






文章目录
D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction
论文
Abstract
Road extraction is a fundamental task in the field of remote sensing which has been a hot research topic in the past decade. In this paper, we propose a semantic segmentation neural network, named D-LinkNet, which adopts encoderdecoder structure, dilated convolution and pretrained encoder for road extraction task. The network is built with LinkNet architecture and has dilated convolution layers in its center part. Linknet architecture is efficient in computation and memory. Dilation convolution is a powerful tool that can enlarge the receptive field of feature points without reducing the resolution of the feature maps. In the CVPR DeepGlobe 2018 Road Extraction Challenge, our best IoU scores on the validation set and the test set are 0.6466 and 0.6342 respectively.
point
1、道路提取是遥感领域研究热点
2、基于LinkNet提出D-LinkNet模型,模型以空洞卷积作为改进方式
3、在CVPR DeepGlobe 2018道路提取挑战赛中去的较好成绩
1. Introduction
Road extraction from satellite images has been a hot research topic in the past decade. It has a wide range of applications such as automated crisis response, road map updating, city planning, geographic information updating, car navigations, etc. In the field of satellite image road extraction, a variety of methods have been proposed in recent years. Most of these methods can be seperated into three categories: generating pixel-level labeling of roads [1, 2], detecting skeletons of roads [3, 4] and a combination of both [5, 6].
In the DeepGlobe Road Extraction Challenge [7], the task of road extraction from satellite images was formulated as a binary classification problem: to label each pixel as road or non-road. In this paper, we handling the road extraction task as a binary semantic segmentation task to generate pixel-level labeling of roads,.
Recently, deep convolutional neural networks (DCNN) [8, 9, 10, 11] have shown their dominance on many visual recognition tasks. In the field of image semantic segmentation, fully-convolutional network (FCN) [12] architecture, which can produce a segmentation map for an entire input image through single forward pass, is prevalent. Most latest excellent semantic segmentation networks [13, 14, 15, 16] are improved versions of FCN.
Several previous works have applied deep learning to road segmentation task. Mnih and Hinton [17] employed restricted Boltzmann machines to segment road from high resolution aerial images. Saito et al [18] used a classification network to assign each patch extracted from the whole image as road, building or background. Zhang et al [1] followed the FCN architecture and employed a Unet with residual connections to segment roads from one image through single forward pass. In this paper, we follow these methods, using DCNN to handle road segmentation task.
Although has been extensively studied in the past years, road segmentation from high resolution satellite images is still a challenging task due to some special features of the task. First, the input images are of high-resolution, so networks for this task should have large receptive field that can cover the whole image. Second, roads in satellite images are often slender, complex and cover a small part of the whole image. In this case, preserving the detailed spacial information is significant. Third, roads have natural connectivity and long span. Taking these natural properties of roads in consideration is necessary. Based on the challenges discussed above, we propose a semantic segmentation network, named D-LinkNet, which can properly handle these challenges.
D-LinkNet uses Linknet [15] with pretrained encoder as its backbone and has additional dilated convolution layers in the center part. Linknet is an efficient semantic segmentation neural network which takes the advantages of skip connections, residual blocks [10] and encoder-decoder architecture. The original Linknet uses ResNet18 as its encoder, which is a pretty light but outperforming network. Linknet has shown high precision on several benchmarks [19, 20], and it runs pretty fast.
Dilated convolution is a useful kernel to adjust receptive fields of feature points without decreasing the resolution of feature maps. It was widely used recently, and it generally has two types, cascade mode like [21] and parallel mode like [16], both modes have shown strong ability to increase the segmentation accuracy. We take advatages of both modes, using shortcut connection to combine these two modes.
Transfer learning is a useful method that can directly improve network preformance in most situation [22], especiall when the training data is limited. In semantic segmantation field, initializing encoders with ImageNet [23] pretrained weights has shown promissing results [16, 24].
