







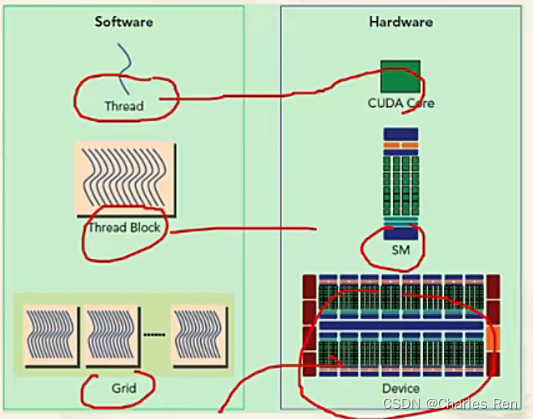
CUDA与GPU 名词解析
首先我们要明确:
SP(streaming Process),SM(streaming multiprocessor)是硬件(GPU hardware)概念。
而thread,block,grid,warp是软件上的(CUDA)概念。
SP:最基本的处理单元,streaming processor,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
SM:多个SP加上其他的一些资源组成一个streaming multiprocessor。也叫GPU大核,其他资源如:warp scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。
每个SM包含的SP数量依据GPU架构而不同,Fermi架构GF100是32个,GF10X是48个,Kepler架构都是192个,Maxwell都是128个。
一个GPU可以有多个SM(比如16个),最终一个GPU可能包含有上千个SP。
这么多核心“同时运行”,速度可想而知,这个引号只是想表明实际上,软件逻辑上是所有SP是并行的,但是物理上并不是所有SP都能同时执行计算,因为有些会处于挂起,就绪等其他状态。
CUDA 名词对应GPU 概念
- thread:一个CUDA的并行程序会被以许多个threads来执行。
- block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
- grid:多个blocks则会再构成grid。
- warp:GPU执行程序时的调度单位,目前cuda的warp的大小为32,同在一个warp的线程,以不同数据资源执行相同的指令,这就是所谓 SIMT。
软硬件对应关系
thread —— sp
block —— SM流处理器(这个对应其实并不确切,上面我们看到一个SM里可以有很多block)
grid —— GPU device
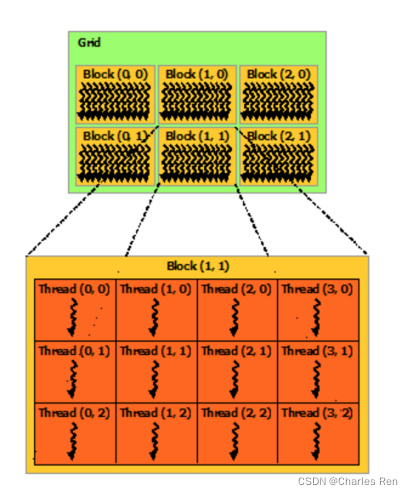
CUDA核,也叫每个block,block可以排列成1D,2D或者3D结构
每个block中又可以启动多个线程。
- threadIdx.x、threadIdx.y(线程的索引/编号)不同block中的线程编号可能相同
- blockIdx.x(block的编号)
- blockDim.x (某个block上的线程数量)
下图是一个二维的结构:一个device下分布着一个矩阵block,每个block下又分布着一个矩阵thread,每个thread就是最小执行单元
