






Game of Drones: Multi-UAV Pursuit-Evasion Game With Online Motion Planning by Deep Reinforcement Learning
一、摘要
本文研究了障碍环境下多四旋翼无人机与目标的追逃博弈问题。为实现对城市环境的高质量仿真,我们提出基于物理引擎的追逃场景框架(PES),使无人机智能体能够执行动作并与环境交互。在此基础上,构建了结合目标预测网络(TP Net)的多智能体冠状双向协调网络(CBC-TP Net),通过多智能体深度确定性策略梯度(MADDPG)的矢量化扩展,确保受损"集群"系统在追逃任务中的有效性。与传统强化学习不同,我们在通用框架中创新性地设计了目标预测网络(TP Net),模仿人类思维方式:总是先进行态势预测再做出决策。通过开展追逃博弈实验验证了所提策略在正常和抗损毁情况下均具备先进性能表现。
二、准备工作
2.1 追逃交互环境
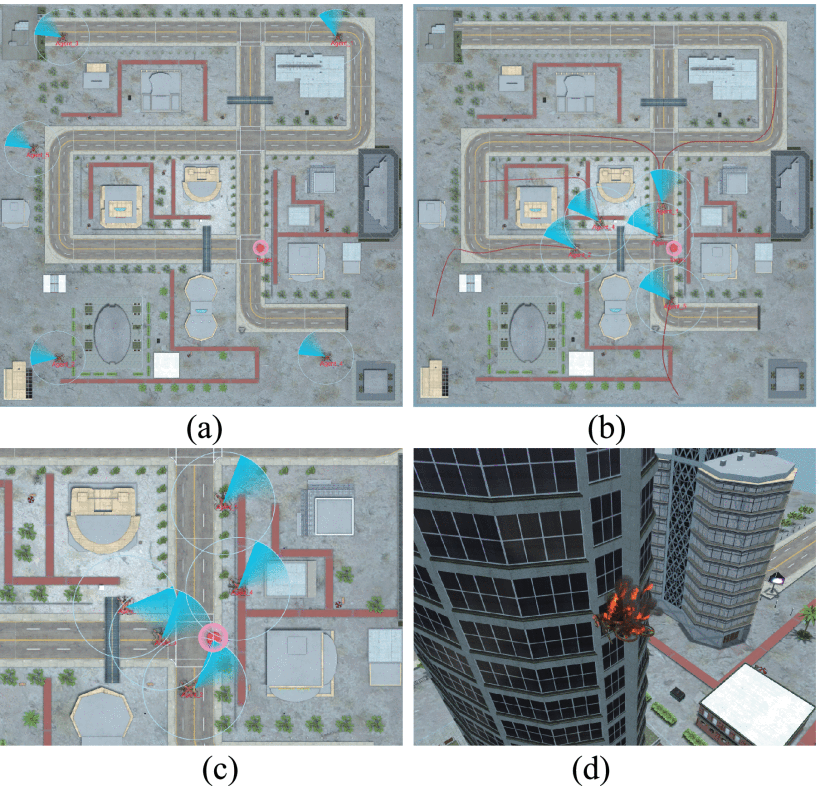
文章搭建了基于Unity3D和基于Pytorch深度强化学习框架结合的无人机追逃仿真环境,如下图所示。图(a)展示了无人机和逃逸者的初始位置,图(b)展示了无人机与目标追逃过程,图(c)展示了无人机成功捕捉的场景,图(d)展示了无人机撞上障碍物的场景。
2.2 追逃问题陈述
任务背景:多架无人机在城市环境下追逐单一目标。
初始状态:无人机和目标分别随机分布在城市地图的边缘和中心,无人机被标记为 到
,目标被标记为
。无人机和目标的初始速度都为0。
追逃过程:深度强化学习策略输出的力作用在无人机上,促使无人机追逐目标,同时躲避障碍物;目标使用DDPG强化学习策略来躲避无人机。
假设条件:无人机定高飞行;无人机在不同高度飞行以避免无人机之间的碰撞。
约束条件:无人机与目标之间的速度与加速度限制约束如下:
,
.