In the DeepGlobe Road Extraction Challenge, our best single model got IoU score of 0.6412 on the validation set.
point
1、道路提取是热门研究,现存方法主要包括像素分割、骨架检测及两者结合
2、DeepGlobe道路提取挑战赛为像素分割模式
3、FCN是语义分割的奠基之作
4、当前研究广泛但是存在以下挑战:图像分辨率高,感受野应尽可能大;道路修长且复杂,所占图幅小。
5、D-LinkNet基于LinkNet,在编解码器的bridge中放入额外的空洞卷积层
6、空洞卷积包括两种模式:串联和并联,D-LinkNet将两者结合提出一种串并联式
7、使用了预训练权重,最好模型在验证机上获得0.64IoU
2. Method
2.1. Network Architecture
In the DeepGlobe Road Extraction Challenge, the original size of the provided images and masks is 1024 × 1024, and the roads in most images span the whole image. Still, roads have some natural properties such as connectivity, complexity et al Considering these properties, D-LinkNet is designed to receive 1024 × 1024 images as input and preserve detailed spacial information. As shown in Figure 1, D-LinkNet can be split in three parts A, B, C, named encoder, center part and decoder respectively.
D-LinkNet uses ResNet34 [10] pretrained on ImageNet [23] dataset as its encoder. ResNet34 is originally designed for classification task on mid-resolution images of size 256 × 256, but in this challenge, the task is to segment roads from high-resolution satellite images of size 1024 × 1024. Considering the narrowness, connectivity, complexity and long span of roads, it is important to increase the receptive field of feature points in the center part of the network as well as keep the detailed information.Using pooling layers could multiply increase the receptive field of feature points, but may reduce the resolution of center feature maps and drop spacial information. As shown by some state-of-the-art deep learning models [21, 25, 26, 16],dilated convolution layer can be desirable alternative of pooling layer. D-LinkNet uses several dilated convolution layers with skip connections in the center part.
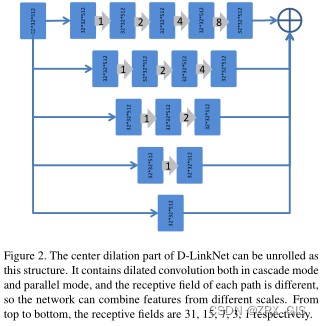
Dilated convolution can be stacked in cascade mode. As shown in the Figure1 of [21], if the dilation rates of the stacked dilated convolution layers are 1, 2, 4, 8, 16 respectively, then the receptive field of each layer will be 3, 7, 15, 31, 63. The encoder part (RseNet34) has 5 downsampling layers, if an image of size 1024 × 1024 go through the encoder part, the output feature map will be of size 32 × 32.
In this case, D-LinkNet uses dilated convolution layers with dilation rate of 1, 2, 4, 8 in the center part, so the feature points on the last center layer will see 31 × 31 points on the first center feature map, covering main part of the first center feature map. Still, D-LinkNet takes the advantage of multi-resolution features, and the center part of D-LinkNet can be viewed as the parallel mode as shown in Figure 2.
The decoder of D-LinkNet remains the same as the original LinkNet [15], which is computationally efficient. The decoder part uses transposed convolution [27] layers to do upsampling, restoring the resolution of feature map from 32 × 32 to 1024 × 1024.
