









AGKD-BML: Defense Against Adversarial Attack by Attention Guided
Knowledge Distillation and Bi-directional Metric Learning
Hong Wang, Yuefan Deng, Shinjae Yoo, Haibin Ling, Yuewei Lin
Stony Brook University, Stony Brook, NY, USA
Brookhaven National Laboratory, Upton, NY, USA
摘要
虽然深度神经网络在许多任务中表现出令人印象深刻的性能,但它们对精心设计的对抗性攻击很脆弱。我们提出了一种基于注意引导知识提取和双向度量学习(AGKD-BML)的对抗性训练模型。注意力知识从一个在干净数据集上训练的权重固定模型(称为教师模型)中获得,并转移到一个在对抗性示例(AEs)上训练的模型(称为学生模型)。通过这种方式,学生模型能够专注于正确的区域,并纠正被AEs破坏的中间特征,以最终提高模型精度。此外,为了有效地正则化特征空间中的表示,我们提出了一种双向度量学习。具体来说,给定一个干净的图像,它首先会被攻击到最混乱的级别,以获得前向AE。然后,在最混乱的类别中随机选取一个干净的图像,并攻击回原始类别,以获得向后的AE。然后利用三重损失来缩短原始图像与其AE之间的表示距离,同时放大前向和后向AE之间的表示距离。我们在两个使用广泛的数据集上进行了广泛的对抗性鲁棒性实验。我们提出的AGKD-BML模型始终优于最先进的方法。AGKD-BML的代码将在以下网址提供:https://github.com/hongw579/AGKD-BML
一、介绍
深度神经网络(DNN)在计算机视觉[23]、语音识别[17]和自然语言处理[8]等领域取得了重大突破。然而,他们对所谓的对抗性示例(AEs)是经过精心设计但添加了难以察觉的干扰的数据,已经引起了极大的关注[39]。AEs的存在对DNN在现实应用中的安全性和安全性构成了潜在威胁。因此,人们做出了许多努力来抵御对抗性攻击,并提高机器学习模型的对抗性鲁棒性。特别是,基于对抗训练[16,28]的模型是最有效和最流行的防御方法之一。对抗式训练解决了一个最小-最大优化问题,其中的内在问题是在一个ε−ball算法通过最大化损失函数来实现,而外部问题是最小化AE的分类损失。Madry等人[28]提出了一种多步投影梯度下降(PGD)模型,该模型已成为对抗训练的标准模型。在PGD之后,最近提出了一些工作,从不同方面改进对抗训练,例如[6,11,29,33,36,43,50,52]。
然而,基于对抗性训练的模型在干净的和对抗性的例子中仍然存在相对较差的泛化能力。现有基于模型注意力的的对抗性训练只关注利用对抗实例的实时训练模型,其可能被破坏,但是还没有从干净图像上训练的模型中很好地探索信息。在这项工作中,我们的目标是通过提取注意知识和利用双向度量学习来提高模型的对抗鲁棒性。

图1。第一列是一幅干净的图像(“德国牧羊犬”)及其敌对的例子(被错误地归类为“天文馆”)。第二、第三和第四列分别显示了正确和错误标签的类相关注意图(Grad-CAM),以及与类无关的注意图。这表明敌对干扰破坏了注意力地图。
注意力机制在人类视觉系统中起着关键作用,广泛应用于各种应用任务[35,54]。不幸的是,我们的一个观察结果表明,对抗性示例(AE)中的扰动将通过网络得到增强,从而显著破坏中间特征和注意图。如图1所示,AE通过让模型聚焦于干净图像的不同区域,从而混淆了模型。直观地说,如果我们能够将干净图像的知识从教师模型转移到学生模型,1)获得正确的注意信息,2)纠正被AE破坏的中间特征,我们应该能够提高模型的对抗鲁棒性。
