






begin end:
感觉是和C语言中的{}类似
比如:
always @(*)
if
...
else
...
同一句if else 可以不添加begin end,但是在always块整体,可能还是需要添加比较好,但是如果是:
always @(*)
begin
if(OE_n==1'b0)
if(G==1'b1)
DO=DI;
else
DO=DO;
else
DO=8'bz;
end
这种在 if语句下面的就可以不用添加。
//220707
变位宽fifo:
fifo_generator_0 your_instance_name (
.clk(clk), // input wire clk
.srst(rst), // input wire srst
.din(din), // input wire [255 : 0] din
.wr_en(wr_en), // input wire wr_en
.rd_en(rd_en), // input wire rd_en
.dout(dout), // output wire [511 : 0] dout
.full(full), // output wire full
.empty(empty) // output wire empty
);
依次写入256’d1,256’d2,读出512bit为{256’d1,256’d2}:类似大端传输的方式
测试波形图如下:
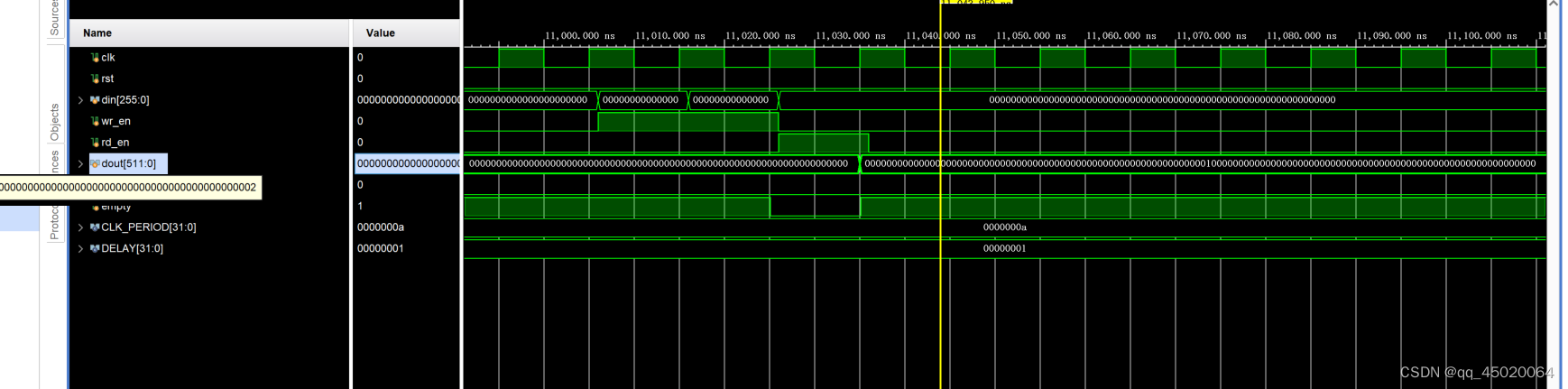
//220708
关于格雷码:
相邻代码间只有一位取值不同:模拟数据传输过程中,如果3变化到4,二进制码:4’b0011->4’b0100,总共3bit变化,如果每个bit位变化时间不一致,可能产生误码如4’b0000.而格雷码:0010->0110,只有1bit变化,误码可能性较低。
二进制码转化为格雷码:
(1)gray = (bin>>1)^bin;