point
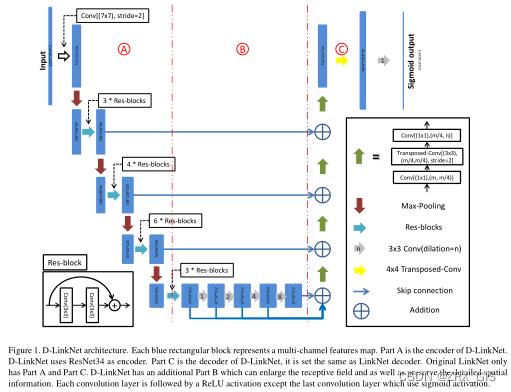
这里我们直接用原文的结构图来谈一下D-LinkNet。首先,这个网络的设计是为了更好提取特定数据集,因此在输入尺寸上做了调整,其次网络基础来自于LinkNet,LinkNet是一个较为经典的定量级网络,效果整体还可以,因此有选取的意义。
我们看下D-LinkNet的结构,按照文中划分方式,整体网络可以看做A、B、C三部分,A和C其实就是LinkNet的编解码器,而中间的B则是文中之前提到的,结合串联和并联的空洞卷积块提出的兼顾串并方式的空洞卷积块。整体结构较为简单,其实就是将能拼接上的模块都进行了一定的尝试,在A中通过残差模块减少前向传播过程中的特征损失;B中通过空洞卷积尽可能融合更多尺度的特征;C中结合A对应的层级来逐级恢复图像尺寸,最终实现端到端、像素到像素的特征传递方式。
2.2. Pretrained Encoder
Transfer learning is an efficient method for computer vision, especially when the number of training images is limited. Using ImageNet [23] pretrained model to be the encoder of the network is a method widely used in semantic segmentation field [16, 24]. In the DeepGlobe Road Extraction Challenge, we found that transfer learning can accelerate our network convergence and make it have better performance with almost no extra cost.
point
使用ImageNet得到的预训练权重来加快网络收敛速度
3. Experiments
In the DeepGlobe Road Extraction Challenge. We use PyTorch [28] as the deep learning framework. All models are trained on 4 NVIDIA GTX1080 GPUs.
3.1. Dataset
We test our method on DeepGlobe Road Extraction dataset [7], which consists of 6226 training images, 1243 validation images and 1101 test images. The resolution of each image is 1024 × 1024. The dataset is formulated as a binary segmentation problem, in which roads are labeled as foreground and other objects are labeled as background.
point
DeepGlobe Road Extraction数据集,6226张训练图像、1243张验证图像和1101张测试图像。
3.2. Implementation details
In the training phase, we did not use cross validation1.
Still, we wanted to make full use of the provided data, so we trained our model on all of the 6226 labeled images, and only used the 1243 validation images provided by the organizer for validation. This may be at the risk of overfiting on the training set, so we did data augmentation in an ambitious way, including horizontal flip, vertical flip, diagonal flip, ambitious color jittering, image shifting, scaling.
For our best model, we used BCE (binary cross entropy) + dice coefficient loss as loss function and chose Adam [29] as our optimizer. The learning rate was originally set 2e-4, and reduced by 5 for 3 times while observing the training loss decreasing slowly. The batch size during training phase was fixed as 4. It took about 160 epochs for our network to converge.
We did test time augmentation(TTA) in the predicting phase, including image horizontal flip, image vertical flip, image diagonal flip (predicting each image 2 × 2 × 2 = 8 times), and then restored the outputs to the match the origin images. Then, we averaged the prob of each prediction, using 0.5 as our prediction threshold to generate binary outputs.
3.3. Results
During the DeepGlobe Road Extraction Challenge, we trained a deep Unet with 7 pooling layers, which can cover images of size 1024 × 1024, as our baseline model, and trained a LinkNet34 with pretrained encoder but without dilated convolution in the center part. The performances of different model are shown in Table 1. We found that the pretrained LinkNet34 was just a little bit better than the Unet trained from scratch. We evaluated the IoU of masks predicted by Unet and masks predicted by LinkNet34, and found that on the validation set, the averaged IoU of these two models was 0.785, which we considered as a pretty low score. We thought these two models might get almost the same score in different ways. Our baseline Unet had larger receptive field but had no pretrained encoder and the center feature map’s resolution was 8 × 8, which is too small to preserve detailed spacial information. LinkNet34 had pretrained encoder which made the network has better representation, but it only had 5 downsampling layers, hardly covering the 1024 × 1024 images. While reviewing the outputs from these two models, we found that although LinkNet34 was better than Unet while judging an object to be road or not, it had road connectivity problem. Some examples are shown in Figure 3. By adding dilated convolution with shortcuts in the center part, D-LinkNet can obtain larger receptive field than LinkNet as well as preserve detailed information at the same time, and thus alleviated the road connectivity problem occurred in LinkNet34.


