






* * * The Machine Learning Noting Series * * *
目录
1 梯度提升算法原理
梯度提升算法的原理
梯度提升优化参数的过程
2 梯度提升回归树
3 梯度提升分类树
4 用python实现梯度提升算法

1 梯度提升算法原理
梯度提升树采用向前式分步可加建模方式,每次迭代仅需估计当前模型,而且每个模型进入“联合投票委员会”时不会影响之前的模型。在迭代过程中基于损失函数,采用梯度下降法,找到使损失函数下降最快的模型。
迭代过程中,每个新加入的模型(“联合投票委员会”)都是用于修正当前预测值的增量函数(incremental functions),会不断调整预测值,从而使得迭代预测值不断接近真实值。
梯度提升算法的原理
梯度下降法通常是用于估计复杂模型参数优化的一种优化方法。为了便于说明,假设有函数 f(w)=w²+1,现需要求解 f(w) 取最小值时的 w 的值。此简单函数可以直接求导求解,而当函数较为复杂时,采用的梯度下降法,计算 f(w) 在w处的导数并不断更新来求解,具体为:
① 取初始值w(0)=4, 计算 f(w) 在w=4时的导数:f'(w=4)=8>0. 此处 f 递增,因此只有减小w取值才能得到更小的f(也就是说,f' 的符号决定了对w的更新方向)。
② 确定了w更新方向之后,需进一步确定更新的步伐Δw,这样便可得到一个更新的w:
其中,ρ称为学习率,显然若f'越接近0(即越接近最低点),则w每次更新的幅度就会越小。随着w的不断更新,f逐渐逼近曲线的最小值,最终为最优解,这就是梯度下降法的优化过程。
梯度提升优化参数的过程
设为第b次迭代的预测结果,
为基础学习器(“联合投票委员会”中的模型成员),
为基础学习器的参数集合,系数
决定基础学习器对预测结果的实际影响大小,因此,一个梯度下降优化过程为:
按照梯度下降的思路,取决于损失函数
在
处的负梯度(一阶导数)和学习率ρ(假设对每个样本Xi的倒数是已知的):
尽管当前模型h的参数和
是未知的,但可参照最小二乘法求解在
和
离差平方和最小下时参数:
若,则
。一般称
为伪响应变量(pseudo response)。
此外,学习率可通过线搜索(line research)获得:
因此,梯度提升算法的一般步骤为:
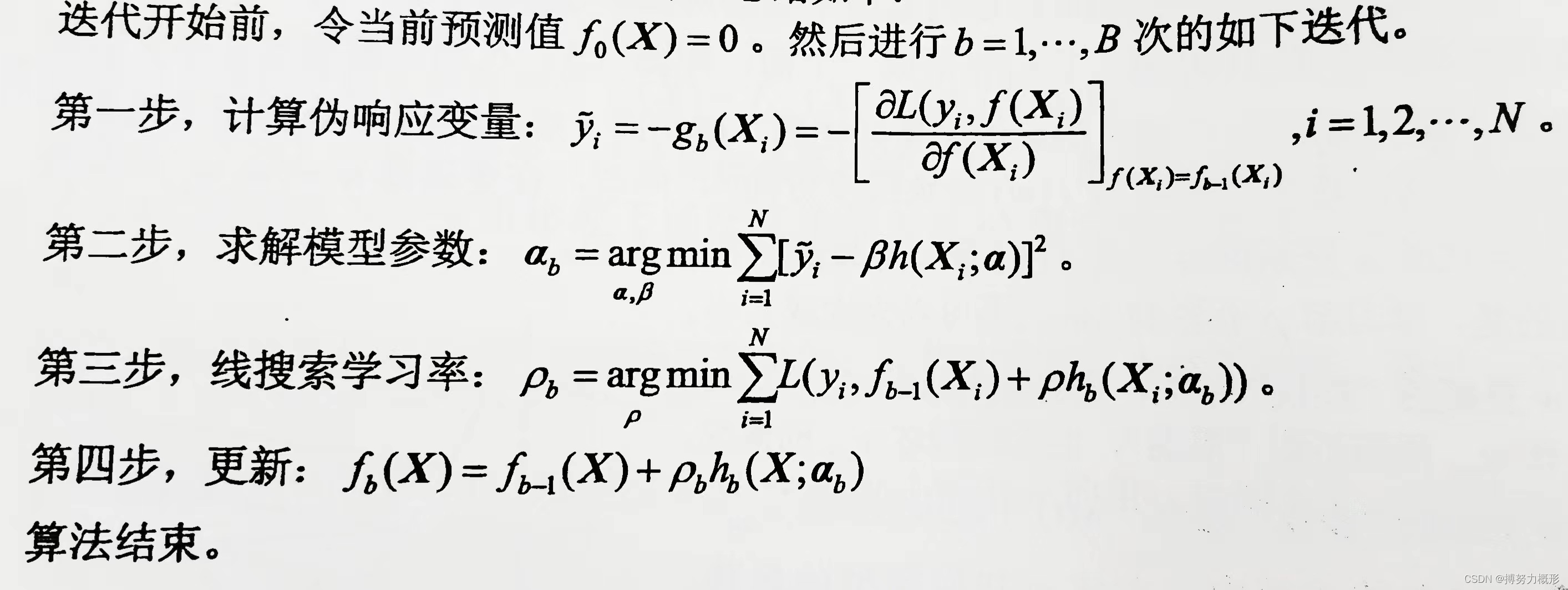
2 梯度提升回归树
梯度提升回归树用于回归预测:
① 损失函数定义为平方损失: ,于是伪响应变量就是当前残差
;
② 基于损失函数的定义,上述梯度提升法的三步中的ρ即为β。