格雷码转化为二进制码:
(2)bin[i] = ^(bin>>i);
//220709
FPGA中触发器类型:
//同步复位:
//FDR、FDRE(带时钟使能)
always @(posedge clk)begin
if(rst)
a <= 1'b0;
else
a <= ......
end
//同步置位:
//FDS、FDSE
always @(posedge clk)begin
if(rst)
a <= 1'b1;
else
a <= ......
end
//异步复位:
//FDC、FDCE
always @(posedge clk or posedge rst)begin
if(rst)
a <= 1'b0;
else
a <= ......
end
//异步置位:
//FDP、FDPE
always @(posedge clk or posedge rst)begin
if(rst)
a <= 1'b1;
else
a <= ......
end
//220727
最近开始使用native接口的block ram:
接口类型有:
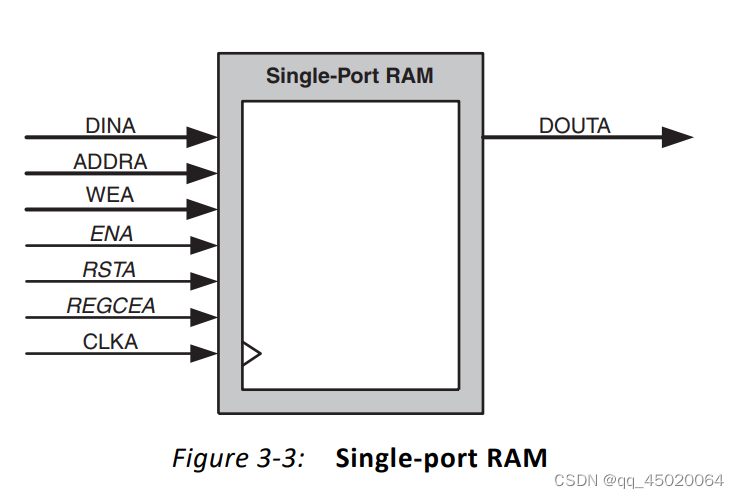
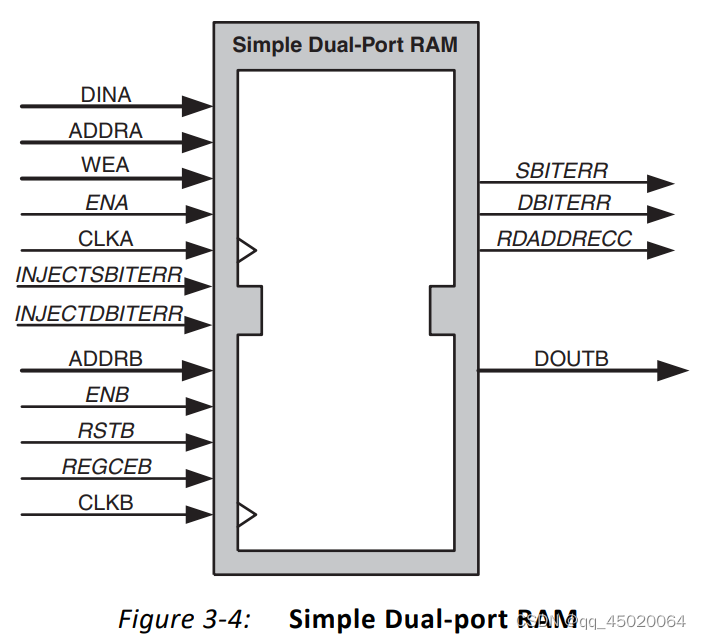
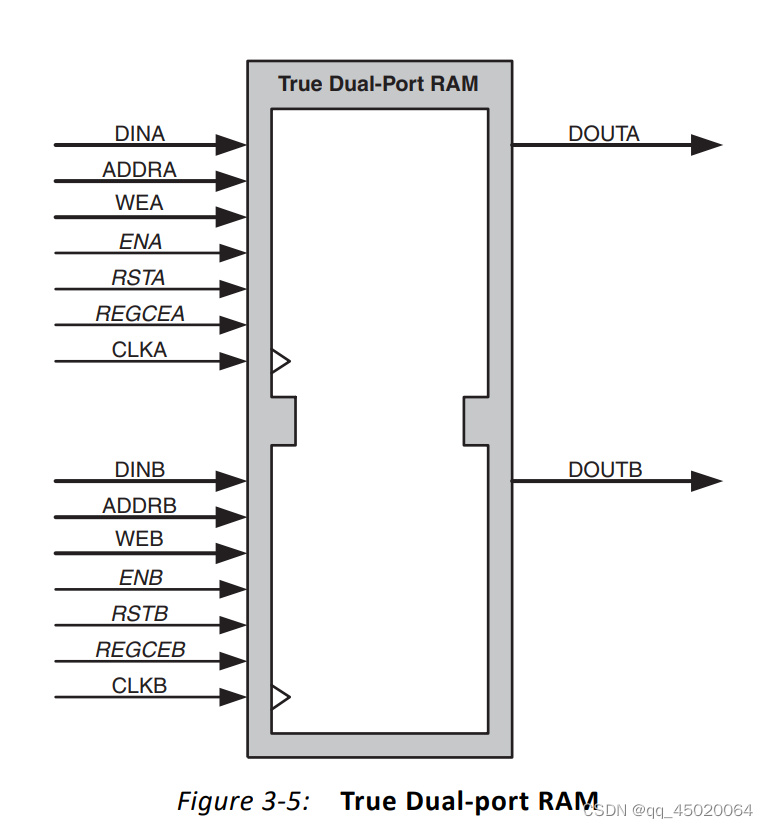
主要关注了read端口的数据输出延时问题:
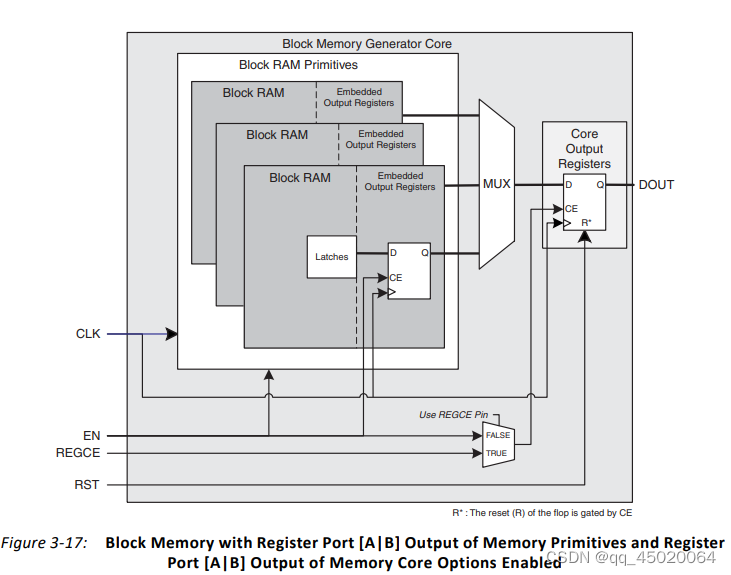
block ram输出部分可以配置为block ram 源语输出处寄存器和IP核输出处寄存器,如下图:
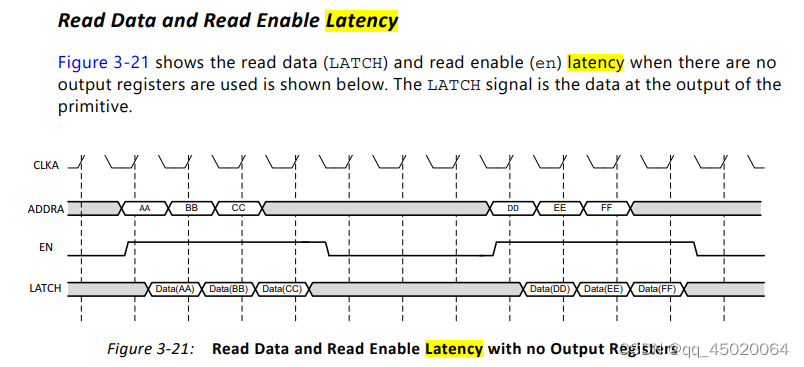
read端口,dout输出时序图:

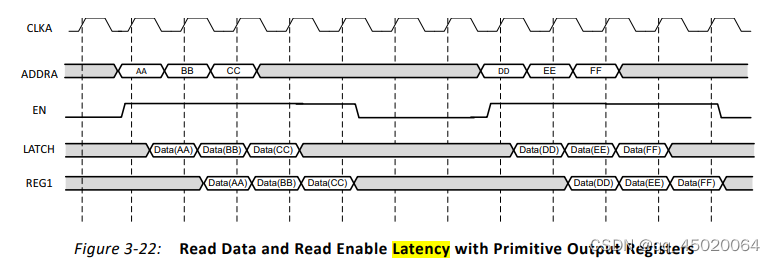
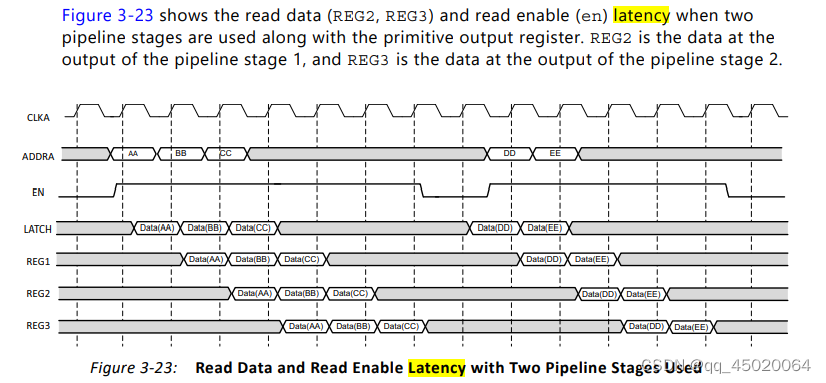