基于这种动机,我们提出了一个注意力引导的知识蒸馏(AGKD)模块,该模块应用知识蒸馏(KD)[18]来有效地将相应干净图像的注意力知识从教师模型转移到训练中的学生模型。具体来说,教师模型是在原始干净图像上预先训练的,并将在训练期间固定,而学生模型是在训练模型上。从教师模型中获得的干净图像的注意力图用于指导学生模型针对扰动生成相应AE的注意力图。
我们进一步使用t-分布随机邻域嵌入(t-SNE)来研究潜在特征空间中AE的行为(见图3),并观察到AE的表示通常远离其原始类别,类似于[29]所示。AGKD将干净图像的信息从教师模型传输到学生模型,从而对AE与其对应的干净图像之间的相似性提供约束,但不考虑来自不同班级的样本的约束。之前的工作[25,29,53]提出使用度量学习来规范不同类别的潜在表示。具体而言,利用了三重损失,其中清洁图像的潜在表示、其对应的AE和来自另一类的图像分别被视为正、锚和负示例。然而,这种策略只考虑了单向的对抗性攻击,即从干净的图像到它的对抗性示例,从而降低了效率。
为了解决上述问题,我们提出了一种双向攻击度量学习(BML),以提供更高效、更强的约束。具体来说,原始的干净图像(正片)首先被攻击到其最混乱的类,即除了正确的标签之外损失最小的类,以获得正面对抗示例(锚定)。然后,从最容易混淆的类别中随机选取一个干净的图像,并攻击原始图像,以获得反向敌对示例作为负面。
通过集成AGKD和BML,我们的AGKD-BML模型在两个广泛使用的数据集(CIFAR-10和SVHN)上在不同攻击下的性能优于最先进的模型。总之,我们的贡献有三个方面:
1.提出了一个注意力引导的知识提取模块,将干净图像的注意力信息传递到学生模型中,从而纠正被敌对示例破坏的中间特征。
2.提出了一种双向度量学习方法,通过显式缩短原始图像与其前向对抗示例之间的距离,有效地约束不同类别在特征空间中的表示,同时扩大前向对抗性范例和后向对抗性范例之间的距离。
3.我们在不同攻击下对广泛使用的数据集进行了广泛的对抗性鲁棒性实验,提出的AGKD-BML模型在定性(可视化)和定量证据方面都优于最先进的方法。
二、相关工作
对抗性攻击:通常,有两种类型的对抗性攻击:白盒攻击,对手可以完全访问目标模型,包括模型参数;黑盒攻击,对手几乎不知道目标模型。对于白盒攻击,Szegedy等人[39]发现了深层网络对抗性攻击的脆弱性。他们使用一种框约束的L-BFGS方法来产生有效的对抗性攻击。之后,开发了几种生成对抗性示例的算法。作为一种一步攻击,在[16]中提出的快速梯度符号法(FGSM)使用梯度符号来生成攻击,其中∞-受规范约束。在[24]中,Kurakin等人通过迭代应用FGSM对其进行了扩展,并设计了基本迭代法(BIM)。[12]中提出了一种BIM变体,将动量整合到其中。DeepFool[30]试图根据到超平面的距离找到最小扰动,并量化分类器的鲁棒性。在[32]中,作者介绍了一种基于雅可比矩阵的显著性映射攻击。投影梯度下降(PGD)是[28]中提出的一种多步攻击方法。CW攻击是一种基于边缘的攻击,在[4]中提出。最近,Croce等人引入了一种名为AutoAttack[10]的无参数攻击,它是PGD攻击的两种无参数版本和另外两种互补攻击的集合,即FAB[9]和Square攻击[1]。它根据每个样本在这四种不同攻击(包括白盒和黑盒攻击)中的最坏情况对每个样本进行评估。除了加法攻击,[14,15,20]表明,即使是小的几何变换,如仿射或投影变换,也可以愚弄分类器。除了对输入模型的图像进行攻击外,还试图设计对抗性补丁,在物理世界中欺骗模型[13,19,24]。另一方面,对抗性攻击也可以用来提高模型的性能[45,26,31]。