任务完成:当三架无人机同时捕捉到目标(捕捉半径2m),持续五个时间步时,即认为任务完成。
2.3 四旋翼无人机动力学模型
线加速度:
,
角加速度:
,
其中, 表示无人机的三维位置坐标,
表示无人机的滚转、俯仰以及偏航角,
表示无人机三轴惯性矩,
表示无人机的三轴力矩,
表示无人机的合推力。
本文假设无人机定高飞行,即 ,期望控制指令为
。
三、方法
3.1 多智能体强化学习问题表述
在追逃系统(PES)中,我们需控制一组四旋翼无人机智能体,在城市环境的多障碍物条件下实现对目标的追踪。四旋翼无人机之间完全协同,并与目标形成竞争关系。因此,追逃过程可建模为随机马尔可夫博弈(Stochastic Markov Game),这是马尔可夫决策过程(MDPs)的多智能体扩展形式。针对N个智能体的马尔可夫博弈,其定义包含以下要素:
-
状态集合
:描述所有智能体的可能属性;
-
动作集合
与观测集合
:分别对应每个智能体的可选动作与环境观测;
-
状态转移机制:每个四旋翼无人机
选择的动作通过状态转移函数在PES中交互作用,生成下一状态,记为
,表征从状态
的转移过程;
-
个体观测函数:每个无人机
:
;
-
奖励函数:根据状态与动作计算奖励值
:
.
每个四旋翼无人机的目标是通过优化策略,最大化其总期望奖励:
,
其中为折扣因子,
为时间范围。
为求解PES中多四旋翼无人机协同控制以对抗目标的问题,本文采用深度强化学习(DRL)方法。DRL属于机器学习领域,其核心在于智能体通过试错机制与环境交互,选择动作以获取最大累积奖励。DRL模型的目标是训练最优策略 ,该策略定义了每个四旋翼飞行器智能体在观测
下选择动作
的概率分布,即
,其中
与
分别表示智能体i在当前时间步选择的动作和获得的观测。因此,
架无人机的目标函数定义如下:
,
其中 为策略的参数。
本文采用集中式训练与分布式执行框架实现目标,如下图所示。
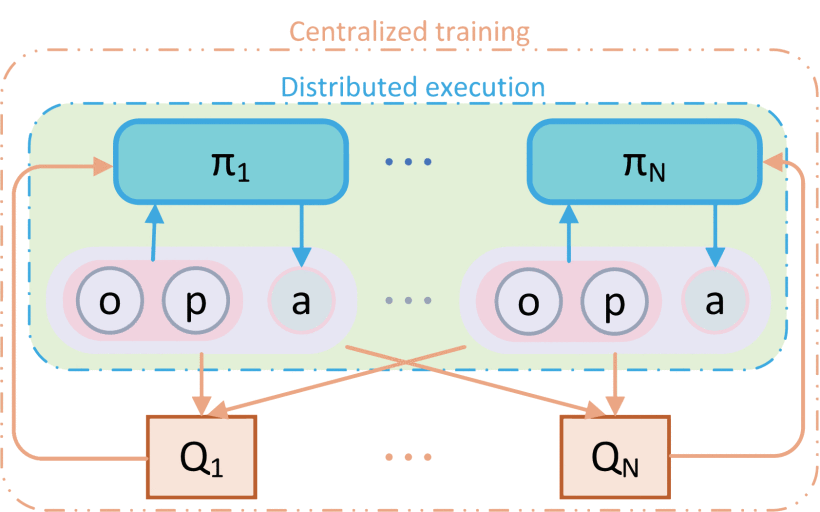
在此框架下,训练阶段允许策略使用协作智能体的信息以降低训练难度,但需确保此类信息在测试阶段不被调用。此外,赋予四旋翼飞行器预测目标未来位置的能力。每个智能体 的私有观测
可通过与目标预测位置
进行特征拼接实现动态更新:
。
然后,目标函数的梯度可以表述为:
.