模型介绍
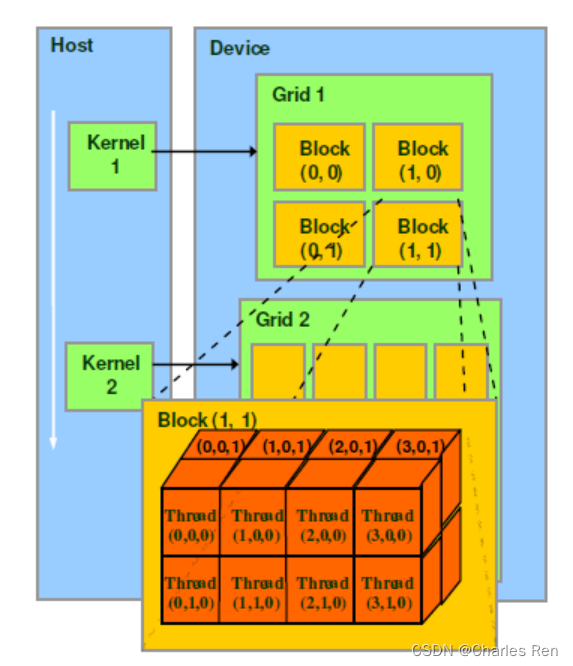
CUDA 逻辑模型
add<<<4,4>>>(d_a, d_b, d_c);
CUDA应用包括,一个grid,每个grid下有很多个block,每个block中有很多个线程
比如下面这个模型,包括6个block,每个block下有12个线程。
GPU物理模型
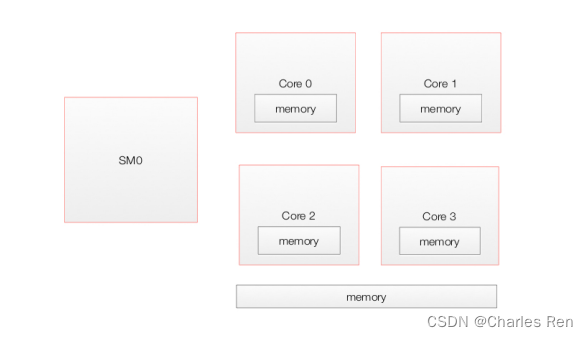
GPU实际上物理的模型。
一个GPU包含多个流处理器Streaming Multiprocessors (SMs)。他们公用一个global memory。每个SM有自己的local memory。
每个SM有很多个核心(core),他们公用一个shared memory,并且每个core有自己local memory。一个SM有很多个core,比如Pascal GP100里有2048个core,表示可以分配线程。

运行模型
当一个kernel启动后,thread会被分配到这些SM中执行。大量的thread可能会被分配到不同的SM,同一个block中的threads必然在同一个SM中并行执行。
每个thread拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的Single Instruction Multiple Thread(SIMT)。
当一个CUDA程序调用一个kernel的grid时。GPU会找到可用的SM,然后block被分配到SM上执行,多个block可以被分配到一个SM上,一个thread在SM中的一个core上运行。
block是软件概念,一个block只会由一个sm调度,程序员在开发时,通过设定block的属性,告诉GPU硬件,我有多少个线程,线程怎么组织,比如下图,是两种线程的组织方式,仅仅是软件对应硬件组织方式而已,具体运行调度并不是按这个模型来调度的。但是组织方式影响了执行顺序。但是SM下有几个block的种组织方式也不是软件层面可以定义的,而是由硬件调度策略分配的,所以软件层面无需关心。
而具体运行时调度由sm的warps scheduler负责,这个我们下面说,block一旦被分配好SM,该block就会一直驻留在该SM中,直到执行结束。一个SM可以同时拥有多个blocks,但需要序列执行。
比如举个例子:
有一个CUDA进程有8个block,在运行一个程序时。如果GPU有两个空闲SM,则每个SM会被分配4个block。也可能这时GPU有4个空闲SM,这时,每个SM就可以被分配2个block了。
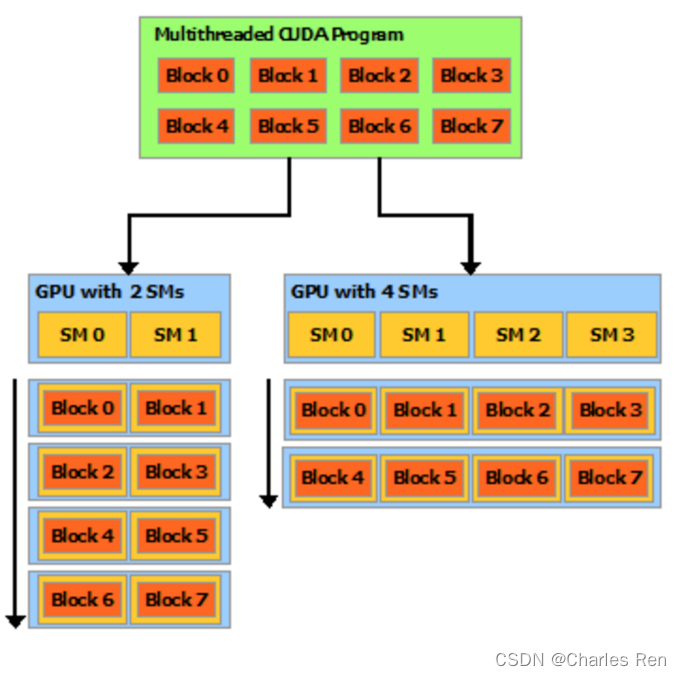
这两种分配方式有什么区别呢?
