






OPEN:Online Planning for Multi-UAV Pursuit-Evasion in Unknown Environments Using Deep Reinforcement Learning
论文原文链接:https://arxiv.org/abs/2409.15866
一、摘要
(原文翻译)在多无人机追逐逃逸任务中,追逐方的目的是要捕捉逃逸方,这对无人机集群智能构成了关键挑战。多智能体强化学习(MARL)在建模协作行为方面展现出巨大潜力,但是大多数基于强化学习的方法仍局限于有限动力学或者固定场景的简化仿真。此前将强化学习策略应用于真实世界追捕-躲避任务的大部分尝试都局限于二维场景,例如地面车辆或者在固定高度飞行的无人机。本文提出了一种基于MARL的在未知环境中进行多无人机追捕-逃逸任务的在线规划算法(OPEN)。OPEN引入了逃逸者预测增强网络,用来解决协作策略学习中的部分可观测问题。此外, OPEN在MARL 训练中提出了自适应环境生成器, 从而提高了探索效率, 并使策略在各种场景中具有更好的泛化能力。仿真实验结果表明,本文提出的方法在挑战性的场景中显著优于基准方法,在未见过的场景中实现了100%的捕获率。最后,在将校准过的无人机动力学模型整合到训练中之后,OPEN通过两阶段奖励优化推导出可行策略,并以零样本学习的方式将其部署到真实的四旋翼无人机上。OPEN是首个在未知环境中针对多无人机追捕-逃逸任务,通过油门推力和体轴角速率控制指令来推导并部署基于强化学习策略的研究工作。
论文开源代码以及视频链接:https://sites.google.com/view/pursuit-evasion-rl
二、准备工作
2.1 多无人机追逃问题
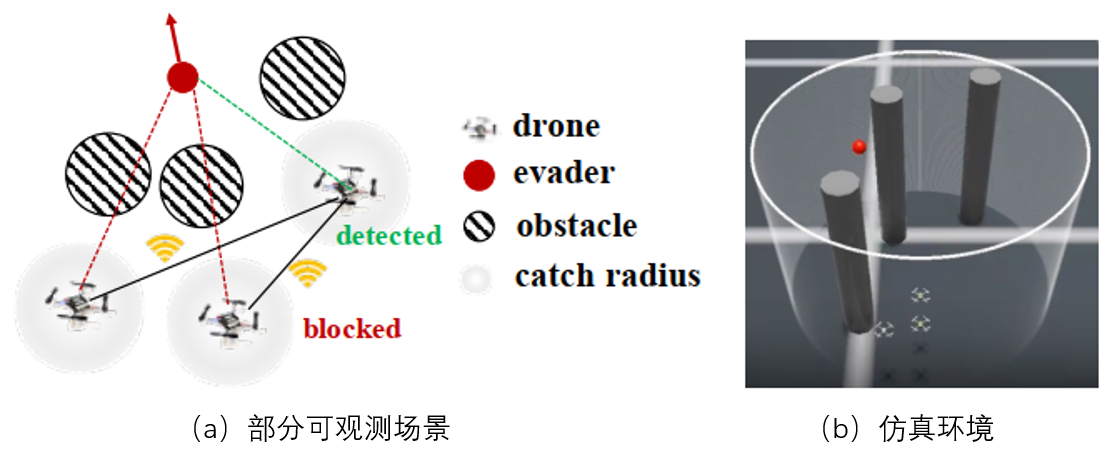
本文的多无人机追捕-躲避问题如下图所示,N 驾无人机在充满障碍物的环境中追逐一个速度更快的逃逸者。如下图所示,多无人机追逃任务的规则设置如下:
(1)追捕无人机具有捕捉半径,当逃逸者进入无人机的捕获半径内时,即认为捕捉到目标;
(2)追捕无人机具有检测能力,但只有在视线未被障碍物阻挡的情况下才能进行探测(视线被遮挡时,无法获取目标信息),一旦探测到逃逸者,无人机可以将目标信息传递给其他追捕无人机;
(3)非策略型逃逸者,采用势场法进行控制,斥力场中的力包括无人机、障碍物以及场地边界产生的斥力,力的大小与距离成反比。此外,逃逸者以恒定速度 移动,运动方向由斥力的合力决定。
2.2 问题陈述
将上述问题表述为分布式部分可观测马尔科夫决策过程:
,
其中 表示为状态空间,
表示行为空间,
表示观测空间,
表示初始状态空间,
表示转移概率,
表示奖励函数,
表示折扣因子,
表示无人机数量,
表示无人机
在状态
下的观测结果。