中心训练的动作价值函数的梯度可以表述为:
.
其中 使用时间差分算法估算:
.
3.2 目标预测网络
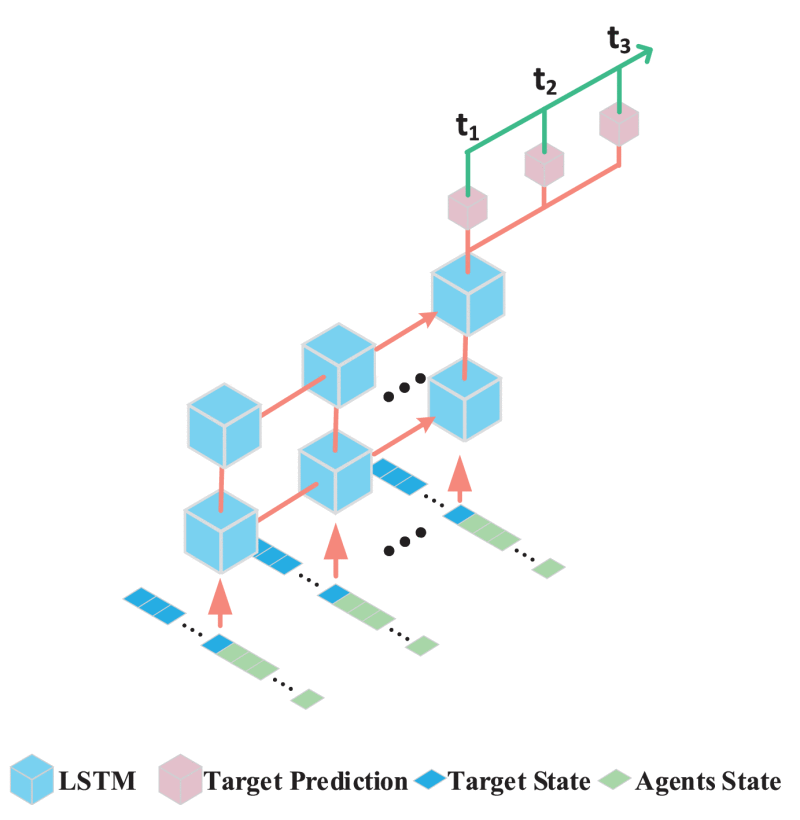
本文提出了一种基于深度长短期记忆网络(LSTM)的轨迹预测网络(TP Net),用于预测目标未来 个时间步的轨迹,如图下图所示。考虑到需要通过
个时间步的历史目标状态数据来预测目标未来
个时间步(
)的位置。在TP网络的训练过程中,我们结合深度强化学习(DRL)的动作探索策略,将(
)个时间步的目标状态数据存储至独立的目标轨迹回放缓冲区。该缓冲区包含
个时间步的训练数据
(含目标位置、四旋翼无人机位置及速度)和
个时间步的标签数据
(目标位置)。最终,我们采用监督学习方式对TP网络进行训练。TP网络的损失函数定义如下:
,
其中 是TP网络的参数。
3.3 策略评论家网络
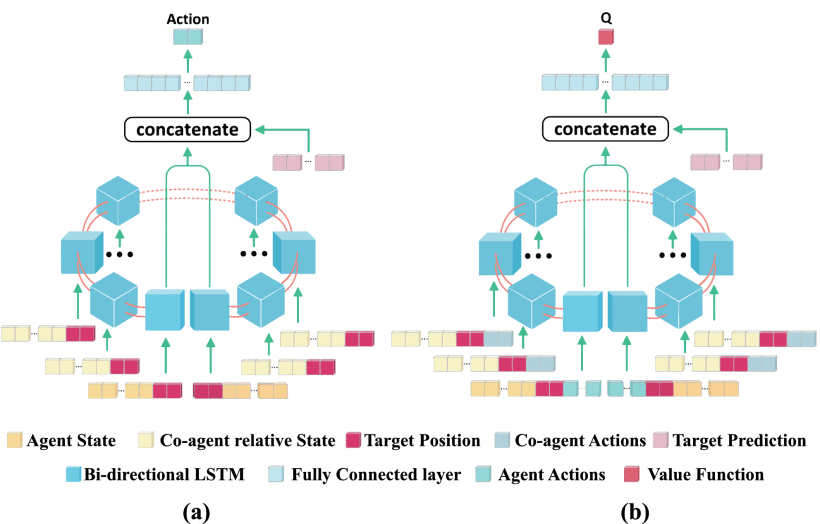
多智能体深度确定性策略梯度算法(MADDPG)受限于全连接网络结构(例如四旋翼飞行器智能体可能因故障损毁),无法适应智能体数量动态变化的协作场景。为此,本文提出了一种新型CBC-TP网络,可实现可变数量智能体间的通信。总体而言,CBC-TP网络为每个智能体配备了一个多智能体策略网络和一个多智能体评论网络,其架构如下图所示(a为CBC-TP策略网络,b为CBC-TP Q网络)。策略网络与评论网络均基于双向循环神经网络结构。值得关注的是,为实现网络结构的对称性,当前四旋翼无人机在双向LSTM中同时对应初始单元与最终单元。策略网络通过输入当前智能体状态及协作智能体的相对状态,输出当前无人机的动作指令,其中智能体i的CBC-TP网络策略网络输入细节详见下表。依托双向LSTM结构的优势,策略网络与评论网络可动态扩展以适配不同数量的智能体。