3.4. Analysis
We used several methods during the DeepGlobe Road Extraction Challenge, and we have done several experiments to find the contribution of each method. The most contributing method is test time augmentation(TTA), it contributes about 0.029 points. Using BCE + dice coefficient loss is better than BCE + IoU loss about 0.005 points. Pretrained encoder contributes about 0.01 points. Dilated convolution in the center part contributes about 0.011 points.Ambitious data augmentation is better than normal data augmentation without color jittering and shape transfromation about 0.01 points.
4. Conclusion
In this paper, we have proposed a semantic segmentation network, named D-LinkNet, for high resolution satellite imagery road extraction. By enlarging the receptive field and ensembling multi-scale features in the center part while keeping the detailed information at the same time, D-LinkNet can handle roads’ properties such as narrowness, connectivity, complexity and long span to some extent. However, D-LinkNet still has the wrong recognition and road connectivity problems, we plan to do more research on these problems in the feature.
In addition, although the proposed D-LinkNet architecture was originally designed for the road segmentation task, we anticipate it may also be useful in other segmentation tasks, and we plan to investigate this in our future research.
代码
关于本文的代码,算法模型一共声明了8个类,其中包括3个基础模块和5个网络模型,我们分别学习一下。
Dblock_more_dilate
该类是定义的一种空洞卷积块,对应文中的B模块,该部分定义了5个不同空洞率的空洞卷积,空洞率分别是1,2,4,8,16,然后按大小次序让特征图依次处理,最后把包括原特征图在内的每层输出直接相加。
该模块被设置到DinkNet34_less_pool、DinkNet50、DinkNet101中。
class Dblock_more_dilate(nn.Module):
def __init__(self, channel):
super(Dblock_more_dilate, self).__init__()
self.dilate1 = nn.Conv2d(channel, channel, kernel_size=3, dilation=1, padding=1)
self.dilate2 = nn.Conv2d(channel, channel, kernel_size=3, dilation=2, padding=2)
self.dilate3 = nn.Conv2d(channel, channel, kernel_size=3, dilation=4, padding=4)
self.dilate4 = nn.Conv2d(channel, channel, kernel_size=3, dilation=8, padding=8)
self.dilate5 = nn.Conv2d(channel, channel, kernel_size=3, dilation=16, padding=16)
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
dilate1_out = nonlinearity(self.dilate1(x))
dilate2_out = nonlinearity(self.dilate2(dilate1_out))
dilate3_out = nonlinearity(self.dilate3(dilate2_out))
dilate4_out = nonlinearity(self.dilate4(dilate3_out))
dilate5_out = nonlinearity(self.dilate5(dilate4_out))
out = x + dilate1_out + dilate2_out + dilate3_out + dilate4_out + dilate5_out
return out
Dblock
该类也是定义的一种空洞卷积块,对应文中的B模块,但是与Dblock_more_dilate不同的是,该部分定义了4个不同空洞率的空洞卷积,空洞率分别是1,2,4,8,然后按大小次序让特征图依次处理,最后把包括原特征图在内的每层输出直接相加。
该模块被设置到DinkNet34中。
class Dblock(nn.Module):
def __init__(self, channel):
super(Dblock, self).__init__()
self.dilate1 = nn.Conv2d(channel, channel, kernel_size=3, dilation=1, padding=1)
self.dilate2 = nn.Conv2d(channel, channel, kernel_size=3, dilation=2, padding=2)