本文的目的是构建一种在各种场景中都能表现良好的策略。任务空间 定义了一系列具有相似属性的分布式部分可观测马尔科夫决策过程;参数空间
表示任务空间
之间的差异;任务参数
初始化状态参数,包括无人机和逃逸者的初始位置,障碍物的数量和位置。本文的同构无人机学习一个参数共享的策略
,输出无人机
在策略
和 观测状态
的行为
。
目标函数是为了在任意任务参数 下,最大化期望累积奖励:
,
其中 是在时间步为
时的联合行为。
2.3 四旋翼无人机动力学模型
四旋翼无人机的质量为 , 惯性矩阵
。
四旋翼无人机的状态微分方程表述为:
,
其中 表示无人机的状态量,
表示无人机的位置,
表示无人机的四元数,
表示无人机的线速度,
表示无人机的角速度。
(1)动力学模型
无人机的线加速度表述为:
,
其中 表示重力加速度,
表示第
个螺旋桨产生的推力,
是从
体轴坐标系到世界坐标系的旋转矩阵。
无人机在体轴系下的角加速度为:
,
其中 是无人机在体轴系下的合力矩:
,
其中, 是螺旋桨
产生的力矩,
是螺旋桨
在体轴系下的位置。
(2)动力模型
电机转速建模为一阶系统:
,
其中 是电机
的转速,
是电机
的期望转速,时间常数为
。
则螺旋桨 产生的力与力矩为:
,
,
其中, 为升力系数,
为反扭矩系数。
三、方法
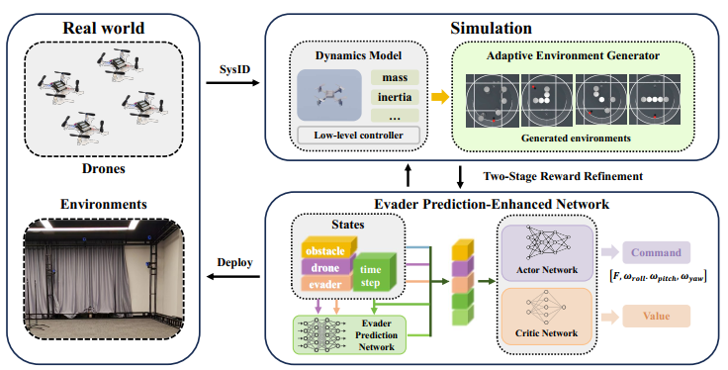
多无人机追逃算法的整体流程如下图所示,首先通过系统辨识得到真实无人机的动力学参数,在仿真环境中校准无人机的动力学模型,缩小仿真与现实之间的差距。同时本文提出了一种自适应环境生成器,生成不同的仿真环境,增强学习策略在不同场景下的泛化能力。随后,使用 MAPPO 算法训练强化学习策略输出无人机控制指令。其中为了在部分可观测性条件下对逃逸者的未来轨迹进行建模并指导协同策略, 本文设计了一个逃逸者预测增强网络,该网络利用基于注意力的架构来捕捉观测值之间的相互关系,并采用轨迹预测网络来预测逃逸者的移动。最后,通过两阶段奖励优化,学习到的策略可以直接应用于真实四旋翼飞行器。
3.1 初始化
(1)观测空间
无人机的观测值由三部分组成,分别是:自身信息 , 其他无人机信息
以及障碍物信息
。
:姿态信息,速度信息,距逃逸者的相对位置真实值与预测值(当逃逸者未被检测到时,其真实相对位置设置为-5)。
:距其他无人机之间的相对位置信息。
:与k个最近邻障碍物的相对位置信息(本文将k设置为3)。
(2)动作空间
本文采用推力和体轴角速率(CTBR)指令作为动作空间,随后CTBR指令作为期望指令输入到PID控制器中,控制电机转速。无人机 的动作空间
定义为:
,
其中 表示归一化的合推力(油门大小),
表示三轴角速率。
(3)奖励函数
奖励函数由四部分组成,分别是:捕捉奖励,距离奖励,碰撞惩罚以及平滑度奖励。
捕捉奖励:当逃逸者进入任意无人机的捕获半径时,每个无人机将各自获得一个+6奖励。
