







GRPO介绍
GRPO 是一种在线学习算法,这意味着它通过使用训练模型本身在训练期间生成的数据进行迭代改进。GRPO 目标背后的直觉是最大限度地利用生成的完成,同时确保模型始终接近参考策略。
GRPO 的发明者是 DeepSeek,最早是被用于微调 DeepSeek 的 R1 和 R1-Zero 模型 —— 它们可通过学习生成思维链(CoT)来更好地解决数学和逻辑问题。
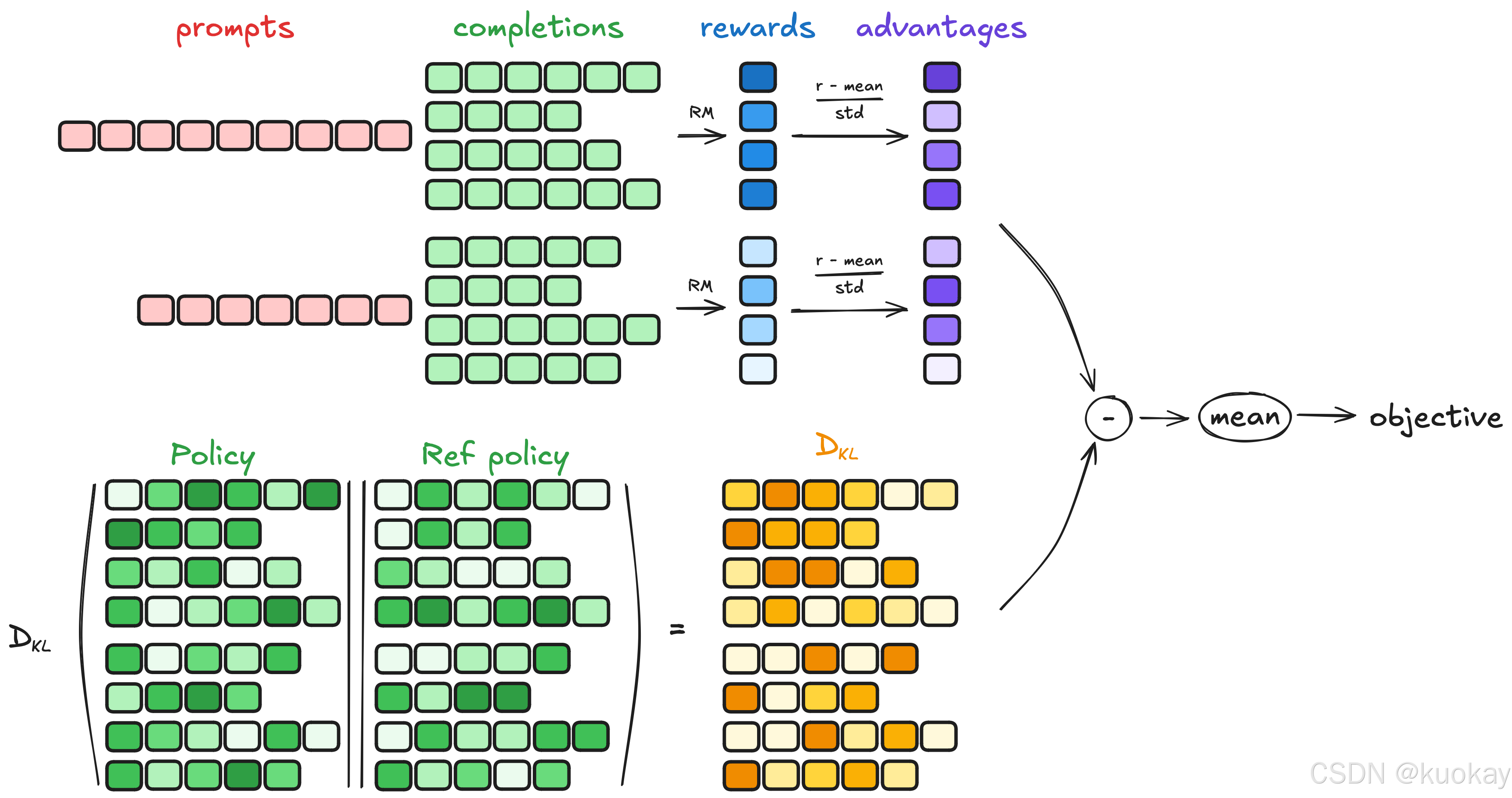
原理
https://github.com/huggingface/trl/blob/main/docs/source/grpo_trainer.md
要了解 GRPO 的工作原理,可以分为四个主要步骤:生成补全、计算优势、估计 KL 散度和计算损失。
-
生成补全(Generating completions)
在每一个训练步骤中,我们从提示(prompts)中采样一个批次(batch),并为每个提示生成一组 G个补全(completions)(记为oᵢ)。 -
计算优势(Computing the advantage)
对于每一个G序列,使用奖励模型(reward model)计算其奖励(reward)。为了与奖励模型的比较性质保持一致(通常在同一问题的输出比较数据集上进行训练),计算优势以反映这些相对比较。其归一化公式如下:
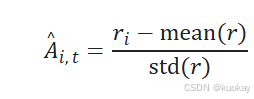
这种方法为该方法命名:组(群体)相关策略优化 (GRPO)。