3.4 训练步骤
本节提出一种分层式多智能体深度强化学习算法,将传统评论家-演员(critic-actor)网络训练范式扩展至CBC-TP网络。该算法的核心设计体现在两个层面:
宏观训练架构:
-
TP网络:通过监督学习计算反向梯度
-
演员-评论网络:采用无监督学习范式
微观计算机制:
-
TP网络与演员-评论网络均采用时间反向传播(BPTT)算法进行梯度更新
-
梯度流通过所有智能体的状态-动作对聚合至Q函数与策略函数
-
奖励梯度受各智能体动作影响,并通过反向传播更新网络参数
算法整体流程详见图示:

为提升TP网络、策略网络与评论网络的更新效率,为每个四旋翼飞行器智能体构建双重回放缓冲区:
-
轨迹缓冲区
:存储智能体历史状态与目标轨迹数据(用于TP网络训练)
-
经验缓冲区
:按时间步记录MDP元组(
)(用于策略与评论网络更新)
其中,动作由观测
(
的子集)决策生成,训练过程中引入Ornstein-Uhlenbeck噪声(OU噪声)
,通过动作扰动提升算法鲁棒性与探索能力。
在追逃系统(PES)中,四旋翼飞行器智能体的核心目标包含双重约束:1)协同追踪目标;2)动态避障。若仅依赖单一奖励机制(如全局奖励或个体奖励),可能忽视团队协作由个体协作共同构成的事实。因此,本文提出复合奖励函数架构,其包含:
-
团队协作奖励(R_team):评估多智能体整体协作效率(如目标包围度、队形协同性)
-
个体奖励(R_individual):衡量单智能体行为效能(如避障成功率、能量消耗)
因此,本文的奖励函数设计如下:
,
其中, 分别代表团队奖励函数与个体奖励函数,分别定义如下:
,
其中, 表示四旋翼飞行器
与目标间的欧氏距离,
表示智能体
与最近障碍物的欧氏距离,
表示智能体与障碍物间的安全缓冲距离阈值(物理碰撞防护边界),