3 梯度提升分类树
梯度提升分类树用于分类预测,这里讨论输出变量为-1和1时的二分类情况。
① 损失函数定义为:,此损失函数为负二项对数似然(Negative Binomial Log-Likelihood)损失,其中
,于是,伪响应变量为
;
②学习率通过线搜索获得:

4 用python实现梯度提升算法
进行梯度提升树和AdaBoost预测的对比。
#本章需导入的模块
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action = 'ignore')
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn import tree
import sklearn.linear_model as LM
from sklearn import ensemble
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.metrics import zero_one_loss,r2_score,mean_squared_error,accuracy_score
import xgboost as xgbN=1000
X,Y=make_regression(n_samples=N,n_features=10,random_state=123)
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.70, random_state=123)
B=300
dt_stump = tree.DecisionTreeRegressor(max_depth=1, min_samples_leaf=1)
TrainErrAdaB=np.zeros((B,))
TestErrAdaB=np.zeros((B,))
adaBoost = ensemble.AdaBoostRegressor(base_estimator=dt_stump,n_estimators=B,loss= 'square',random_state=123)
adaBoost.fit(X_train,Y_train)
for b,Y_pred in enumerate(adaBoost.staged_predict(X_train)):
TrainErrAdaB[b]=1-r2_score(Y_train,Y_pred)
for b,Y_pred in enumerate(adaBoost.staged_predict(X_test)):
TestErrAdaB[b]=1-r2_score(Y_test,Y_pred)
GBRT=ensemble.GradientBoostingRegressor(loss='ls',n_estimators=B,max_depth=1,min_samples_leaf=1,random_state=123)
GBRT.fit(X_train,Y_train)
TrainErrGBRT=np.zeros((B,))
TestErrGBRT=np.zeros((B,))