群相对策略优化(GRPO)是一种强化学习(RL)算法,专门用于增强大型语言模型(LLM)的推理能力。与传统的RL方法不同,RL方法严重依赖外部评估者(批评者)来指导学习,GRPO通过相互评估响应组来优化模型。这种方法可以实现更有效的培训,使GRPO成为需要复杂解决问题和长思维链的推理任务的理想选择。
-
估计KL散度(Estimating the KL divergence)
KL 散度是使用 Schulman et al. (2020)引入的近似器估计的。近似器定义如下
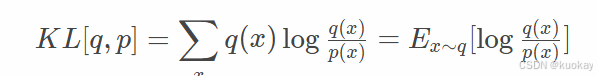
性质:KL 散度非负,且当且仅当 q(x)=p(x)对所有x 成立时,取值为 0:
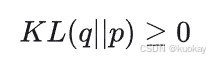
然而,在实际计算中,直接计算 KL 散度可能非常困难,主要原因如下:
- 需要对所有x进行求和或积分,计算成本高。
- 计算过程中可能涉及大规模概率分布,导致内存消耗过大。
因此,通常使用 近似方法 来计算 KL 散度。
-
计算损失(Computing the loss)
目标是最大限度地发挥优势,同时确保模型始终接近参考策略。因此,损失定义如下:
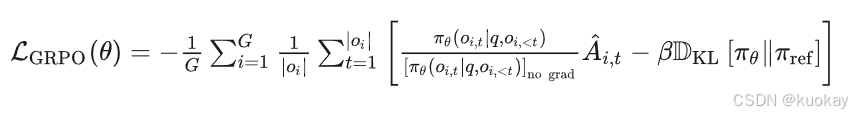
其中第一项表示缩放后的优势,第二项通过KL散度惩罚与参考策略的偏离。
在原始论文中,该公式被推广为在每次生成后通过利用裁剪替代目标(clipped surrogate objective)进行多次更新:
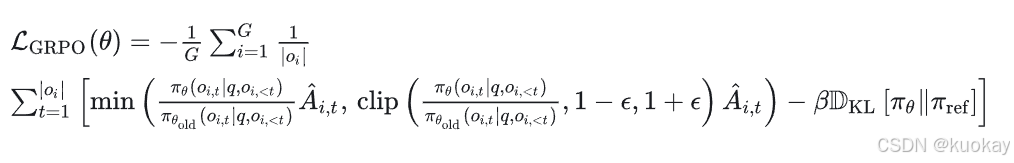
其中 clip(⋅,1−ϵ,1+ϵ) 通过将策略比率限制在1−ϵ和 1+ϵ 之间,确保更新不会过度偏离参考策略。
GRPO与PPO对比
