







Geometry Uncertainty Projection Network for Monocular 3D Object Detection
论文链接:https://arxiv.org/pdf/2107.13774v2.pdf
代码链接:https://github.com/SuperMHP/GUPNet/tree/main
1 引言

现有方法通常预测物体在2D和3D空间中的高,在此基础上计算深度,这会导致小的高度误差会被放大,产生大的深度误差,如图1所示。图1是鸟瞰图视角,水平和竖直方向单位都是m,竖直方向是深度,其中绿色框是原始预测框,蓝色框和红色框分别是物体3D高度偏移 +0.1m 和 -0.1m 时的预测框,偏移了接近4m。

所以论文提出了 GUP Net,主要创新点有两个:一是Geometry Uncertainty Projection (GUP) module,预测深度分布而不是预测一个深度值(如图2所示),能够获得由几何引导的深度估计的不确定性,用于解决高度误差被放大的问题;二是Hierarchical Task Learning (HTL) strategy,用于解决训练过程不稳定的问题。
2 方法

GUP Net 的结构如图3所示,流程如下:
- 首先在输入图像上使用 2D 检测网络,得到预测边界框(ROI 区域),在此基础上,为每个边界框预测 3D 信息:角度、维度、3D 投影中心。
GUP模块结合数学先验和不确定性预测深度分布(预测深度值和对应的不确定性)。- 为了稳定训练前期,使用
HTL的学习策略。
2.1 2D检测
2D 检测用的是 CenterNet。如图3所示,CenterNet 使用骨干网络和3个检测头,预测了物体位置、尺度和置信度。热力图分支预测了维度
(
W
×
H
×
C
)
(W\times H\times C)
(W×H×C) 的热力图,
C
C
C 是类别数;2D 偏移量分支预测偏移量
(
δ
2
d
u
,
δ
2
d
v
)
(\delta^u_{2d},\delta^v_{2d})
(δ2du,δ2dv),将粗糙的中心位置细化;2D 尺度分支预测宽和高
(
w
2
d
,
h
2
d
)
(w_{2d},h_{2d})
(w2d,h2d),三个分支对应的损失函数分别为:
L
h
e
a
t
m
a
p
,
L
o
f
f
s
e
t
2
d
,
L
s
i
z
e
2
d
L_{heatmap},L_{offset2d},L_{size2d}
Lheatmap,Loffset2d,Lsize2d.
2.2 提取ROI特征
对ROI区域裁剪和缩放后用ROIAlign方法提取 ROI 特征,ROIAlign可以参考 https://zhuanlan.zhihu.com/p/73113289,由于缩放失去了尺度信息,所以计算出normalized coordinate map并和每个ROI特征在通道维度进行拼接,如图3所示。
2.3 基本3D检测头
在2.2节得到的 ROI 特征上预测 3D 信息:3D 偏移分支预测 3D 中心在 2D 特征图上的投影与 2D 中心的偏移;角度分支预测观测角(用 https://arxiv.org/pdf/1612.00496v2.pdf 的方法);尺度分支预测 3D 物体的高宽长 (高预测的是分布,见2.4节)。三个分支的损失函数分别为:
L
o
f
f
s
e
t
3
d
,
L
a
n
g
l
e
,
L
s
i
z
e
3
d
L_{offset3d},L_{angle},L_{size3d}
Loffset3d,Langle,Lsize3d.
2.4 Geometry Uncertainty Projection
目的:预测深度的分布而不是单个深度值,这可以推断不确定性,能表示可靠性同时有利于深度估计的学习。
假设每个物体 3D 高度的预测服从拉普拉斯分布
L
a
(
μ
h
,
λ
h
)
La(\mu_h,\lambda_h)
La(μh,λh)(
σ
=
2
\sigma=\sqrt2
σ=2 \lambda),其中
μ
h
,
λ
h
\mu_h,\lambda_h
μh,λh 由 3D 尺度预测分支预测,
μ
h
\mu_h
μh 是要回归的参数,
σ
h
\sigma_h
σh 代表不确定性(因为不确定性越高,方差越大)。高度真实值记为
h
3
d
g
t
h^{gt}_{3d}
h3dgt,则 3D 高度的损失函数如下:
L
h
3
d
=
2
σ
h
∣
μ
h
−
h
3
d
g
t
∣
+
l
o
g
(
σ
h
)
L_{h3d}=\frac{\sqrt{2}}{\sigma_h}|\mu_h-h^{gt}_{3d}|+log(\sigma_h)
Lh3d=σh2∣μh−h3dgt∣+log(σh)
通过
L
h
3
d
L_{h3d}
Lh3d 有监督学习,网络可以准确预测出 3D 高度的分布,在此基础上预测深度的分布
L
a
(
μ
p
,
λ
p
)
La(\mu_p,\lambda_p)
La(μp,λp):
d
p
=
f
⋅
h
3
d
h
2
d
=
f
⋅
(
λ
h
⋅
X
+
μ
h
)
h
2
d
=
f
⋅
λ
h
h
2
d
⋅
X
+
f
⋅
μ
h
h
2
d
d_p=\frac{f\cdot h_{3d}}{h_{2d}}=\frac{f\cdot (\lambda_h\cdot X+\mu_h)}{h_{2d}}=\frac{f\cdot \lambda_h}{h_{2d}}\cdot X+\frac{f\cdot \mu_h}{h_{2d}}
dp=h2df⋅h3d=h2df⋅(λh⋅X+μh)=h2df⋅λh⋅X+h2df⋅μh
其中
X
X
X 是标准拉普拉斯分布
L
a
(
0
,
1
)
La(0,1)
La(0,1),深度分布的均值和标准差分别为
f
⋅
μ
h
h
2
d
,
f
⋅
σ
h
h
2
d
\frac{f\cdot \mu_h}{h_{2d}},\frac{f\cdot \sigma_h}{h_{2d}}
h2df⋅μh,h2df⋅σh。为了学习更复杂的分布,给深度分布加上一个偏移分布
L
a
(
μ
b
,
λ
b
)
La(\mu_b,\lambda_b)
La(μb,λb),得到最后的深度分布:
d
=
L
a
(
μ
p
,
σ
p
)
+
L
a
(
μ
b
,
σ
b
)
μ
d
=
μ
p
+
μ
b
,
σ
d
=
(
σ
p
)
2
+
(
σ
b
)
2
d=La(\mu_p,\sigma_p)+La(\mu_b,\sigma_b)\\ \mu_d=\mu_p+\mu_b,\ \ \ \sigma_d=\sqrt{(\sigma_p)^2+(\sigma_b)^2}
d=La(μp,σp)+La(μb,σb)μd=μp+μb, σd=(σp)2+(σb)2
σ
d
\sigma_d
σd 称为基于几何的不确定性Geometry based Uncertainty(GEU),优化深度分布的损失函数如下:
L
d
e
p
t
h
=
2
σ
d
∣
μ
d
−
d
g
t
∣
+
l
o
g
(
σ
d
)
L_{depth}=\frac{\sqrt{2}}{\sigma_d}|\mu_d-d^{gt}|+log(\sigma_d)
Ldepth=σd2∣μd−dgt∣+log(σd)
在测试阶段,用下式表示深度预测的可靠性:
p
d
e
p
t
h
=
e
x
p
(
−
σ
d
)
p_{depth}=exp(-\sigma_d)
pdepth=exp(−σd)
最终的置信度为:
p
3
d
=
p
3
d
∣
2
d
⋅
p
2
d
=
p
d
e
p
t
h
⋅
p
2
d
p_{3d}=p_{3d|2d}\cdot p_{2d}=p_{depth}\cdot p_{2d}
p3d=p3d∣2d⋅p2d=pdepth⋅p2d
2.5 Hierarchical Task Learning
提出HTL的原因:在训练开始阶段,
h
2
d
,
h
3
d
h_{2d},h_{3d}
h2d,h3d 预测很不准确,会影响后续任务(如深度估计),影响训练过程,降低性能。
论文提出HTL,一种学习策略,能够使得每个任务在其前序任务训练到一定程度后再开始训练。具体来说,对于每个epoch,在算总损失时为每个子任务损失加上一个权重,如下式所示:
L
t
o
t
a
l
=
∑
i
∈
T
w
i
(
t
)
⋅
L
i
L_{total}=\sum_{i\in T}w_i(t)\cdot L_i
Ltotal=i∈T∑wi(t)⋅Li
其中
T
T
T 是任务几何,
t
t
t 是 epoch index,
L
i
L_i
Li 是第
i
i
i 个任务的损失函数,
w
i
(
t
)
w_i(t)
wi(t) 是第
t
t
t 个 epoch 中第
i
i
i 个子任务损失函数的权重。