for b,Y_pred in enumerate(GBRT.staged_predict(X_train)):
TrainErrGBRT[b]=1-r2_score(Y_train,Y_pred)
for b,Y_pred in enumerate(GBRT.staged_predict(X_test)):
TestErrGBRT[b]=1-r2_score(Y_test,Y_pred)
GBRT0=ensemble.GradientBoostingRegressor(loss='ls',n_estimators=B,max_depth=3,min_samples_leaf=1,random_state=123)
GBRT0.fit(X_train,Y_train)
TrainErrGBRT0=np.zeros((B,))
TestErrGBRT0=np.zeros((B,))
for b,Y_pred in enumerate(GBRT0.staged_predict(X_train)):
TrainErrGBRT0[b]=1-r2_score(Y_train,Y_pred)
for b,Y_pred in enumerate(GBRT0.staged_predict(X_test)):
TestErrGBRT0[b]=1-r2_score(Y_test,Y_pred)
plt.plot(np.arange(B),TrainErrAdaB,linestyle='--',label="AdaBoost回归树(训练)",linewidth=0.8)
plt.plot(np.arange(B),TestErrAdaB,linestyle='--',label="AdaBoost回归树(测试)",linewidth=2)
plt.plot(np.arange(B),TrainErrGBRT,linestyle='-',label="梯度提升回归树(训练)",linewidth=0.8)
plt.plot(np.arange(B),TestErrGBRT,linestyle='-',label="梯度提升回归树(测试)",linewidth=2)
plt.plot(np.arange(B),TrainErrGBRT0,linestyle='-.',label="复杂梯度提升回归树(训练)",linewidth=0.8)
plt.plot(np.arange(B),TestErrGBRT0,linestyle='-.',label="复杂梯度提升回归树(测试)",linewidth=2)
plt.title("梯度提升回归树和AdaBoost回归树")
plt.xlabel("弱模型个数")
plt.ylabel("误差")
plt.legend()
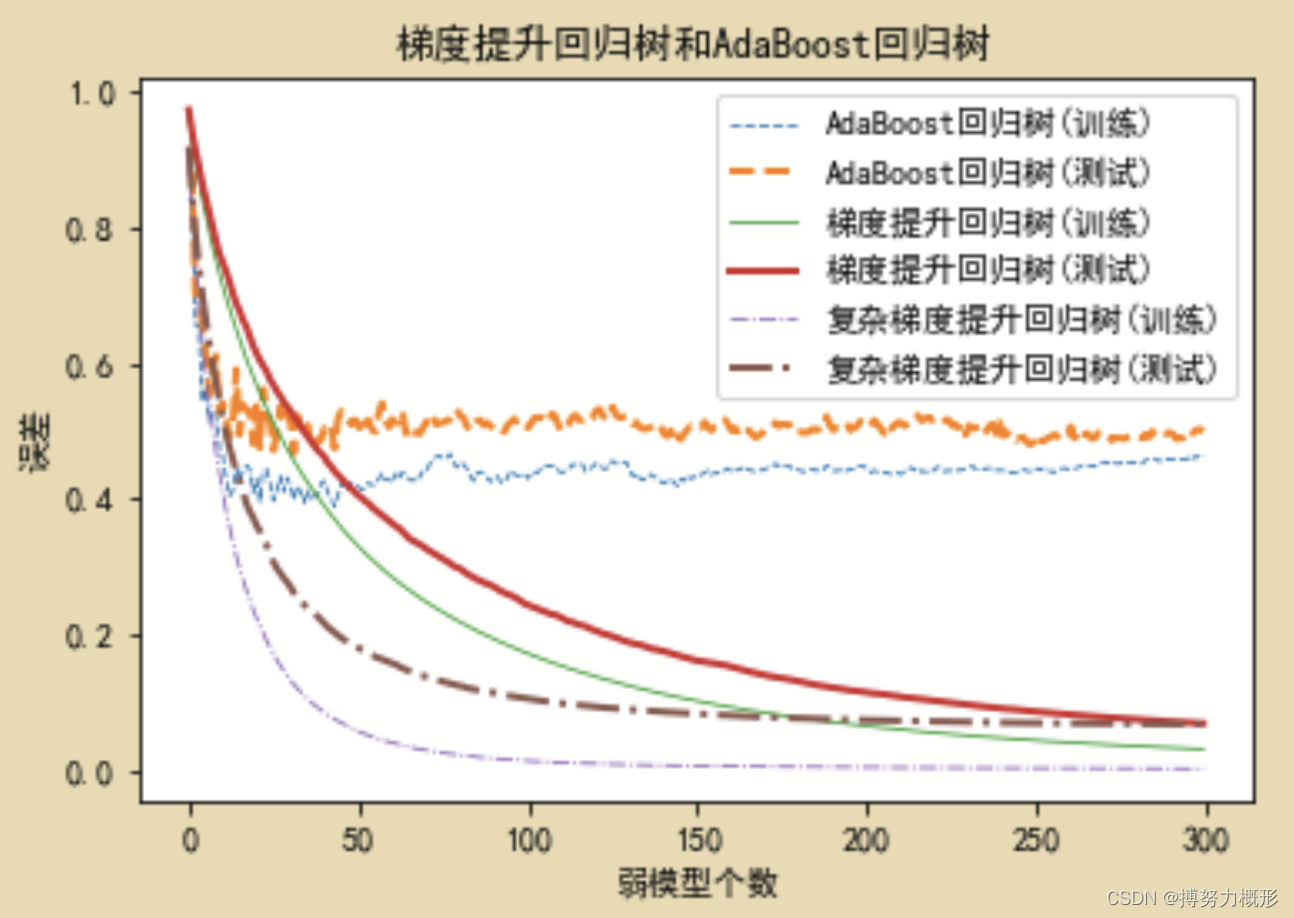
可见,在此例模拟中,梯度提升树效果好于其他集成算法,因为它具有更低的误差。
参考文献
《Python机器学习 数据建模与分析》,薛薇 等/著















 1791
1791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