距离奖励:无人机与逃逸者的相对距离 。
碰撞惩罚:无人机与障碍物的相对距离小于安全阈值,施加-10的惩罚。
平滑度奖励:正则化输出,确保输出可靠。
3.2 逃逸者预测增强网络
(1)逃逸者预测网络(Evader Prediction Network)
使用长短期记忆网络(LSTM)来预测逃逸者 个时间步长的轨迹,LTSM的输入为
个时间步长的历史数据,包括无人机的位置、逃逸者的位置和速度(如果逃逸者未被观测到,则使用标记值代替),以及对应的时间步长。
采集 个时间步长的数据,前
个时间步长的数据作为输入
,将
到
之间的数据作为标签
。通过监督学习训练逃逸者预测网络
,损失函数
定义为:
。
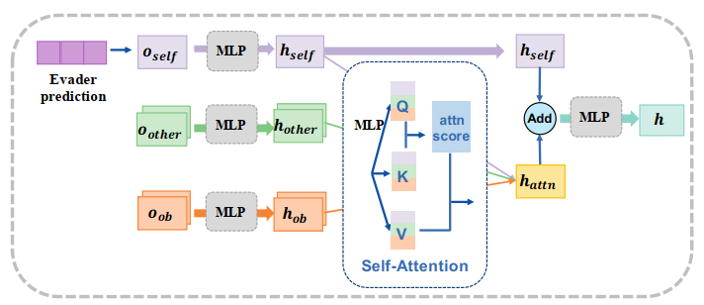
(2)演员评论家网络(Actor and Critic Network)
演员评论家网络基于注意力机制的观察编码器,如下图所示。无人机的原始观测值由 、
以及
组成,逃逸者的预测轨迹被拼接到
中。三部分观测值分别通过不同的MLP进行编码,生成128维的嵌入层。采用Multi-head self-attention模块来捕捉这些嵌入层之间的关系,得到
。为了强调自身信息,将self-embeddings的特征
和
合并,通过一个MLP生成最终特征
。
在Actor网络中,基于 使用高斯分布对动作进行参数化。在Critic网络中,将
输入到一个MLP中,生成表示估计状态值的标量值。
3.3 自适应环境生成器
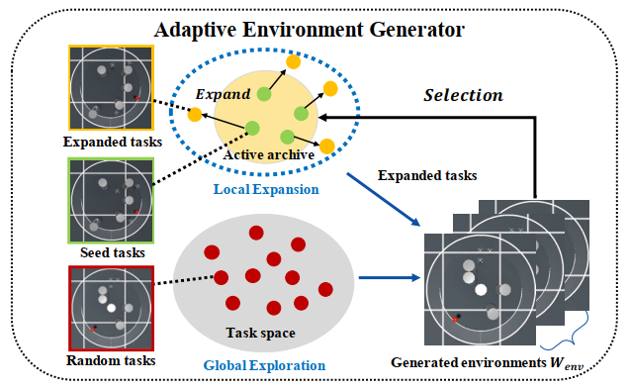
本文通过自适应环境生成器来提高强化学习策略在未知环境中的泛化能力。算法流程如下所示。

本文的自适应环境生成器如下图所示,将任务空间分解为:局部扩展模块和全局探索模块。
局部扩展模块:增强了四旋翼无人机在固定障碍物布局下从任意初始位置捕获逃逸者的能力。该模块维护一个动态档案库 ,用于存储未解决环境对应的任务参数
。通过从
中采样的种子任务进行任务扩展:在保持障碍物不变的前提下,向无人机和逃逸者的位置添加噪声扰动
。通过评估策略在生成环境
中的表现,档案库会持续更新,并且仅保留成功率
范围内的任务(其中
,
)。
全局探索模块:通过从完整参数空间 中随机采样任务参数(包括障碍物数量与位置、无人机及逃逸者初始坐标),主动探索未知障碍物布局。为实现定向优化与多样性任务的平衡,系统采用概率混合机制:以
的概率选择快速局部扩展,以
的概率选择慢速全局探索,形成双速率任务生成体系。
3.4 两阶段奖励优化
采用平滑性奖励函数 来平衡任务完成度与动作连续性。为解决现实部署中策略可行性保障与任务成功率协同优化的难题,设计了双阶段奖励优化机制:第一阶段暂停平滑性奖励,专注优化其他三项基础奖励;第二阶段重新激活平滑性奖励(系数设为4.0),基于第一阶段训练checkpoint继续优化,在确保高任务成功率的同时提升动作平滑性。