在目前大语言模型中进行微调的流程中,一般在监督微调(Supervised Fine-Tuning, SFT)阶段之后,进一步通过强化学习对模型进行优化可以显著提升其性能。而Group Relative Policy Optimization (GRPO),就是使用在该阶段,替换传统的PPO算法。
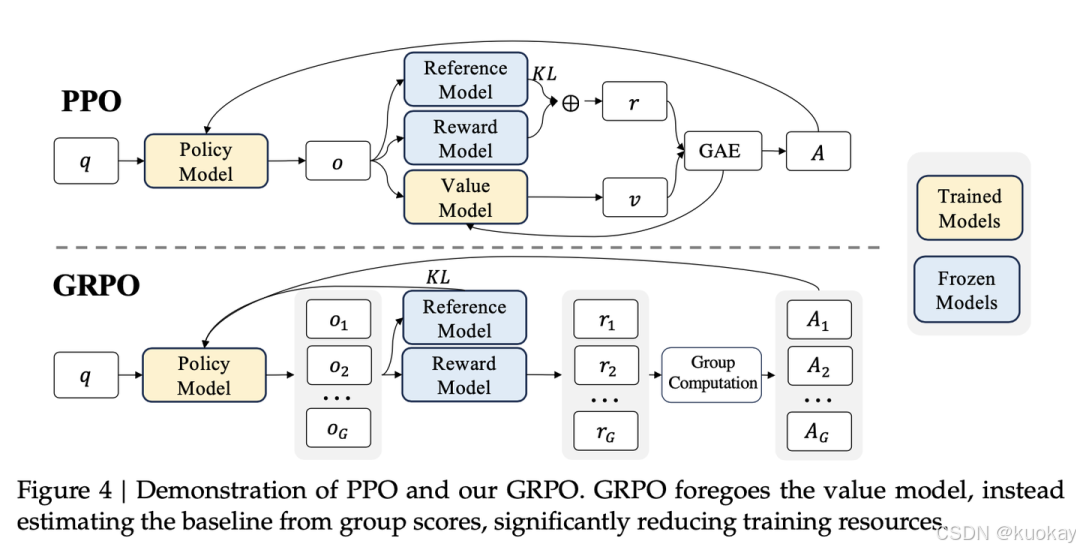
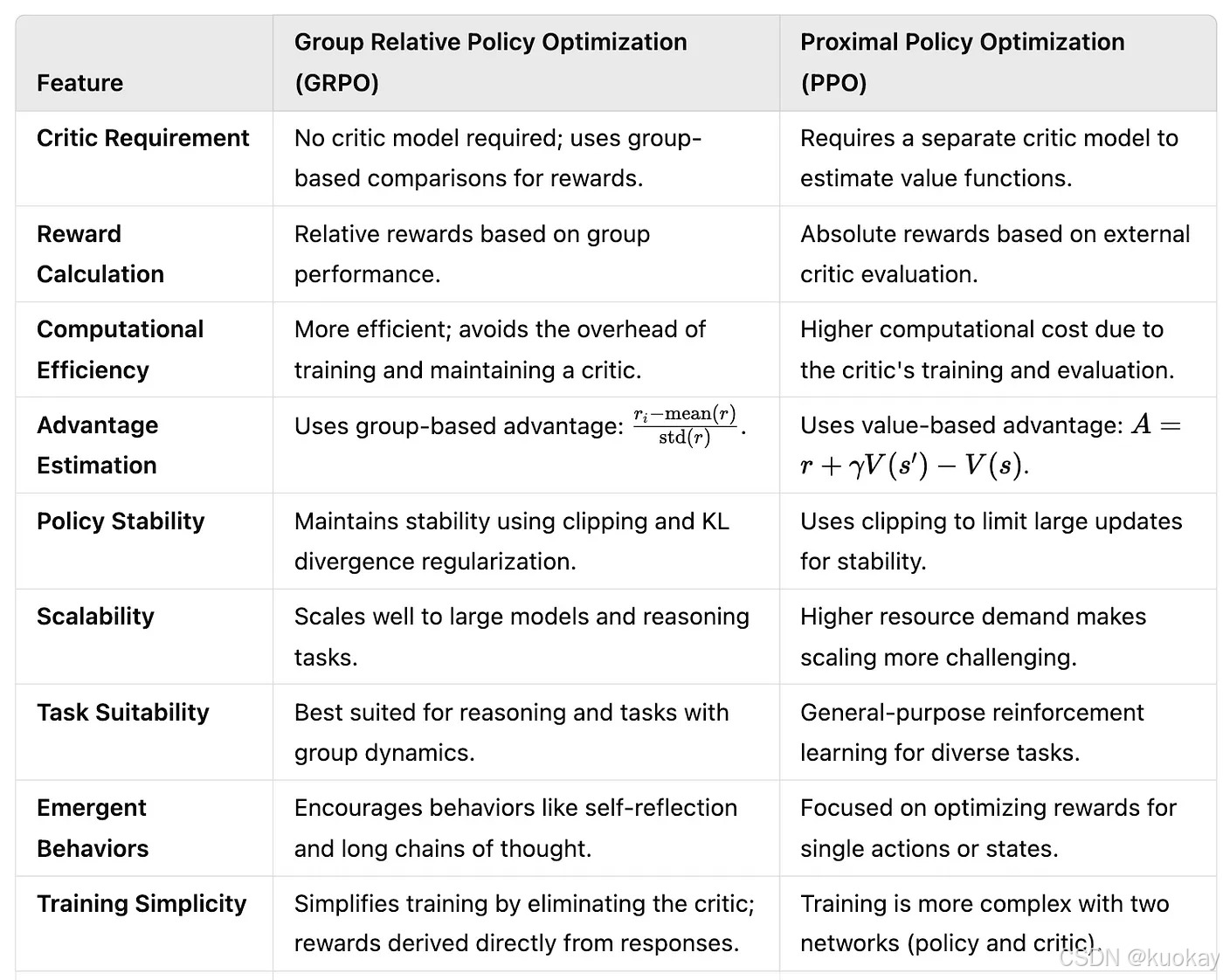
PPO(Proximal Policy Optimization)和GRPO(Group Relative Policy Optimization)都是强化学习中的重要算法,但在结构和实现方式上存在显著差异。
价值网络的使用:
-
PPO:依赖于一个与策略模型大小相当的价值网络(critic model)来估计优势函数(advantage function)。这个价值网络需要在每个时间步对状态进行评估,计算复杂度高,内存占用大。
-
GRPO:完全摒弃了价值网络,通过组内相对奖励来估计优势函数。这种方法通过比较同一状态下的多个动作的奖励值来计算相对优势,显著减少了计算和存储需求。
奖励计算方式:
-
PPO:使用广义优势估计(GAE)来计算优势函数,需要对每个动作的即时奖励和未来奖励的折扣总和进行估计。
-
GRPO:通过采样一组动作并计算它们的奖励值,然后对这些奖励值进行归一化处理,得到相对优势。这种方法更直接,减少了对复杂奖励模型的依赖。
策略更新机制:
-
PPO:通过裁剪概率比(clip operation)来限制策略更新的幅度,确保策略分布的变化在可控范围内。
-
GRPO:引入了KL散度约束,直接在损失函数中加入KL散度项,从而更精细地控制策略更新的幅度。