表示归一化因子,用于将奖励值缩放至(0,1)区间,确保梯度稳定性,
表示奖励系数常数,实验中设定为
。
奖励函数设计关键点:
归一化必要性:
-
未归一化的奖励可能导致策略网络陷入动作边界的局部极小值(如过度偏向避障而放弃追踪)。
-
通过ρ调节奖励量级,平衡不同任务目标(追踪、避障)的梯度贡献。
附加奖励机制:
-
碰撞惩罚:智能体撞击障碍物时施加固定负奖励(实验中设为-2),但允许受损智能体继续参与训练以丰富经验回放数据。
-
任务完成激励:所有智能体成功完成任务时给予统一正奖励(+5),强化目标导向行为。
四、实验
4.1 实验参数设置
基础参数:
-
折扣因子
-
网络更新系数
(用于目标网络软更新)
-
历史状态时间步长
-
单回合最大步数
网络学习率:
-
预测网络(TP Net):
-
策略网络(Policy Net):
-
评论网络(Critic Net):
经验回放机制:
-
回放缓冲区容量:
条经验
-
更新频率:每累积50条新经验触发网络参数更新
-
训练批大小(Batch Size):512
硬件配置:
-
CPU:Intel Xeon Silver 4114
-
内存:128GB
-
GPU:Nvidia GTX 2080Ti
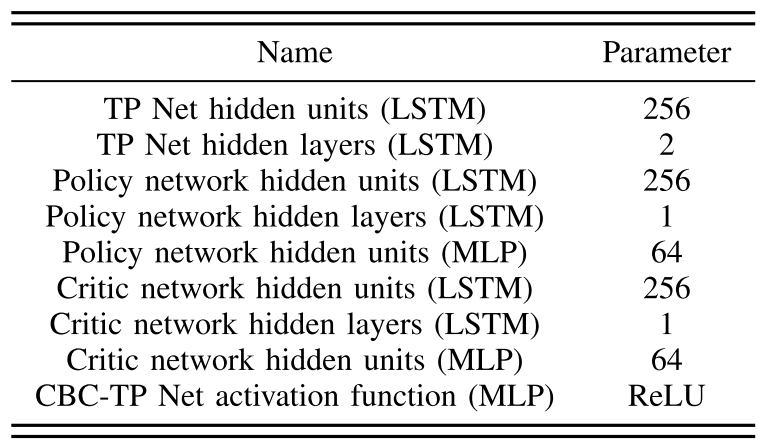
模型参数:CBC-TP网络详细参数见下表:
四旋翼平台:硬件技术参数见下表:

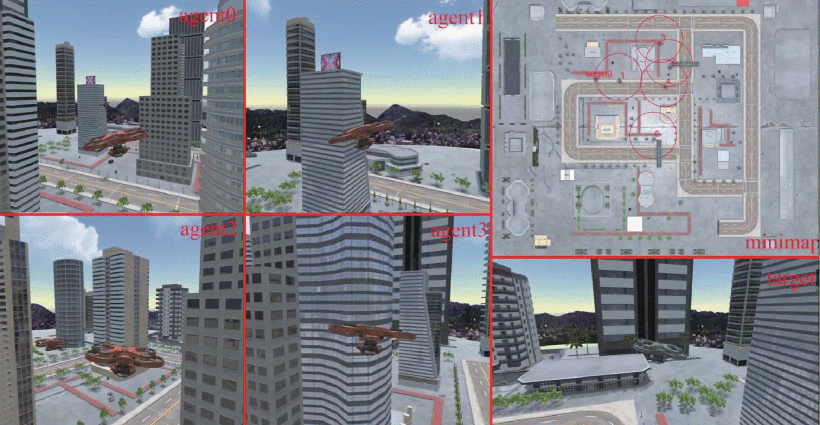
仿真场景如下:
4.2 评价指标与实验结果
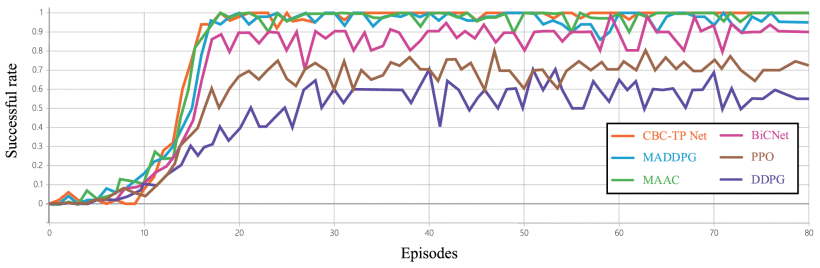