对抗性防守:基于对抗性训练的模型,其目的是将分类损失最小化到最强的对抗性示例(在一个?−球),被认为是最有效和最广泛使用的防守方法之一。在实践中,他们反复生成对抗性的训练示例。在[16]中,Goodfello等人通过FGSM生成了对抗性示例,而Madry等人[28]在对抗性训练中使用了投影梯度下降(PGD)攻击。近年来,许多基于对抗训练的变体被提出。例如,[36]同时计算了攻击的梯度和模型参数的梯度,显著减少了计算时间。对抗性罗格特配对[22]限制了清晰图像中的罗格特与其对抗性示例之间的距离,而[29]和[53]在清晰图像、其对应的对抗性示例与负面示例之间建立了三重损失。权衡[52]优化了稳健性和准确性之间的权衡。在[42]中,作者设计了一种带有对抗性图像和对抗性标签的对抗性训练策略。在[50]中,在潜在空间中使用特征散射来生成对抗性示例,并进一步提高了模型在不同攻击下的准确性。Xie等人[46]通过在体系结构中添加去噪块来防御攻击,提出了特征去噪模型。
现有的大多数基于对抗性训练的模型都集中在利用对抗性示例的训练模型上,这些示例可能已损坏,但尚未探索在干净图像上训练的模型中的信息。
其他对抗性防御模式:在[27,47]中,作者建议首先检测并拒绝对抗性示例。提出了几种使用生成模型估计干净图像的方法[37,38,48]。Cohen等人[7]提出使用随机平滑来提高对抗鲁棒性。还有几项工作利用大规模外部未标记数据来提高对抗鲁棒性,例如[5]和[40]。
在本文中,我们致力于在不使用外部数据或预处理测试数据的情况下提高模型本身的对抗鲁棒性。
三、提出方法
在本节中,我们将详细介绍我们提出的AGKD-BML模型的框架。如图2所示,AGKD-BML框架由两个模块组成,即注意引导知识提取(AGKD)模块和双向攻击度量学习(BML)模块。AGKD模块用于将干净图像的注意力知识提取到学生模型中,为对抗性示例获得更好的注意力图,以及纠正损坏的中间特征。BML模块通过双向度量学习有效地正则化特征空间中的表示。在本节的其余部分中,我们首先简要介绍了标准对抗训练(AT)和(非)目标对抗攻击,然后描述了我们提出的模型的两个模块以及它们的集成。
3.1前期准备
我们首先简要介绍了标准对抗训练(AT)[28]。假设我们有一个带标签的C类分类数据集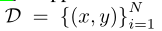 ,共N个样本,其中标签y∈ {1,2,…,C}。有两种类型的对抗性攻击,即非目标攻击和目标攻击,可分别表示为等式(1)和(2):
,共N个样本,其中标签y∈ {1,2,…,C}。有两种类型的对抗性攻击,即非目标攻击和目标攻击,可分别表示为等式(1)和(2):
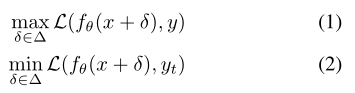
其中δ是图像x上的扰动,∆ 提供一个∞-扰动的范数界,fθ(·)和L(·)分别表示具有模型参数θ和损失函数的网络。非目标攻击在给定正确标签y的情况下使损失函数最大化,而目标攻击在给定目标标签y(t)的情况下使损失函数最小化。
标准AT在训练期间使用非目标PGD(投影梯度下降)攻击[28],这可以表示为一个最小-最大优化问题:
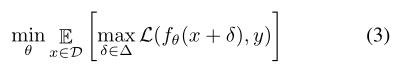
在目标函数中,外部最小化是模型参数的更新,而内部最大化是生成对抗性攻击。具体来说,PGD用于生成攻击,这是一种迭代的非目标攻击,从一开始就随机开始。在本文中,在[42]之后,我们在训练中使用目标攻击,将最容易混淆的类作为目标类。
3.2注意力引导的知识蒸馏
为了将干净图像的注意力信息提取到学生模型中,我们提出了一种注意力引导的知识蒸馏方法。
图1显示了一张干净的图像(“德国牧羊犬”)及其敌对的例子(“天文馆”)的注意力地图。作为与课程相关的注意力地图,Grad CAM[35]显示了与特定课程相关的聚焦区域。从图中我们可以看到,尽管对抗性示例降低了原始类的注意图,但它对目标(错误)类的注意图的伤害更大,并使错误类的特征压倒正确类,并在总体上占主导地位(因此使模型分类错误)。我们认为,仅提取与课堂相关的注意信息对纠正目标课堂特征的效果有限。因此,我们建议提取干净图像中与课堂无关的注意信息(见第3.2.1节)。我们在补充材料中提供了更多的解释和讨论来证明我们的选择。
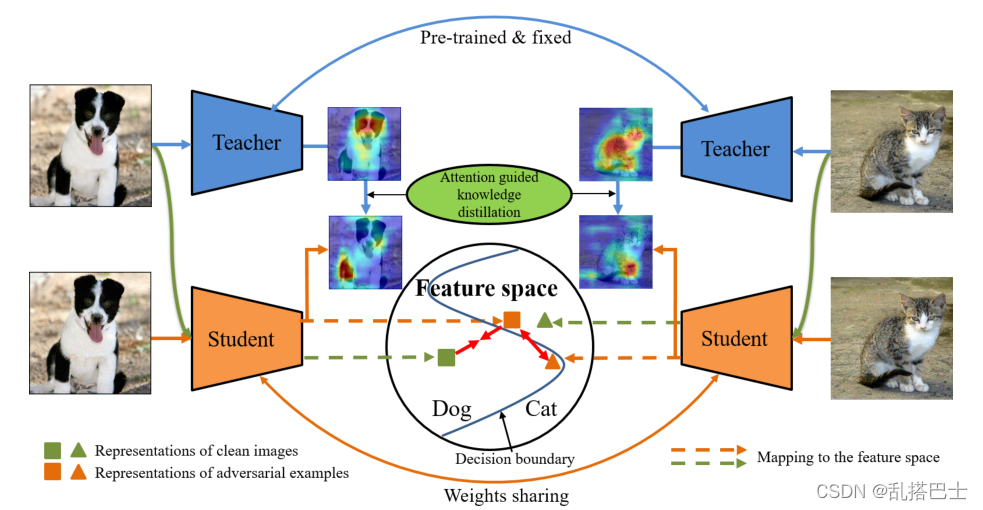