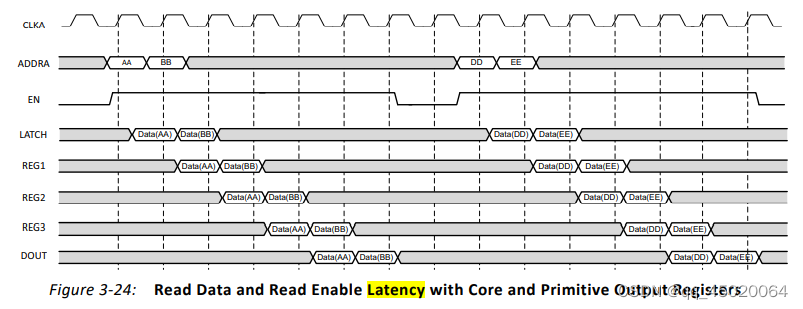
仿真结果如下:采用simple dual port ,输出端没有寄存器:结果如下:

写入端:ena与wea要同时为高,写入数据成功;
读出段:enb有效到读出数据dout有效有一拍延迟,并且bram存储值初始值为0。
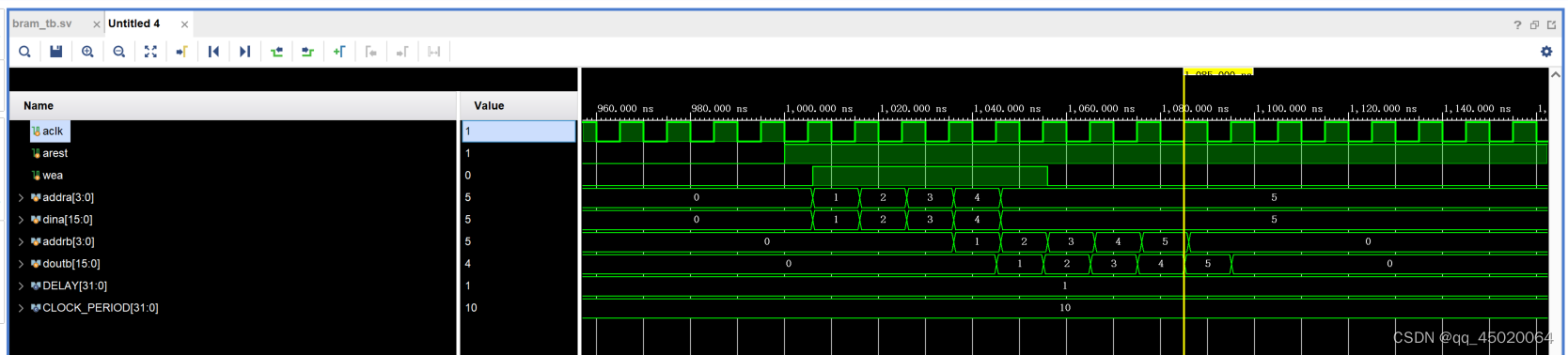
上图中,simple dual port配置为异步时钟,可以理解为ab端口互相独立,a的模式不影响b。(a端口nochange/write/read,b端口默认write first),b端口表现为read first。可以看出,简单双端口bram,a端口为写入端,b端口为读出端,互相独立并不影响。
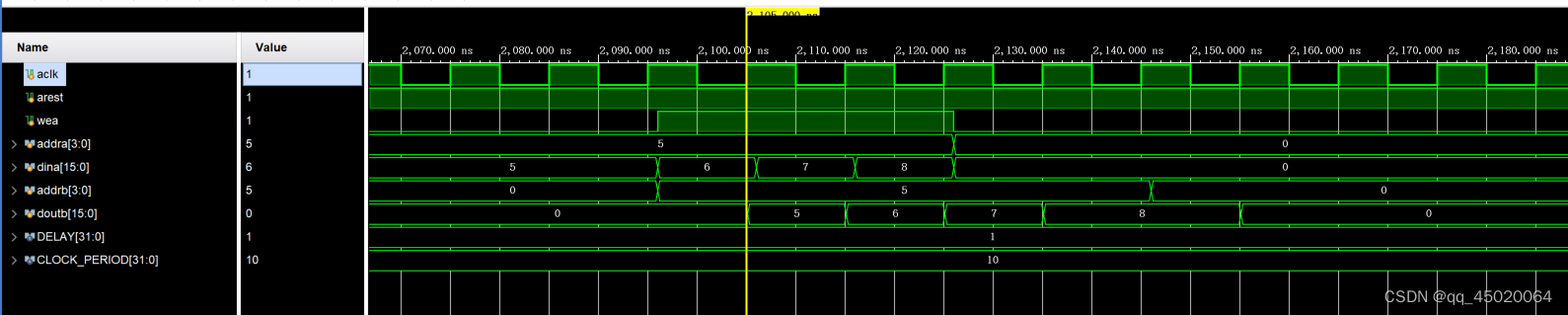
当A端写入同时B端读出,则B会读出写入前的值,与true dual port一样。
当simple dual port配置为common clk时,B端口默认为read first。可以认为ab端口有一定联系,a的模式write first会使得b端口表现为write first。其他两种模式不影响b,b表现为read first。
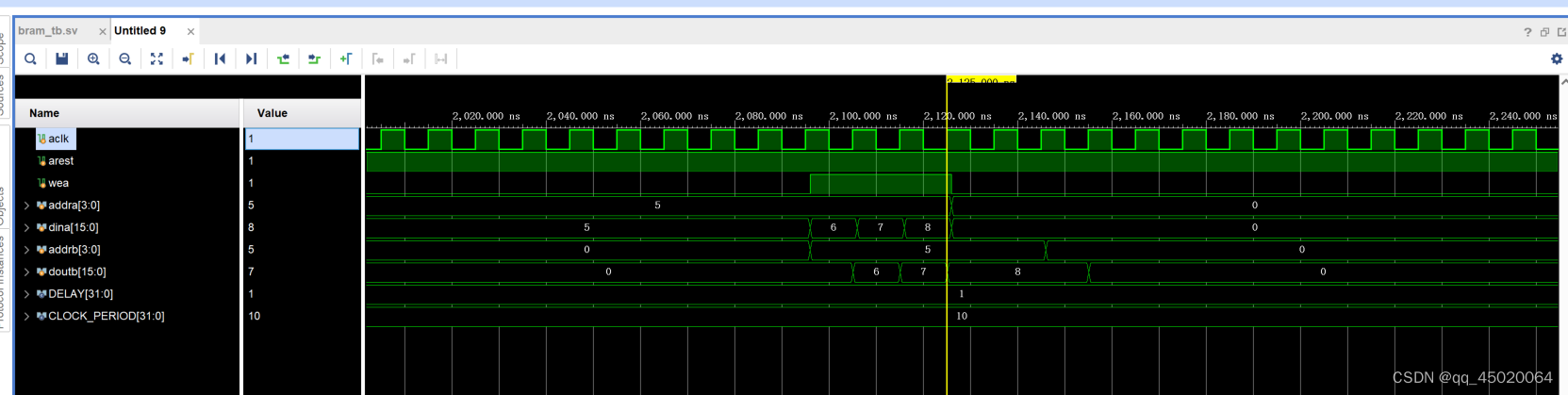
上图中(a端口write,b端口read first),b端口表现为write first。
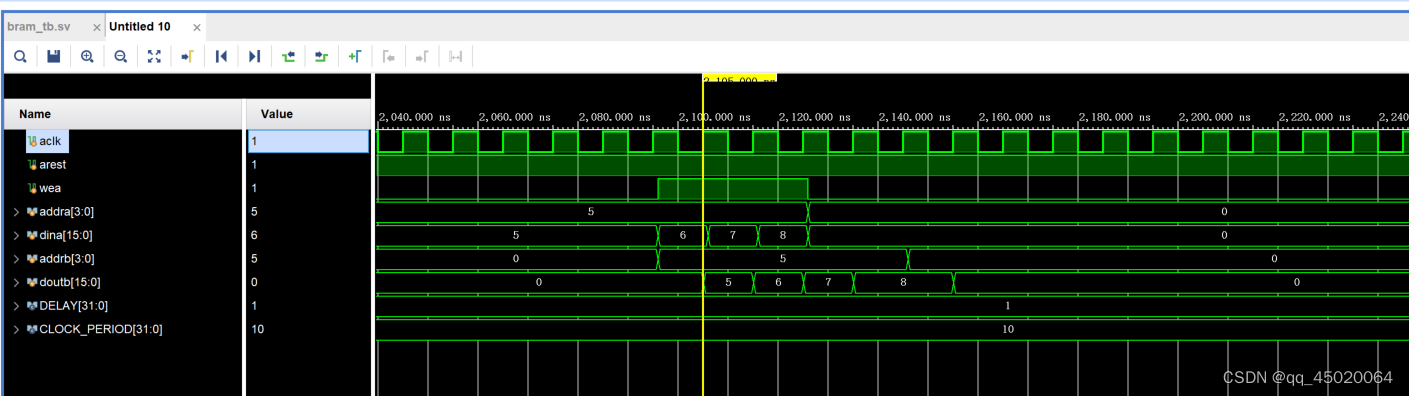
上图中(a端口read,b端口read first),b端口表现为read first。
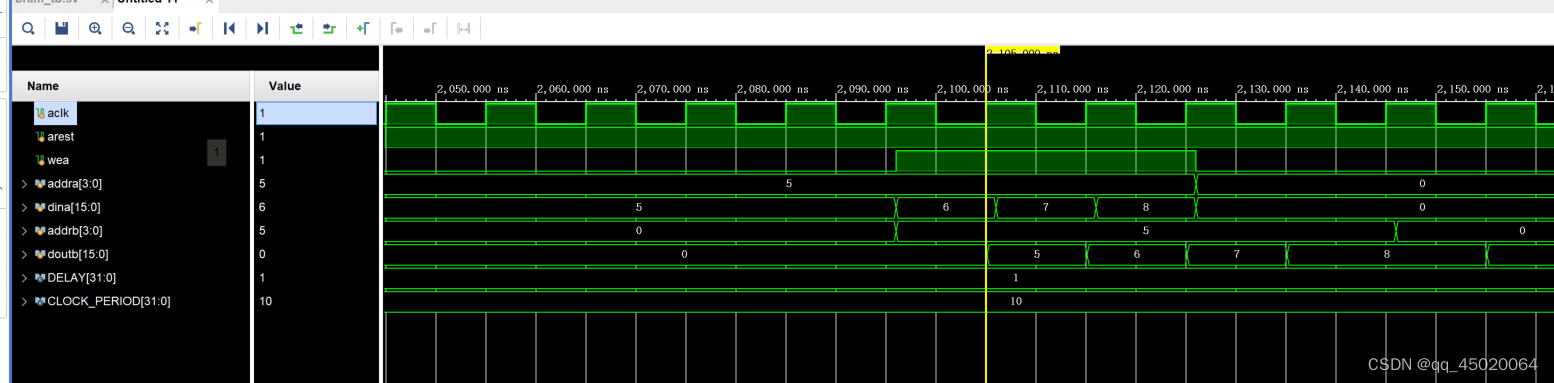
上图中(a端口no change,b端口read first),b端口表现为read first。
//220805