(1)任务成功率(Mission Successful Rates):每训练100个episodes,评估一下模型的成功率,评估结果如下图所示。可以看出,训练500个episodes之前的模型,任务成功率约为零;在训练800个episodes之后,模型的任务成功率开始显著增加;在训练2000个episodes之后,本文提出的算法模型可以达到100%的任务成功率。并且,与其他现有方法相比,CBC-TP Net的表现更加稳定。
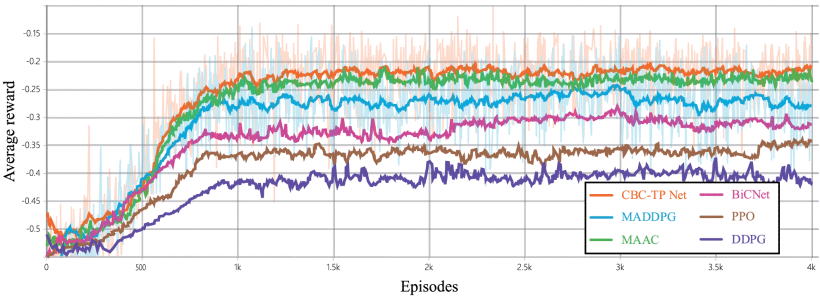
(2)平均奖励(Average Rewards):平均奖励定义为总奖励值除以每回合步数,评估结果如下图所示。可以看出平均奖励值在训练初期均呈现显著增长态势,随后进入稳定上升阶段,并在约1000次训练回合后趋于平稳。值得注意的是,CBC-TP Net算法的平均奖励曲线在约500次训练回合后展现出比MADDPG更早的加速上升趋势。
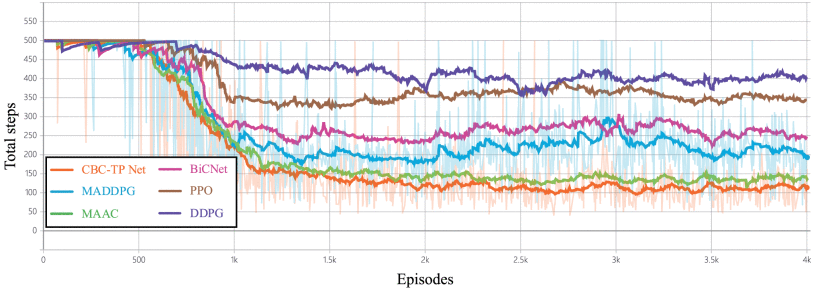
(3)训练步数(Episode Steps):下图展示了训练过程中的平均回合步数变化情况。可以看出,平均回合步数曲线呈现出明显的四阶段特征:初始阶段,代理由于尚未习得有效策略,持续以最大步数500探索环境;随后,代理优先学习障碍规避能力,此时虽然奖励值开始增长,但步数仍维持500步;中期阶段,代理逐渐意识到距离目标过远将导致负向奖励,开始同步优化路径规划与避障策略,其中CBC-TP Net代理得益于目标轨迹预测能力,能以更短路径接近目标;最终阶段,两类代理均能通过协同配合在100-150步内完成目标捕获,表明其已掌握无碰撞目标追踪的最优策略。