图2。提出了AGKD-BML模型的框架。左上角是一个干净的图像,属于“狗”,左下角是其对抗性示例(AE)针对其最令人困惑的类别“猫”的攻击。同样,右上角和右下角分别是“猫”和其AE目标“狗”的清晰图像。“教师”是在干净的形象上预先训练的模式,“学生”是在训练模式上训练的模式。AE将通过1)聚焦错误区域,2)跨越特征空间中的决策边界来愚弄模型。注意引导的知识提取,如绿色椭圆所示,用于校正焦点区域。双向度量学习(如“特征空间”中的红色箭头所示)用于将AEs拉回到其原始类。最好是彩色的。
3.2.1课堂无关的注意图
我们在最后一个卷积层生成类无关注意图。具体来说,我们将主干神经网络作为特征提取器处理,直到最后一个卷积层,对于给定的图像x,用F(x)表示,其中F(x)∈ R (C×H×W上标)。然后我们生成一个操作符,用A(·)表示,将特征映射到二维注意映射A(F(x))∈ R(1×H×W上标)。在本文中,我们将通过信道维度(或相同权重1×1卷积)的平均池模拟为A。
3.2.2知识蒸馏
知识蒸馏(KD)[18]利用学生-教师(S-T)学习框架将从教师模型学到的信息传递给学生模型。在本文中,我们将通过标准训练在自然清洁图像上训练的模型作为教师模型,将对抗训练下的模型作为学生模型。注意力信息是我们期望从教师模型转移到学生模型的信息。由于教师模型是在干净的图像上训练的,测试精度很高,因此它能够提供模型应该关注的正确区域。因此,由教师模型提取的干净图像的注意力图将转移到学生模型。这种注意力引导的知识提炼的损失函数写为:
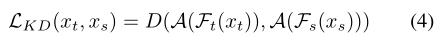
其中xt和xs分别是教师和学生模型的输入图像,Ft和Fs分别是教师和学生模型的特征提取器。D(·)是距离函数(例如,L1),用于测量这两个注意图之间的相似性。举一个对抗性的例子,AGKD引导学生模型关注与其清晰形象相同的区域。
3.3双向攻击度量学习
在我们的工作中,我们使用目标攻击来获取对抗性示例。让xs指的是标签为y=s的样本,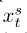 指的是目标标签为yt=t的xs的对抗性示例。在本文中,前向对抗性示例针对的是最容易混淆的类,定义如下:
指的是目标标签为yt=t的xs的对抗性示例。在本文中,前向对抗性示例针对的是最容易混淆的类,定义如下:
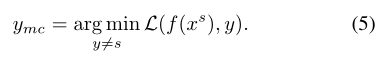
给定一个原始的干净图像xs,我们首先生成针对其最混乱类的目标对抗示例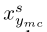 。然后,我们从最容易混淆的类别中随机选择一个样本xymc,并生成针对原始标签s的对抗性示例
。然后,我们从最容易混淆的类别中随机选择一个样本xymc,并生成针对原始标签s的对抗性示例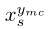 。我们分别使用
。我们分别使用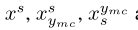 作为正、锚定和负样本。三重损失定义为:
作为正、锚定和负样本。三重损失定义为:
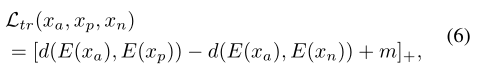
其中xa、xp、xn分别表示正样本、锚定样本和负样本。E(·)是模型倒数第二层的表示。d(a,b)表示两个嵌入件a和b之间的距离,其定义为角距离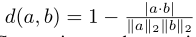 ,后面是[29]。m是边际。与以前的基于度量学习的对抗训练相比,例如,仅考虑正向对抗实例的〔29〕和〔53〕,我们考虑向前和向后对抗的例子。因此,我们将其命名为双向度量学习。
,后面是[29]。m是边际。与以前的基于度量学习的对抗训练相比,例如,仅考虑正向对抗实例的〔29〕和〔53〕,我们考虑向前和向后对抗的例子。因此,我们将其命名为双向度量学习。
通过在嵌入上添加“L2范数正则化”,最终的BML损失函数写为:
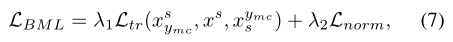
其中,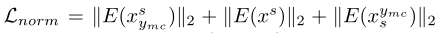 是归一化项,λ1和λ2是两种损失的权衡权重。
是归一化项,λ1和λ2是两种损失的权衡权重。
3.4两个模块的整合
我们将注意力引导的知识提取和双向度量学习结合在一起,从这两个模块中获益。当我们考虑双向对抗攻击时,我们有两个干净/敌对图像对,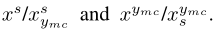 。对于这两对,我们将教师模型获得的干净图像的注意力图中的AGKD应用于学生模型,其公式如下:
。对于这两对,我们将教师模型获得的干净图像的注意力图中的AGKD应用于学生模型,其公式如下:
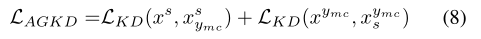
其中,第一项表示前向攻击对的AGKD损失,即xs和xsymc ,第二项表示反向攻击对,即xymc和xymcs。通过结合传统对抗训练中使用的标准交叉熵损失、BML损失和AGKD损失,最终总损失为:
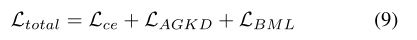
AGKD-BML模型的整体过程如算法1所示:

四、实验
4.1实验设置
数据集:我们在两个流行的数据集上评估了我们的方法:CIFAR-10和SVHN。CIF AR-10由60k三通道彩色图像组成,大小为32×32,分10类,其中50k图像用于训练,10k图像用于测试。SVHN是street view house number数据集,其中有73257张用于培训的图像和26032张用于测试的图像。我们在一个更大的数据集:微小的ImageNet上评估模型,结果显示在补充资料中。
比较方法:我们使用的比较方法包括:(1)未定义模型(UM),其中模型通过标准训练进行训练;(2) 对抗性训练(AT)[28],使用非目标PGD对抗性示例(AEs)进行训练;(3) 单向度量学习(SML)[29];(4) 双边[42],在图像和标签上生成AEs;(5) 特征散射(FS)[50],其中针对训练的对抗性攻击是通过潜在空间中的特征散射生成的;(6) (7)分别在TRADES[51]和MART[44]上使用渠道激活抑制(CAS)[3],与原始版本相比显示出优越性。请注意,双边、FS在训练中使用单步攻击生成AEs,而AGKD-BML使用2步攻击,“T”和“SML”使用7步攻击,“TRADES+CAS”和“MART+CAS”使用10步攻击。为了与这些多步攻击模型进行公平比较,我们还训练了AGKD-BML的7步攻击变体,称为“AGKDBML-7”。我们用不同的攻击迭代对模型进行了测试,包括FGSM[16]、BIM[24]、PGD[28]、CW[4]、MIM[12]。我们还使用自动攻击(AA)[10]以每个样本的方式评估模型,自动攻击是四种不同攻击的集合。最后,我们还测试了模型的黑盒对抗鲁棒性。
实施细节:在[28]和[29]之后,我们使用Wide-ResNet(WRN-28-10)[49],并将初始学习率γ设置为CIFAR-10的0.1和SVHN的0.01。我们使用与[42]和[50]相同的学习率衰减点,其中,CIFAR-10的衰减计划[100,150],SVHN的衰减计划[60,90],总共有200个epoch。按照[44,34]中的建议,“AGKD-BML-7”的学习速度在150个时期衰减,训练在155个时期停止。在训练阶段,扰动预算eposilo=8和标签平滑等于[50]之后的0.5。在AGKD模块中,我们采用L1范数来度量注意图之间的相似性。对于BML模块,参数与[29]相同,即边际m=0.03、λ1=2和λ2=0.001。
4.2对抗性的鲁棒性评估
…
4.3消融实验
见论文

















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