对于使用true dual port bram:
block design中接口为:

并且端口A和B均默认配置为WRITE FIRST:
接口读写时序如下:
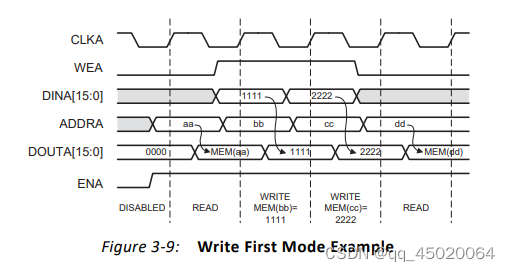
en有效时:当we有效,为写操作,下一个周期dout的值为上一周期写入的din;当we无效,为读操作。
仿真结果如下:
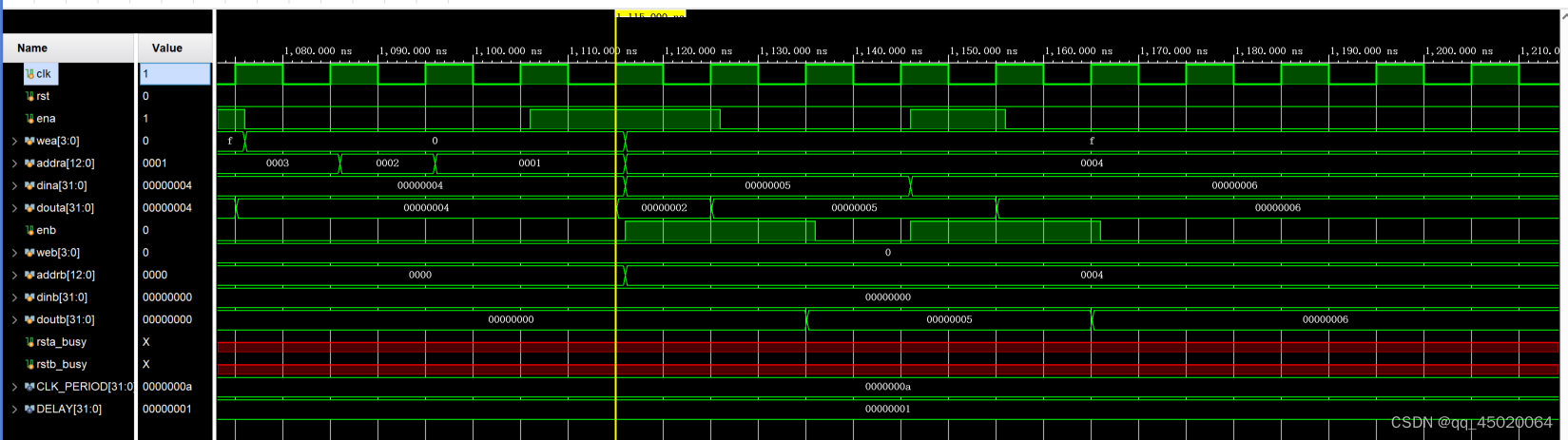
当A端写入同时B端读出,则B会读出写入前的值:
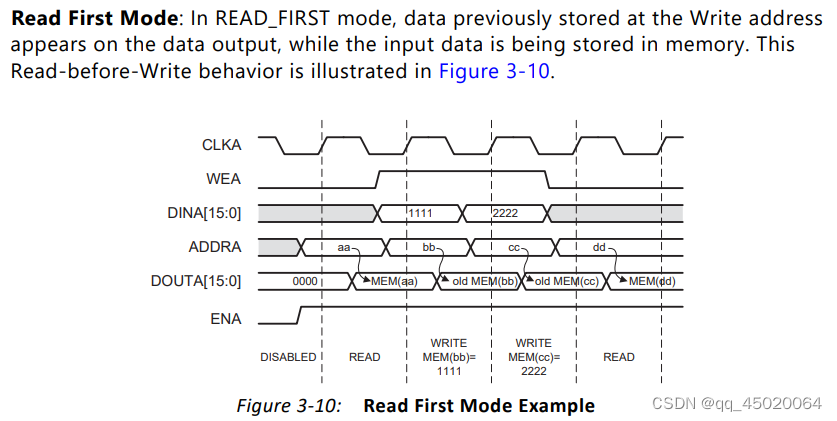
对于READ FIRST:
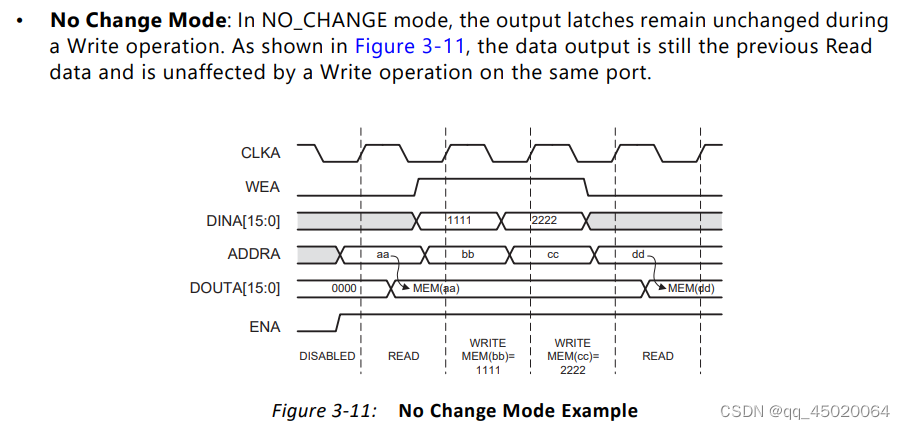
对于 NO CHANGE:
**当 true dual port 配置为common clk时,将ab设置为write first,ab地址不一致时,ab独立,各自端口写操作表现出各自的write first。当ab地址一致,且一端读、一端写,写端口自身为write first,并且影响读端口出现write first,如a往4地址写4,b读地址为4,dout均为a现在写入的4;两端同时写有冲突,要避免,时序如下图: **(xilinx该仿真模型有问题,与下板结果不一致!!!)
//220825
关于时序逻辑中添加#延时在不同位置仿真的不同结果:
`timescale 1ns/1ps
module test_delay ();
parameter DELAY = 1;
parameter CLK_PERIOD = 10;
logic clk;
logic rst;
logic [3:0] a,b,c;
always #(CLK_PERIOD/2) clk = ~clk;
initial begin
rst = 1;
clk = 0;
#(CLK_PERIOD*100+1);
rst = 0;