(4)对比实验:在性能评估中引入基于势能函数的PID控制器作为基线方法,并与深度强化学习算法进行对比分析。实验设置方面,通过在随机时间步施加5%水平扰动以验证算法鲁棒性。下表统计了CBC-TP Net与基线方法在1000次测试回合中的任务成功率和平均步数指标。结果显示:基于势能函数的PID控制器因目标移动速度超越四旋翼飞行器,仅能实现单一追踪而无法完成协同合围;相比之下,CBC-TP Net框架取得98.8%的任务成功率,高于较其他DRL方法,且目标捕获所需步数减少。

4.3 CBC-TP Net 与 CBC Net 对比实验
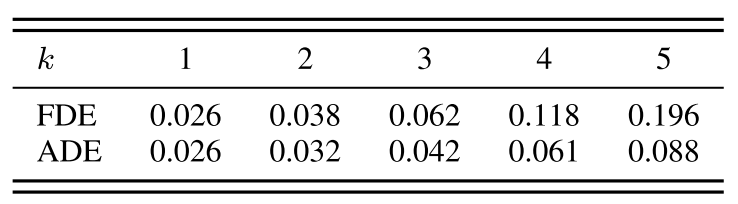
通过对比CBC-TP Net与CBC Net在PES任务中的表现,深入解析轨迹预测网络(TP Net)的效能。如下表所示,我们采用最终位移误差(FDE)与平均位移误差(ADE)作为评估指标,发现当预测步长k=3时,目标轨迹预测精度达到可接受水平。
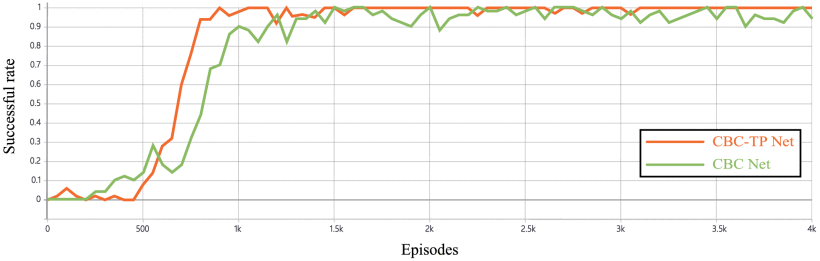
在任务成功率方面,从下图可以看出,未集成轨迹预测的CBC Net代理在前500-1000训练回合成功率低于约40%,在曲线后半部分,CBC Net的任务成功率在0.9-1之间波动,而CBC-TP Net代理后期成功率稳定维持在1附近;
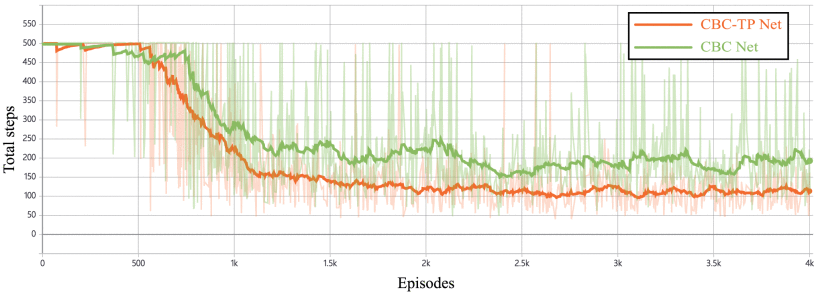
在回合步数方面,从下图可以看出,经过3000回合训练后,CBC-TP Net代理单回合步数较CBC Net减少约80步,展现出显著优化效果。
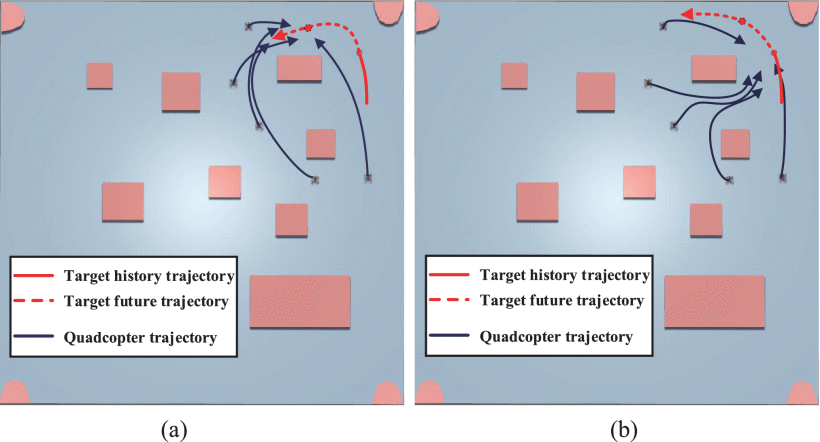
为深入验证TP Net的机制优势,设计了对照实验:在相同初始条件与目标逃逸策略(均采用参数同构的DDPG算法)下,如下图所示(a为CBC-TP Net,b为CBC Net),CBC Net代理仅基于目标当前状态生成动作策略,导致持续追踪却无法完成合围(因目标速度优势);而CBC-TP Net代理通过融合目标当前及未来状态预测,能够自主习得协同围捕策略,从而快速完成PES任务。该实验从机理层面揭示了轨迹预测模块对多智能体协作决策的关键提升作用。