self.dilate3 = nn.Conv2d(channel, channel, kernel_size=3, dilation=4, padding=4)
self.dilate4 = nn.Conv2d(channel, channel, kernel_size=3, dilation=8, padding=8)
# self.dilate5 = nn.Conv2d(channel, channel, kernel_size=3, dilation=16, padding=16)
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
dilate1_out = nonlinearity(self.dilate1(x))
dilate2_out = nonlinearity(self.dilate2(dilate1_out))
dilate3_out = nonlinearity(self.dilate3(dilate2_out))
dilate4_out = nonlinearity(self.dilate4(dilate3_out))
# dilate5_out = nonlinearity(self.dilate5(dilate4_out))
out = x + dilate1_out + dilate2_out + dilate3_out + dilate4_out # + dilate5_out
return out
DecoderBlock
该类也是定义的是解码器各层,对应文中c,结构上为conv-bn-relu-deconv-bn-relu-conv-bn-relu
class DecoderBlock(nn.Module):
def __init__(self, in_channels, n_filters):
super(DecoderBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels // 4, 1)
self.norm1 = nn.BatchNorm2d(in_channels // 4)
self.relu1 = nonlinearity
self.deconv2 = nn.ConvTranspose2d(in_channels // 4, in_channels // 4, 3, stride=2, padding=1, output_padding=1)
self.norm2 = nn.BatchNorm2d(in_channels // 4)
self.relu2 = nonlinearity
self.conv3 = nn.Conv2d(in_channels // 4, n_filters, 1)
self.norm3 = nn.BatchNorm2d(n_filters)
self.relu3 = nonlinearity
def forward(self, x):
x = self.conv1(x)
x = self.norm1(x)
x = self.relu1(x)
x = self.deconv2(x)
x = self.norm2(x)
x = self.relu2(x)
x = self.conv3(x)
x = self.norm3(x)
x = self.relu3(x)
return x
网络结构定义,没有过多说的,就是模块堆叠,在编码器处调用LinkNet
Net
class DinkNet34_less_pool(nn.Module):
def __init__(self, num_classes=1):
super(DinkNet34_less_pool, self).__init__()
filters = [64, 128, 256, 512]
resnet = models.resnet34(pretrained=True)
self.firstconv = resnet.conv1
self.firstbn = resnet.bn1
self.firstrelu = resnet.relu
self.firstmaxpool = resnet.maxpool
self.encoder1 = resnet.layer1
self.encoder2 = resnet.layer2
self.encoder3 = resnet.layer3
self.dblock = Dblock_more_dilate(256)
self.decoder3 = DecoderBlock(filters[2], filters[1])
self.decoder2 = DecoderBlock(filters[1], filters[0])
self.decoder1 = DecoderBlock(filters[0], filters[0])
self.finaldeconv1 = nn.ConvTranspose2d(filters[0], 32, 4, 2, 1)
self.finalrelu1 = nonlinearity
self.finalconv2 = nn.Conv2d(32, 32, 3, padding=1)
self.finalrelu2 = nonlinearity
self.finalconv3 = nn.Conv2d(32, num_classes, 3, padding=1)
def forward(self, x):
# Encoder
x = self.firstconv(x)
x = self.firstbn(x)
x = self.firstrelu(x)
x = self.firstmaxpool(x)
e1 = self.encoder1(x)
e2 = self.encoder2(e1)
e3 = self.encoder3(e2)
# Center
e3 = self.dblock(e3)
# Decoder
d3 = self.decoder3(e3) + e2
d2 = self.decoder2(d3) + e1
d1 = self.decoder1(d2)
# Final Classification
out = self.finaldeconv1(d1)
out = self.finalrelu1(out)
out = self.finalconv2(out)
out = self.finalrelu2(out)
out = self.finalconv3(out)
return torch.sigmoid(out)
# return F.sigmoid(out)
class DinkNet34(nn.Module):