四、实验
4.1 实验设置
实验参数如下:
| 名称 | 参数 |
|---|---|
| 场地 | 半径0.9 m,高1.2 m |
| 障碍物 | 半径0.1 m,高1.2 m |
| 无人机 | 最大速度1.0 m/s,捕获半径0.3 m/s |
| 逃逸者 | 速度1.3 m/s |
| 无人机距离障碍物的安全阈值 | 0.07 m |
| 单回合最大时间步长 | 800 |
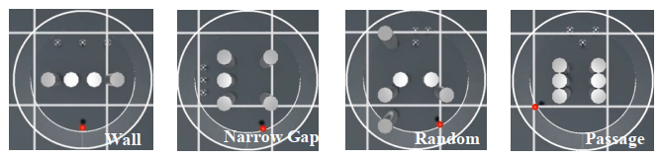
测试环境如下图所示,构建了四个测试场景,其中包括within-distribution场景:Wall和Narrow Gap;out-of-distribution(OOD)场景:Random以及Passage。
4.2 评价指标
每次实验取300个episodes的平均值,评价指标包括:捕获率、捕获步长以及碰撞率。
捕获率(Capture Rate):成功捕获的episode次数占总episode次数之比。
捕获步长(Catpture Step):首次捕获的平均时间步长,若未捕获,则记为episode最大时间长度。
碰撞率(Collision Rate):每个episode长度内的平均碰撞次数。
4.3 实验结果
将本文提出的方法与现有方法进行对比,其中包括三个启发式算法(Angelani, Janosov, and APF
)和两个基于强化学习的算法(DACOOP and MAPPO)。
下表展示了OPEN方法与其他五个方法在仿真测试环境中的表现:
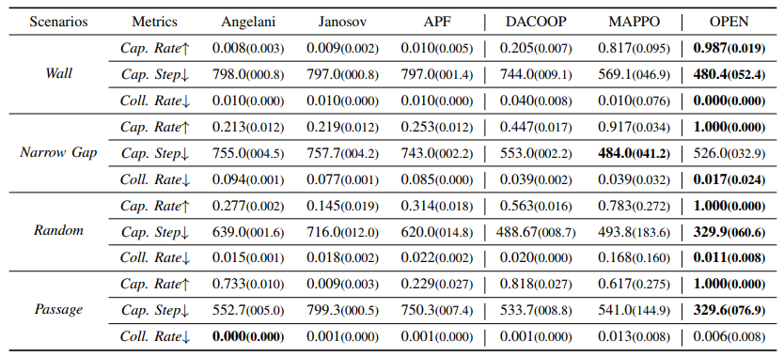
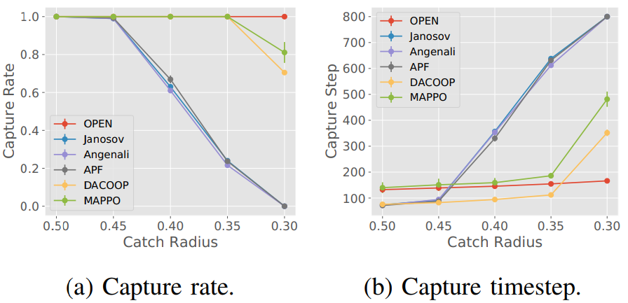
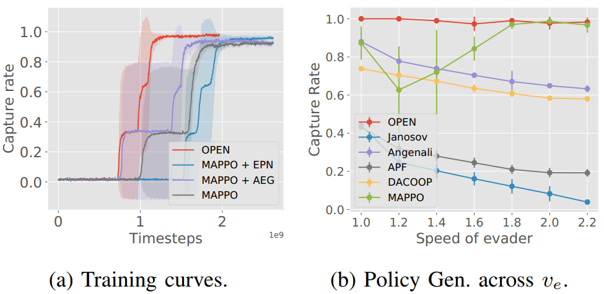
鉴于基线方法表现不佳,在无障碍物的简单场景中测试这些算法,结果如下图所示,随着捕获半径减小,基线方法的捕获率急剧下降。较小的捕获半径要求无人机具备更敏捷的行为,需要快速调整编队以封锁所有逃逸路线。然而,启发式算法和DACOOP方法依赖基于力学调整的避障和追踪机制,本质上限制了无人机的敏捷性。当捕获半径较小(如0.3)时,MAPPO难以学习最优捕获策略,成功率收敛于约80%。相比之下,OPEN在半径缩小时仍保持高捕获率,仅伴随捕获步数的轻微增加,这证明了纯强化学习策略在协作捕获方面的优越性。
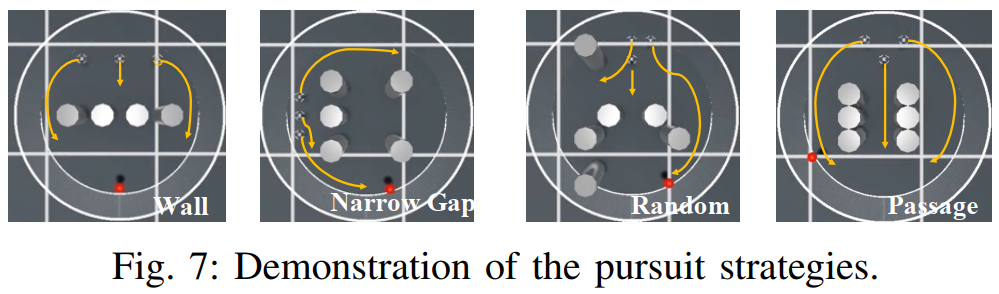