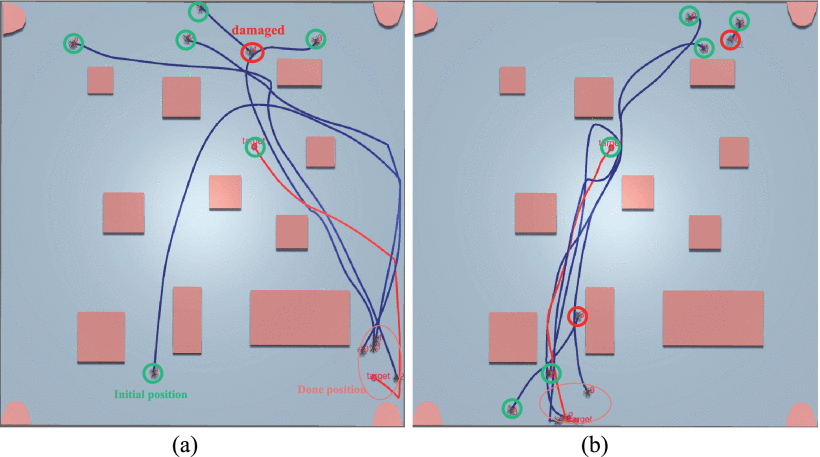
本研究提出多智能体系统的抗损伤能力:当部分代理因意外损毁无法继续执行任务时,剩余代理仍能自主调整策略以维持任务完成效能。得益于LSTM网络的独特优势(权重共享特性与可变长序列处理能力),经过充分训练的CBC-TP Net代理可通过与未损毁的可变数量代理进行通信,如下图所示(a为一架无人机损坏,b为两架无人机损坏),动态生成适应性的协同决策策略。实验数据显示:在单/双代理损毁场景下,剩余代理仍能生成趋近最优的任务执行路径,且决策过程几乎不受损毁节点影响。
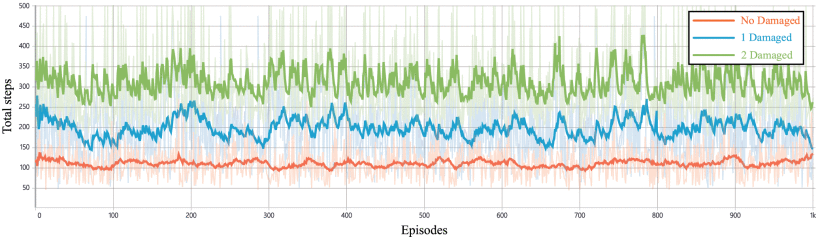
从下图和下表可以看出:在无代理损毁、单代理损毁及双代理损毁三种工况下,尽管性能指标随损毁代理数量增加呈梯度下降趋势,但系统仍保持高效的任务执行能力,验证了本文算法在动态损毁场景下的强鲁棒性。

五、结论
本文的贡献如下:
(1)基于 Unity 3-D 和 Python 提出了 DRL 交互环境;
(2)提出了向量化actor-critic框架CBC-TP网络,其各维度与现役四轴飞行器智能体对应,并在传统强化学习框架中扩展了用于目标轨迹预测的TP网络;
(3)设计了面向CBC-TP网络更新的分层多智能体深度强化学习算法,以及训练过程中有效的全局-个体奖励函数。

















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