def __init__(self, num_classes=1, num_channels=3):
super(DinkNet34, self).__init__()
filters = [64, 128, 256, 512]
resnet = models.resnet34(pretrained=True)
self.firstconv = resnet.conv1
self.firstbn = resnet.bn1
self.firstrelu = resnet.relu
self.firstmaxpool = resnet.maxpool
self.encoder1 = resnet.layer1
self.encoder2 = resnet.layer2
self.encoder3 = resnet.layer3
self.encoder4 = resnet.layer4
self.dblock = Dblock(512)
self.decoder4 = DecoderBlock(filters[3], filters[2])
self.decoder3 = DecoderBlock(filters[2], filters[1])
self.decoder2 = DecoderBlock(filters[1], filters[0])
self.decoder1 = DecoderBlock(filters[0], filters[0])
self.finaldeconv1 = nn.ConvTranspose2d(filters[0], 32, 4, 2, 1)
self.finalrelu1 = nonlinearity
self.finalconv2 = nn.Conv2d(32, 32, 3, padding=1)
self.finalrelu2 = nonlinearity
self.finalconv3 = nn.Conv2d(32, num_classes, 3, padding=1)
def forward(self, x):
# Encoder
x = self.firstconv(x)
x = self.firstbn(x)
x = self.firstrelu(x)
x = self.firstmaxpool(x)
e1 = self.encoder1(x)
e2 = self.encoder2(e1)
e3 = self.encoder3(e2)
e4 = self.encoder4(e3)
# Center
e4 = self.dblock(e4)
# Decoder
d4 = self.decoder4(e4) + e3
d3 = self.decoder3(d4) + e2
d2 = self.decoder2(d3) + e1
d1 = self.decoder1(d2)
out = self.finaldeconv1(d1)
out = self.finalrelu1(out)
out = self.finalconv2(out)
out = self.finalrelu2(out)
out = self.finalconv3(out)
return torch.sigmoid(out)
# return F.sigmoid(out)
class DinkNet50(nn.Module):
def __init__(self, num_classes=1):
super(DinkNet50, self).__init__()
filters = [256, 512, 1024, 2048]
resnet = models.resnet50(pretrained=True)
self.firstconv = resnet.conv1
self.firstbn = resnet.bn1
self.firstrelu = resnet.relu
self.firstmaxpool = resnet.maxpool
self.encoder1 = resnet.layer1
self.encoder2 = resnet.layer2
self.encoder3 = resnet.layer3
self.encoder4 = resnet.layer4
self.dblock = Dblock_more_dilate(2048)
self.decoder4 = DecoderBlock(filters[3], filters[2])
self.decoder3 = DecoderBlock(filters[2], filters[1])
self.decoder2 = DecoderBlock(filters[1], filters[0])
self.decoder1 = DecoderBlock(filters[0], filters[0])
self.finaldeconv1 = nn.ConvTranspose2d(filters[0], 32, 4, 2, 1)
self.finalrelu1 = nonlinearity
self.finalconv2 = nn.Conv2d(32, 32, 3, padding=1)
self.finalrelu2 = nonlinearity
self.finalconv3 = nn.Conv2d(32, num_classes, 3, padding=1)
def forward(self, x):
# Encoder
x = self.firstconv(x)
x = self.firstbn(x)
x = self.firstrelu(x)
x = self.firstmaxpool(x)
e1 = self.encoder1(x)
e2 = self.encoder2(e1)
e3 = self.encoder3(e2)
e4 = self.encoder4(e3)
# Center
e4 = self.dblock(e4)
# Decoder
d4 = self.decoder4(e4) + e3
d3 = self.decoder3(d4) + e2
d2 = self.decoder2(d3) + e1
d1 = self.decoder1(d2)
out = self.finaldeconv1(d1)
out = self.finalrelu1(out)
out = self.finalconv2(out)
out = self.finalrelu2(out)
out = self.finalconv3(out)
return torch.sigmoid(out)
# return F.sigmoid(out)
class DinkNet101(nn.Module):