OPEN方法在测试场景中表现出四种行为,凸显了策略的协同追捕能力,如下图所示。在墙体场景中,无人机采用双向包围策略:一个四旋翼无人机负责监控,另外两个从侧翼包抄逃逸者,而基线方法因前方障碍物的阻挡无法实现类似策略。在狭窄间隙场景中,无人机通过捷径拦截逃逸者,而基线方法仅能被动跟随。在随机场景中,无人机基于预测轨迹快速定位障碍物后方的逃逸者,而基线方法初期会失效。在通道场景中,将四旋翼无人机分组以封锁所有逃逸路线,而基线方法因贪心逼近策略会遗留未封闭的通道。
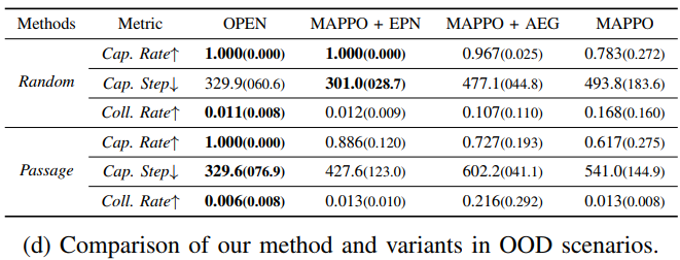
随后对方法的核心模块进行了消融研究。基准方法标记为"MAPPO",代表未引入逃逸者预测增强网络(EPN)和自适应环境生成器(AEG)模块的基础实现。变体方法"MAPPO + EPN"在MAPPO框架中集成了逃逸者预测增强网络模块,而"MAPPO + AEG"则将MAPPO与自适应环境生成器模块相结合。
从下图a的训练曲线可以看出,OPEN方法展现出最高的捕获性能,相比MAPPO样本效率提升超50%。原始"MAPPO"需消耗超20亿样本量仅达成90%捕获率,突显了推导同时考虑无人机动力学、且能在多样化场景中表现优异的强化学习策略的难度。"MAPPO + EPN"的训练曲线表明,虽然EPN模块略微增加训练数据需求,但最终性能优于MAPPO。这是由于训练逃逸者预测网络带来的额外计算开销,一旦网络收敛并能精准预测逃逸者未来位置,该变体即可实现更优性能。我们统计了四个测试场景中单次任务周期内对逃逸者下一位置的平均预测误差,即使在逃逸者初始不可见的随机场景中,预测误差仍与无人机尺寸相当且远小于捕获半径,验证了预测有效性。"MAPPO + AEG"的训练曲线显示,AEG模块在显著提升训练效率的同时,相较MAPPO小幅优化了最终性能。
如下图b所示,在Passage场景中评估了OPEN方法与基线方法对逃逸者速度变化的敏感性。与无障碍场景不同,Passage场景允许逃逸者利用障碍物遮挡和速度优势。实验表明:随着逃逸者速度提升,启发式算法与DACOOP因早期拦截不力导致捕获率显著下降。MAPPO其捕获率随速度增加呈先降后升趋势,最终学习到与OPEN类似的三路拦截策略(高速下逃逸者转向时更易陷入盲区,缺乏调整方向时间)。尽管仅针对v=1.3速度训练,OPEN在速度泛化测试中保持稳定高性能,无需重训练即可实现高速逃逸者的高捕获率
下表展示了在四个测试场景中,本文的逃逸者轨迹预测网络的预测误差。

如下表所示,本文在OOD场景中对方法及其变体进行进一步评估:随机场景中,OPEN以最高捕获率和最低碰撞率领先,捕获步数与"MAPPO + EPN"相当。通道场景中,OPEN在捕获率和碰撞率上全面超越所有变体。
最终,将算法部署在三架CrazyFlie2.1无人机上,其在真实环境中的表现与仿真环境中的表现如下表所示:


















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