一个SM可以同时拥有多个blocks,但需要序列执行。不同SM是独立执行的。那么使用了4个SM的并行性是要更好的,所以他的执行效率应该更高。但是这个分配是硬件来决定的。
wrap的概念:
这个概念不属于CUDA的规范但是却有助于理解和优化在特定CUDA设备上运行的程序的性能
一个SM中物理层面实际上并不是所有的thread能够在同一时刻执行,而在软件层面我们可以理解为线程都并行 运行。。
warp是调度和运行的基本单元。warp中所有threads并行的执行相同的指令。一个SM中的32个线程被聚合为一个warp(一般是32个:具体数量硬件调度实现,程序员不用管)。这个参数也可以在不同的显卡的属性信息中得知,在SM中,warp才是线程调度的单位,而不是单个的线程。一个block被分成很多个warps。比如一个block中有320个线程,那么他被分成10个warps。一个block中的线程一定在一个wrap中。一个warp需要占用一个SM运行,多个warps需要轮流进入SM。由SM的硬件warp scheduler负责调度。
一个warp中的32个线程是并行执行的。一个block中不同warp是并发执行的。比如说一个block中分成10个warps,warp0执行了两步,这时可能会切换warp1去执行两步。再切换回warp0执行两步。也就是一个block中的warp不能并行执行。而是并发执行
无论如何,每次必调度32线程执行,即使只执行16线程,另外的16线程也会占用硬件。
分支发散
https://blog.csdn.net/WuYuFffan/article/details/108672543
warp有一个问题就是分支发散,叫做thread divergence
由于每次我们的的warp中的所有线程都是SIMT,单数据多线程同时执行。也就是一个warp中所有线程执行代码相同的,并且同时运行。但是如果他们的代码不同,也就是kernel函数中存在if else类似语句,导致一个warp中的线程不能同时运行一条语句。那么其中的其他分支就会强制进入等待状态,从而影响效率。
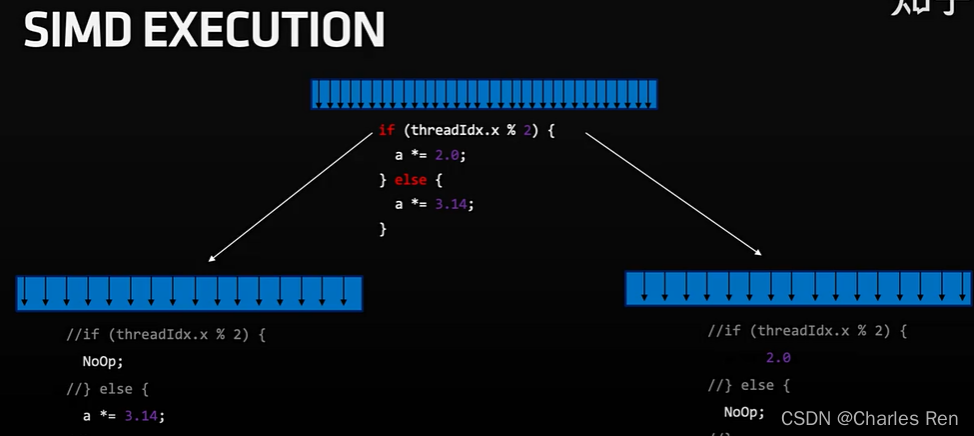
举个例子:
__global__ void code_divergence()
{
int gid = blockIdx.x * blockDim.x + threadIdx.x;
float a, b;
a = b = 0;
//同一个warp上有分支
if (gid % 2 == 0)
{
a = 100.0;
b = 50.0;
}
else
{
a = 200;
b = 75;
}
}
该例子就有分支发散问题,一个warp的线程会走两个分支,就会出现分支线程等待。
下面我们看一种解决方式:
__global__ void code_without_divergence()
{
int gid = blockIdx.x * blockDim.x + threadIdx.x;
float a, b;
a = b = 0;
//不同的warp上去做分支,就不会有问题
int warp_id = gid / 32;
if (warp_id % 2 == 0)
{
a = 100.0;
b = 50.0;
}
else
{
a = 200;
b = 75;
}
}
我们让不同的warp走不同的分支,由于不同warp不是同时并行执行,就没有等待问题,效率就不受影响。
软件层面建议
软件层面,我们可以不用关心warp是如何调度执行的,那是硬件的策略。我们只关心如何设计block数量和thread的数量。
建议程序设计如下:
每一个块内线程数应该首先是32的倍数,因为这样的话可以适应每一个warp包含32个线程的要求,每一个warp中串行执行,这就要求每一个线程中不可以有过多的循环或者需要的资源过多。但是每一个块中如果线程数过多,可能由于线程中参数过多带来存储器要求过大,从而使SM处理的效率更低。**所以,在函数不是很复杂的情况下,可以适当的增加线程数目,线程中不要加入循环。在函数比较复杂的情况下,每一个块中分配32或是64个线程比较合适。**这样才能最大化GPU使用率。
参考链接
https://blog.csdn.net/junparadox/article/details/50540602
https://zhuanlan.zhihu.com/p/337947104
https://www.cnblogs.com/shouhuxianjian/p/4529172.html
https://blog.csdn.net/feng__shuai/article/details/108401793


















 5794
5794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