def __init__(self, num_classes=1):
super(DinkNet101, self).__init__()
filters = [256, 512, 1024, 2048]
resnet = models.resnet101(pretrained=True)
self.firstconv = resnet.conv1
self.firstbn = resnet.bn1
self.firstrelu = resnet.relu
self.firstmaxpool = resnet.maxpool
self.encoder1 = resnet.layer1
self.encoder2 = resnet.layer2
self.encoder3 = resnet.layer3
self.encoder4 = resnet.layer4
self.dblock = Dblock_more_dilate(2048)
self.decoder4 = DecoderBlock(filters[3], filters[2])
self.decoder3 = DecoderBlock(filters[2], filters[1])
self.decoder2 = DecoderBlock(filters[1], filters[0])
self.decoder1 = DecoderBlock(filters[0], filters[0])
self.finaldeconv1 = nn.ConvTranspose2d(filters[0], 32, 4, 2, 1)
self.finalrelu1 = nonlinearity
self.finalconv2 = nn.Conv2d(32, 32, 3, padding=1)
self.finalrelu2 = nonlinearity
self.finalconv3 = nn.Conv2d(32, num_classes, 3, padding=1)
def forward(self, x):
# Encoder
x = self.firstconv(x)
x = self.firstbn(x)
x = self.firstrelu(x)
x = self.firstmaxpool(x)
e1 = self.encoder1(x)
e2 = self.encoder2(e1)
e3 = self.encoder3(e2)
e4 = self.encoder4(e3)
# Center
e4 = self.dblock(e4)
# Decoder
d4 = self.decoder4(e4) + e3
d3 = self.decoder3(d4) + e2
d2 = self.decoder2(d3) + e1
d1 = self.decoder1(d2)
out = self.finaldeconv1(d1)
out = self.finalrelu1(out)
out = self.finalconv2(out)
out = self.finalrelu2(out)
out = self.finalconv3(out)
return torch.sigmoid(out)
# return F.sigmoid(out)
class LinkNet34(nn.Module):
def __init__(self, num_classes=1):
super(LinkNet34, self).__init__()
filters = [64, 128, 256, 512]
resnet = models.resnet34(pretrained=True)
self.firstconv = resnet.conv1
self.firstbn = resnet.bn1
self.firstrelu = resnet.relu
self.firstmaxpool = resnet.maxpool
self.encoder1 = resnet.layer1
self.encoder2 = resnet.layer2
self.encoder3 = resnet.layer3
self.encoder4 = resnet.layer4
self.decoder4 = DecoderBlock(filters[3], filters[2])
self.decoder3 = DecoderBlock(filters[2], filters[1])
self.decoder2 = DecoderBlock(filters[1], filters[0])
self.decoder1 = DecoderBlock(filters[0], filters[0])
self.finaldeconv1 = nn.ConvTranspose2d(filters[0], 32, 3, stride=2)
self.finalrelu1 = nonlinearity
self.finalconv2 = nn.Conv2d(32, 32, 3)
self.finalrelu2 = nonlinearity
self.finalconv3 = nn.Conv2d(32, num_classes, 2, padding=1)
def forward(self, x):
# Encoder
x = self.firstconv(x)
x = self.firstbn(x)
x = self.firstrelu(x)
x = self.firstmaxpool(x)
e1 = self.encoder1(x)
e2 = self.encoder2(e1)
e3 = self.encoder3(e2)
e4 = self.encoder4(e3)
# Decoder
d4 = self.decoder4(e4) + e3
d3 = self.decoder3(d4) + e2
d2 = self.decoder2(d3) + e1
d1 = self.decoder1(d2)
out = self.finaldeconv1(d1)
out = self.finalrelu1(out)
out = self.finalconv2(out)
out = self.finalrelu2(out)
out = self.finalconv3(out)
return torch.sigmoid(out)
# return F.sigmoid(out)
















 4412
4412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