训练过程分为三个阶段,如图4所示。
为了充分训练每个任务,在训练过程中把权重
w
i
(
t
)
w_i(t)
wi(t) 从0增到1,如下式所示:
w
i
(
t
)
=
(
t
T
)
1
−
α
i
(
t
)
,
α
i
(
t
)
∈
[
0
,
1
]
w_i(t)=(\frac{t}{T})^{1-\alpha_i(t)},\ \ \ \alpha_i(t)\in [0,1]
wi(t)=(Tt)1−αi(t), αi(t)∈[0,1]
其中
T
T
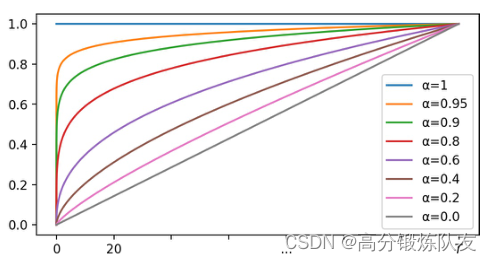
T 是总的 epoch 数,图5画出了不同
α
i
\alpha_i
αi 值对应的策略,纵轴是权重
w
i
(
t
)
w_i(t)
wi(t),横轴是 epoch index,
α
i
\alpha_i
αi 越大,
w
i
(
t
)
w_i(t)
wi(t) 上升得越快。
α
i
\alpha_i
αi 可以由下式得到:
α
i
(
t
)
=
∏
j
∈
P
i
l
s
j
(
t
)
\alpha_i(t) =\prod_{j\in P_i}ls_j(t)
αi(t)=j∈Pi∏lsj(t)
其中
P
i
P_i
Pi 是第
i
i
i 个任务的前序任务集,
l
s
j
(
t
)
ls_j(t)
lsj(t) 是第
j
j
j 个任务的学习情况,是一个0到1之间的值,这个式子表示只有当前序任务有高的
l
s
ls
ls(也即学的好),
α
i
\alpha_i
αi 的值才大。学习情况的计算式子如下:

3 实验
使用KITTI数据集,将7481张训练集图像进行分割,3712张用于训练和3769张用于验证。在单目3D检测和鸟瞰图检测任务中,评估
A
P
40
AP_{40}
AP40,以避免原始
A
P
11
AP_{11}
AP11 的偏差。
结果待补充。















 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