计算效率:
-
PPO:由于需要维护和更新价值网络,计算效率较低,尤其是在大规模语言模型中,训练过程可能变得非常缓慢。
-
GRPO:通过避免价值网络的使用,显著提高了计算效率,降低了内存占用,更适合大规模语言模型的微调。
快速开始
训练流程
DeepSeek模型采用了GRPO算法进行强化学习微调,其训练流程如下:
-
初始化模型:选择一个预训练的大型语言模型(如 DeepSeek-V3-Base)作为基础模型。
-
监督微调(SFT)阶段:首先使用高质量的标注数据对基础模型进行监督微调,使模型在特定任务上具备初步的性能。
-
强化学习(RL)阶段:在监督微调的基础上,引入GRPO算法进行强化学习微调。
-
定义任务和奖励:
- 任务:例如数学问题求解、代码生成、逻辑推理等。
- 准确性奖励:答案是否正确。
格式奖励:推理过程是否遵循指定的格式(<think> 和 <answer> )。
-
采样动作组:对于每个输入提示,模型根据当前策略生成一组不同的输出。这些输出的多样性为后续的相对奖励计算提供了基础。
-
计算组内相对奖励:
- 对这组输出进行评分,计算每个输出的奖励(例如,答案是否正确、推理过程是否合理)。
- 然后,计算每个输出的相对优势,即它的奖励相对于组内其他输出的表现如何。
-
策略更新和迭代优化:
- 根据这些相对优势,调整策略模型,使得表现较好的输出更有可能被生成,而表现较差的输出被抑制。
- 这个过程通过数学公式(如梯度上升)来实现,逐步优化模型的策略。
演示案例
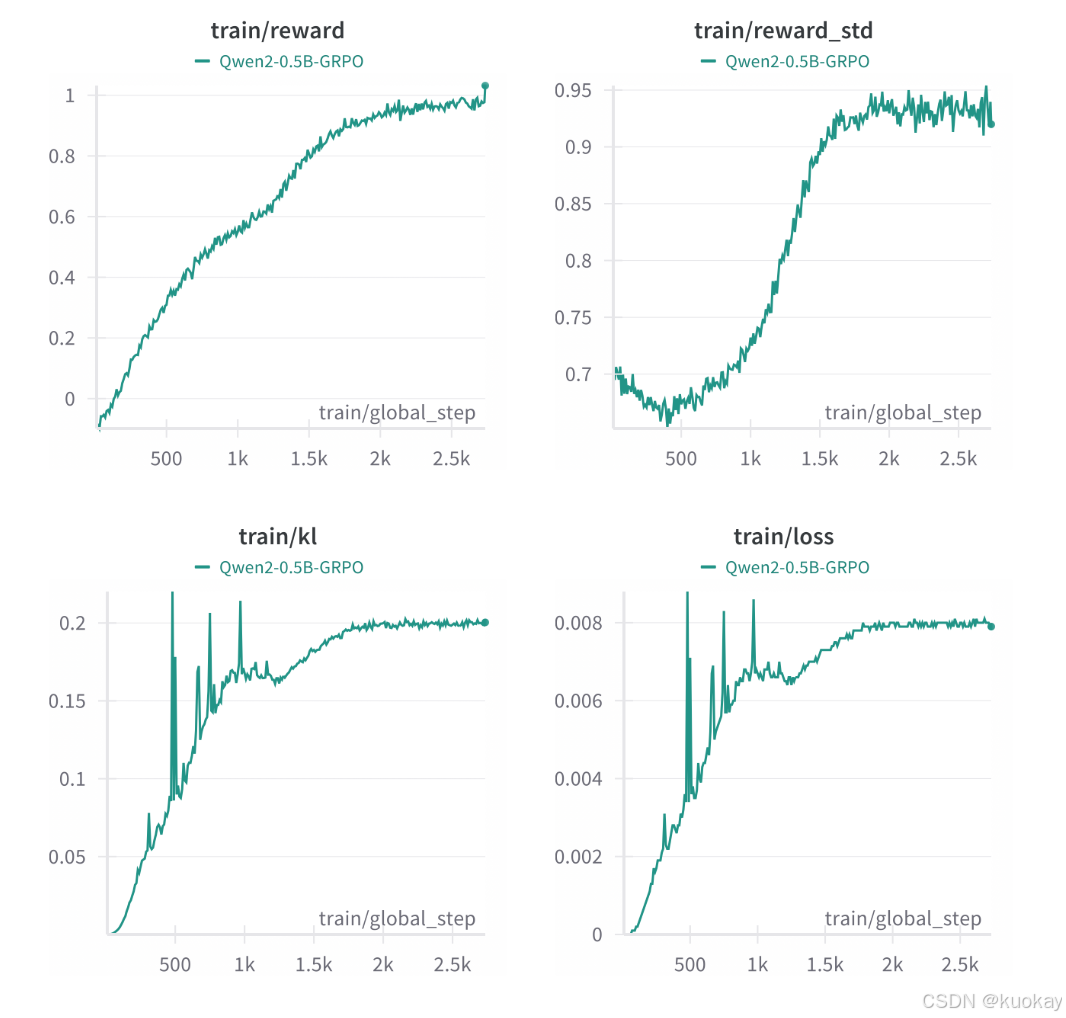
此示例演示如何使用 GRPO 方法训练模型。
我们使用 TLDR数据集中的提示训练 Qwen 0.5B Instruct 模型。
下面是用于训练模型的脚本。
# train_grpo.py
from datasets import load_dataset
from trl import GRPOConfig, GRPOTrainer
dataset = load_dataset("trl-lib/tldr", split="train")
# Define the reward function, which rewards completions that are close to 20 characters
def reward_len(completions, **kwargs):
return [-abs(20 - len(completion)) for completion in completions]
training_args = GRPOConfig(output_dir="Qwen2-0.5B-GRPO", logging_steps=10)
trainer = GRPOTrainer(
model="Qwen/Qwen2-0.5B-Instruct",
reward_funcs=reward_len,
args=training_args,
train_dataset=dataset,
)
trainer.train()
使用以下命令执行脚本:
accelerate launch train_grpo.py
训练分布在 8 个 GPU 上,大约需要 1 天。



















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