#(CLK_PERIOD*10000);
$stop();
end
always @(posedge clk or posedge rst)begin
if(rst)
a <=#DELAY 4'd0;
else
a <=#DELAY a + 4'd1;
end
always @(posedge clk or posedge rst)begin
if(rst)
b <=#(DELAY*2) 4'd0;
else
b <=#(DELAY*2) a;
end
always @(posedge clk or posedge rst)begin
#(DELAY*2)
if(rst)
c <= 4'd0;
else
c <= a;
end
endmodule
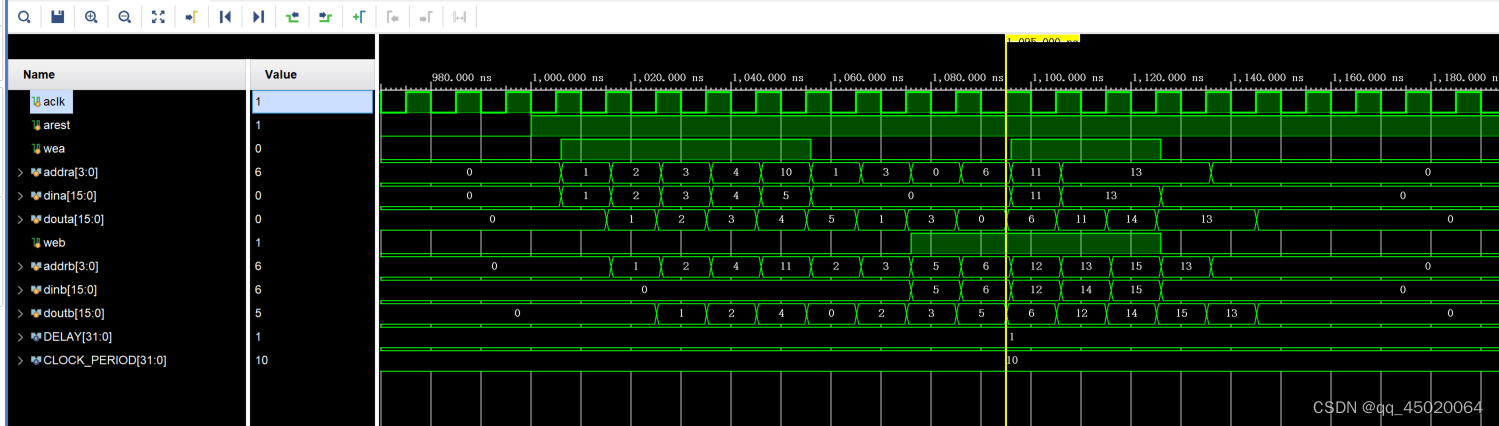
仿真结果如下:

b <=#DELAY a:b在时钟上升沿采样,然后DELAY后赋值。
#DELAY c <= a :c在时钟沿DELAY后,然后再采样,后续赋值。
//220928
?和z等价,表示高阻态。
对于case、casez、casex的用法:
真值表如下:
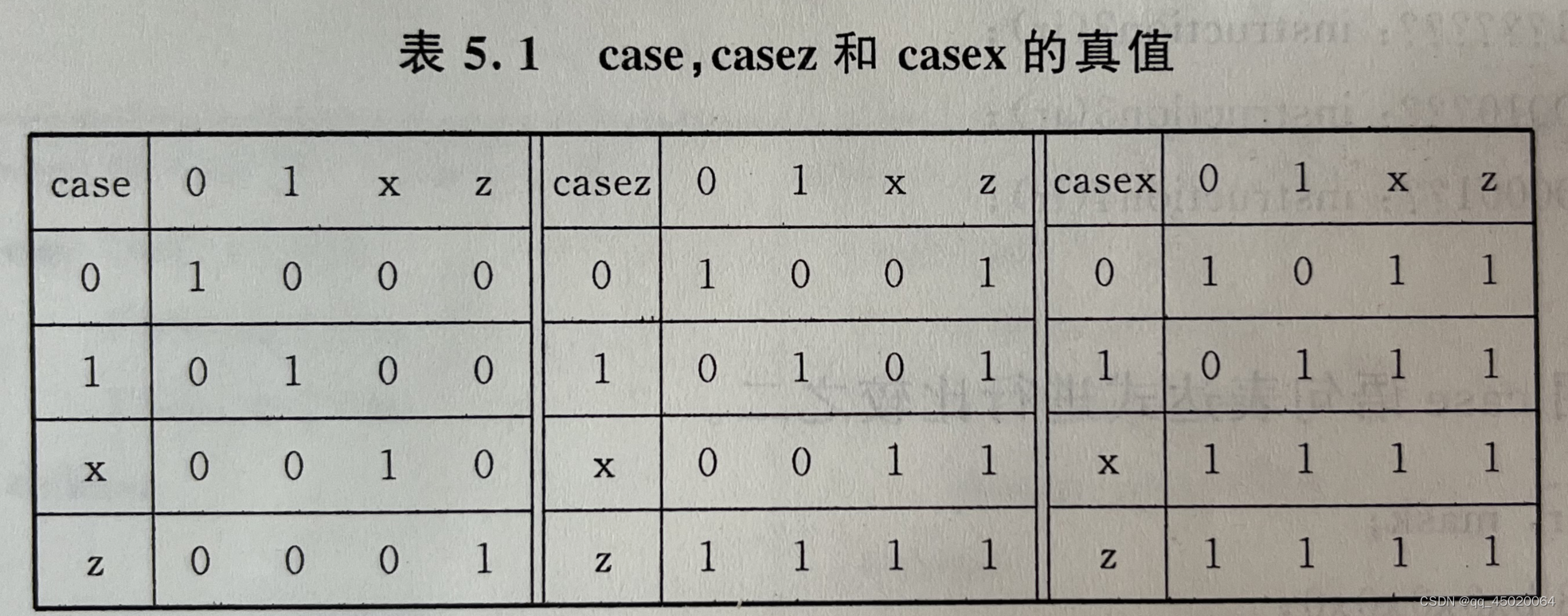
对于case:严格按照条件执行;
对于casez:casez(表达式)分支项1: 分支项2:…,表达式中的z以及分支项中的z的对比判断都需要忽略,默认真值为1;
对于casex:casex(表达式)分支项1: 分支项2:…,表达式中的z\x以及分支项中的z\x的对比判断都需要忽略,默认真值为1;
这样使用casez的好处是,可以忽略掉分支项与表达式中某些bit位的比较,比如:
casez(a)
4'b1???:
4'b01??:
4'b001?:
4'b0001:
endcasez
上述例子可以实现优先级分配,bit3优先级最高,bit0优先级最低。
//220928
