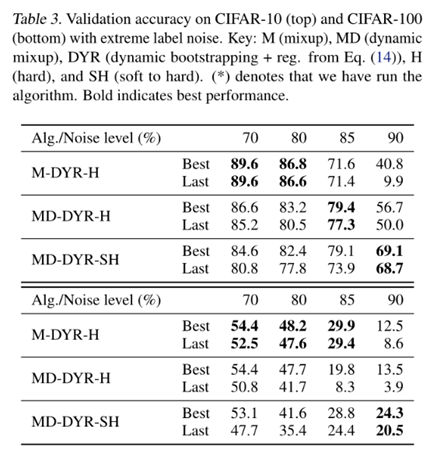
在高水平的标签噪声下的hard bootstrapping会导致损耗的巨大变化,从而导致性能下降。
通过修改以下内容中的软最高温度T来实现SH,线性地降低hp和hq的温度
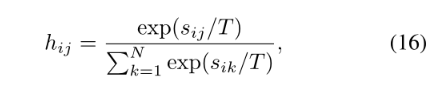
sij表示在样本xi的CNN模型j类的最后一层中获得的分数















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