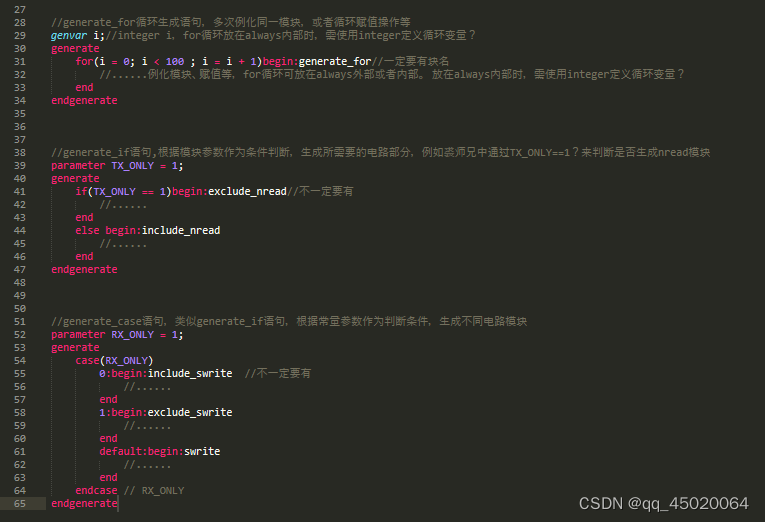
对于verilog中for循环和generate的使用:
参考:
1、https://blog.csdn.net/abcdef123456gg/article/details/102951636?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166433386416782428618106%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall%255Fv2.%2522%257D&request_id=166433386416782428618106&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2all_v2first_rank_ecpm_v1~rank_v31_ecpm-2-102951636-null-null.142v50control_1,201v3control_1&utm_term=verilog%E4%B8%AD%E7%9A%84generate%E8%AF%AD%E5%8F%A5&spm=1018.2226.3001.4187
2、https://blog.csdn.net/m0_47137431/article/details/108648522
大概总结一下如下所示:
//generate_for循环生成语句,多次例化同一模块,或者循环赋值操作等
genvar i;//integer i,for循环放在always内部时,需使用integer定义循环变量?
generate
for(i = 0; i < 100 ; i = i + 1)begin:generate_for//一定要有块名
//......例化模块、赋值等,for循环可放在always外部或者内部。 放在always内部时,需使用integer定义循环变量?
end
endgenerate
//generate_if语句,根据模块参数作为条件判断,生成所需要的电路部分,例如裘师兄中通过TX_ONLY==1?来判断是否生成nread模块
parameter TX_ONLY = 1;
generate
if(TX_ONLY == 1)begin:exclude_nread//不一定要有
//......
end
else begin:include_nread
//......
end
endgenerate
//generate_case语句,类似generate_if语句,根据常量参数作为判断条件,生成不同电路模块
parameter RX_ONLY = 1;
generate
case(RX_ONLY)
0:begin:include_swrite //不一定要有
//......
end
1:begin:exclude_swrite
//......
end
default:begin:swrite
//......
end
endcase // RX_ONLY
endgenerate
//221013
对于算数表达式的位宽问题,运算过程中的临时值的位宽应该会扩充到与整个表达式中(包括赋值左侧),最大位宽变量一致。
//221014
关于task使用:
task可以调用task和函数,反之函数不能调用task,但可以调用函数;
task中的输入输出,不能直接用于操作别的模块的输入输出;
例如top_tb.sv中例化了模块:
instance test(a,b);
调用task(a,b);task中对a、b的更改不会传递到test中。
//221103
Processor System Reset IP 复位顺序:
1、bus或者interconnect
2、peripheral
3、mb
//230209
拼接符{}使用:

此外,当想要将a + b的结果中的某些bit位赋值给c时,可采用:
c <= {a + b}[m:n];//时序
c = {a + b}[m:n];//组合
//230214
空语句:直接“;”即可
case(a)
default:;
endcase
或者:
case(a)
state1:begin
end
endcase
//220214
xilinx推荐高电平复位;altera推荐低电平复位;
参考文献:
https://cloud.tencent.com/developer/article/1801181?shareByChannel=link#1.4
https://mp.weixin.qq.com/s?__biz=MzUyNTc4NTk0OA==&mid=2247484081&idx=1&sn=fa274fe2976efb4908c61aa414ed30b0&chksm=fa198c82cd6e0594248f63bba2fd6a9b83b08e4b20e3aa19beba52eea24b6ca2ac7f2844ceb1&scene=21#wechat_redirect
//230221
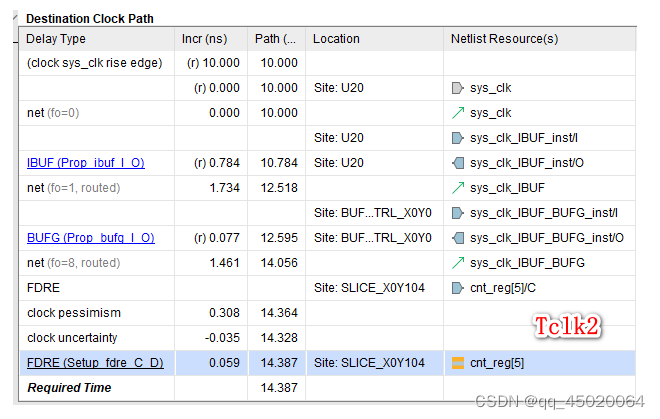
关于vivado时序报告,建立时间时序路径分析,目的时钟路径,最后的setup时间计算理解,原本是latch edge + tclk2 - Tsu,可能是考虑到C端到D端还有一段延时x,该延时减去Tsu,即x-Tsu = 0.059,所以最后加上了0.059。
//230604
关于 << 和 >> 位宽问题:
b <= a << n;
会将a低位补n个零,然后位宽增加n位赋值给b;
b <= a >> n;
会将a高位补n个零,然后位宽不变赋值给b;
//230707
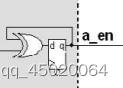
下图结构,初始化时异或门两端输入均为0,则输出a_en为0,此时当异或门输入有一周期脉冲出现,则会让a_en输出变为1;直到异或门的下一脉冲输入,则输出a_en变为0;也就是异或门输入的1周期脉冲信号会让a_en发生反转。
//230921
参考链接:
https://blog.csdn.net/NcowGboyL/article/details/103171723
https://blog.csdn.net/weixin_45791458/article/details/128754313
https://blog.csdn.net/weixin_45791458/article/details/128772558
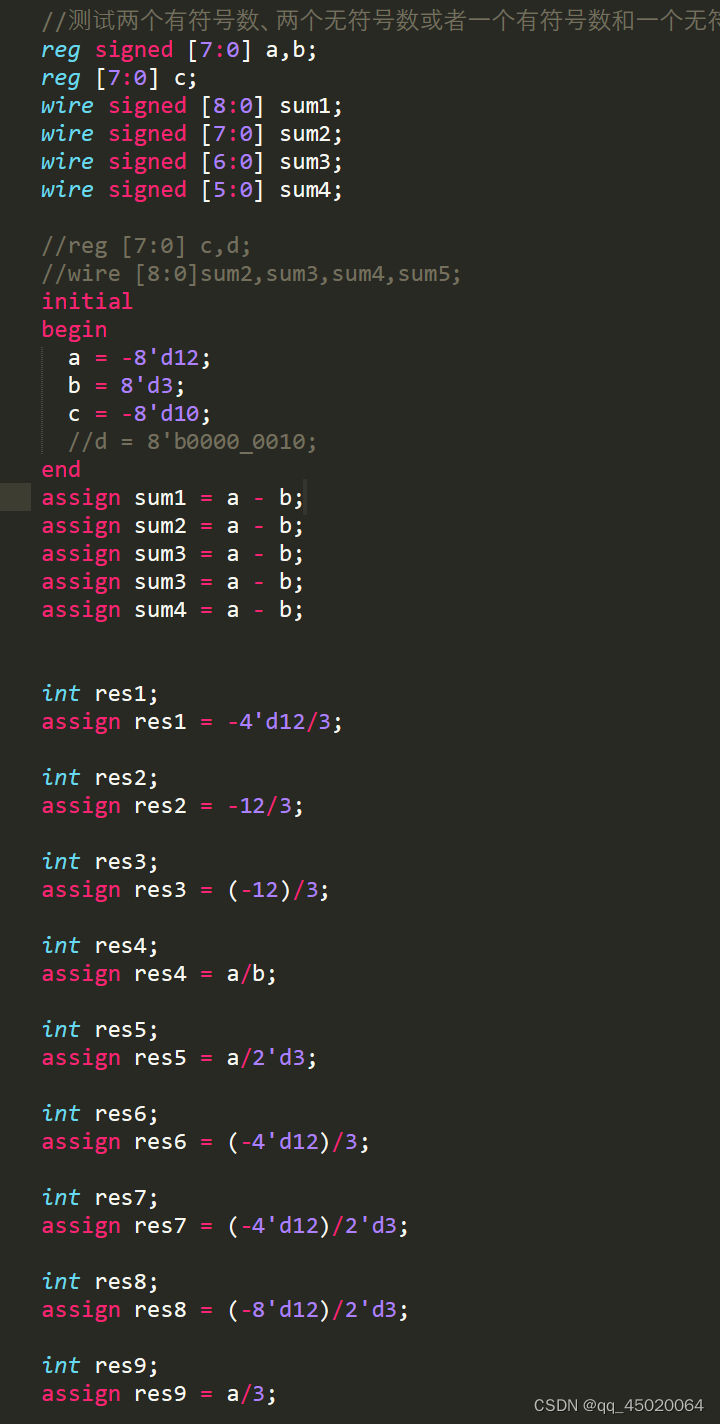
对于有符号数位宽扩展:
(1)首先表达式右边全为有符号数,才会进行有符号数运算;如果表达式右边存在无符号数,即进行无符号数运算,(其中未指定位宽和基数的为有符号数,如1、2等,而-3‘d2为无符号数)
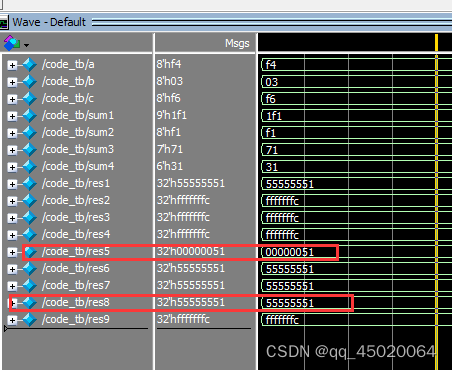
(2)位宽扩展根据表达式左右两边进行,一些测试样例如下,注意res5和res8的区别,对于res5,我的理解为a已经为一个确定的值-8’d12 = 8‘b1111_0100,当成无符号数扩展后还是32’h0000_00f4;而对于res8,-8’d12中8’d12先进行位宽扩展为32’d12,然后再取“-”得到32‘hffff_fff4。
//240206
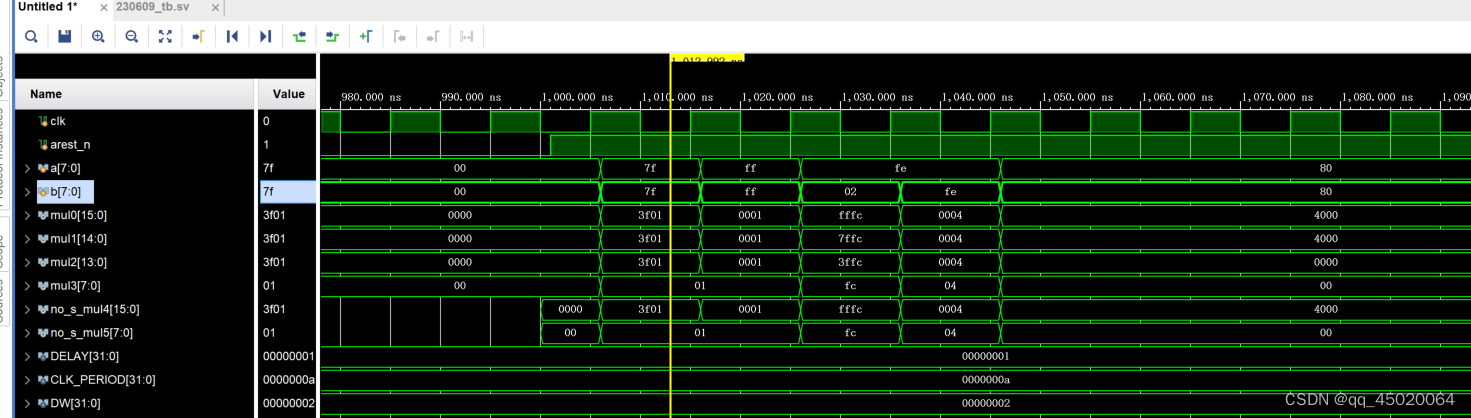
关于上述有符号数计算补充,右边计算的结果,赋值给左边为截断处理,如下图:
mul = signed(a) * signed(b);不管mul是有符号数还是无符号数,a * b的结果都截断后赋值给mul;
对于负数表示:
-4’d16,会将16截断为0,结果为-0 = 0;
所以负数的数值,需要用足够的位宽表示,如-5’d16;
//240103
对于建立时间时序分析:
arrive_time = Tlauntch_laytency+Tco+Tdelay_max;
require_time=Tcapture_laytency+Tclk-Tsu;
裕度:require_time-arrive_time;
对于保持时间时序分析:
arrive_time = Tlauntch_laytency+Tco+Tdelay_min;
require_time=Tcapture_laytency+Thd;
裕度:-(require_time-arrive_time);
对于最大输入延时:(类似于发射端的数据路径最大延时)
arrive_time = Tlauntch_laytency+Tinput_max;
require_time=Tcapture_laytency+Tclk-Tsu;
裕度:require_time-arrive_time;
对于最小输入延时:(类似于发射端的数据路径最小延时)
arrive_time = Tlauntch_laytency+Tinput_min;
require_time=Tcapture_laytency+Thd;
裕度:-(require_time-arrive_time);
对于最大输出延时:(类似于捕获端的建立时间)
arrive_time = Tlauntch_laytency+Tco+Tdelay_max;
require_time=Tcapture_laytency+Tclk-Toutput_max;
裕度:require_time-arrive_time;
对于最小输出延时:(类似于捕获端的保持时间,但是要取反,因为相对于虚拟时钟,hold所在的位置是捕获沿之后)
arrive_time = Tlauntch_laytency+Tco+Tdelay_min;
require_time=Tcapture_laytency+(-Touput_min);
裕度:-(require_time-arrive_time);
//240123
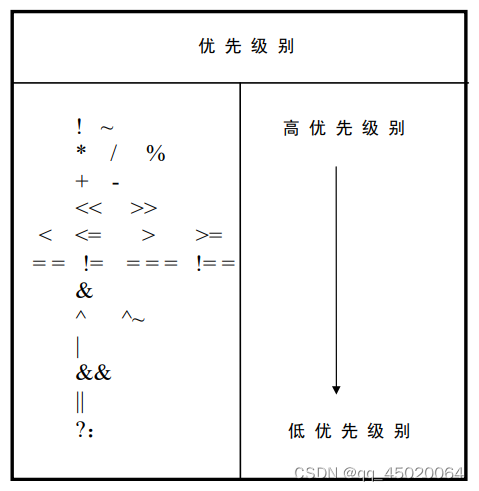
Verilog运算符优先级:















 3849
3849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









