







小罗碎碎念
小罗日报|24-06-01
首先祝大家儿童节快乐,希望大朋友们的内心深处仍然能保留一颗童心!!(毕竟小朋友也不会看我的推文,哈哈)

今天的推文主题是——如何解决医学数据中的样本类别不平衡问题。大家在整理自己的内部数据集时,或多或少都遇到过这个问题,所以今天小罗就把23年12月到24年5月发表的顶刊做了一个汇总,把其中涉及到样本类别不平衡的文章挑选出来和大家分享一下。
交流群
欢迎大家来到【医学AI】交流群,本群设立的初衷是提供交流平台,方便大家后续课题合作。

一、深度学习检测大型不平衡数据库中的MRI图像伪影

文献概述
这篇文章是关于使用深度学习技术来检测大型
不平衡数据库中的MRI图像伪影的研究。
文章首先介绍了MRI在诊断和研究神经系统疾病中的重要性,以及图像伪影如何影响MRI的实用性。传统的质量评估依赖于耗时且主观的视觉检查,因此自动化检测方法的需求日益增长。
研究者提出了一种基于深度学习(DL)的算法,特别是利用了3D AlexNet网络结构,结合蒙特卡洛(MC)dropout技术来生成概率和不确定性估计,以改进对伪影的检测。
研究分为三个阶段:
-
概念验证(Stage I):使用小型数据集验证深度学习算法检测伪影的可行性,实现了100%的准确率。
-
算法改进(Stage II):创建了一个平衡的数据集(50%干净图像),引入了循环学习率和MC dropout来提高性能,并实现了91.0%的准确率。
-
知识迁移(Stage III):通过
数据扩展(data-ramping)技术,将学习应用于一个更大规模(34,800个扫描,98%干净图像)和不平衡的数据集,最终实现了99.5%的测试准确率。
文章还讨论了如何处理类别不平衡问题,通过数据扩展和转移学习来提高算法的泛化能力。此外,研究者还首次在MRI伪影检测中引入了不确定性度量,这有助于在临床研究中提供预测的置信度。
最后,研究者指出他们的DL算法在大型不平衡的神经影像数据库中检测伪影方面,性能优于以往的自动化方法,并且已经成功集成到了处理流程中。这项工作得到了加拿大Mitacs Elevate资助和魁北克健康研究基金的支持。
重点关注
Fig. 1展示了数据库中最常见的三种伪影实例。
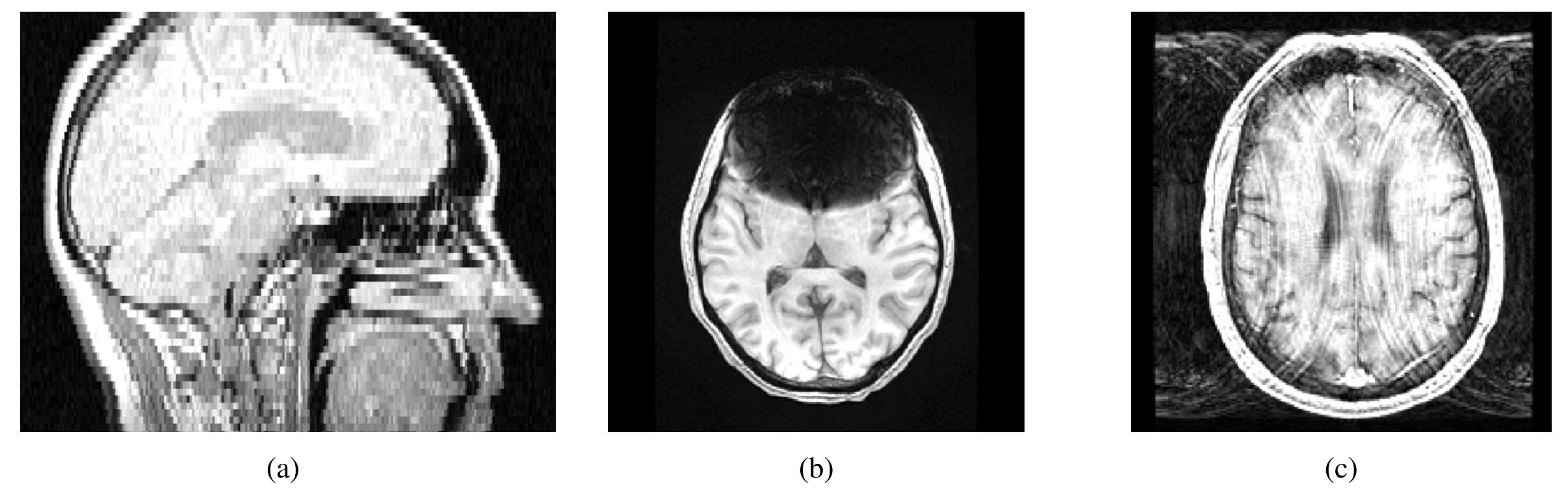
下面是对这三种伪影的分析:
-
覆盖伪影(Coverage Artifact):
- 原因:由于视场(Field of View, FOV)放置不当导致。
- 表现:通常会导致包裹效应(wrap around),即图像的一侧信息错误地显示在另一侧,这可能会误导对图像的解读。
- 影响:覆盖伪影可能会影响图像分析的准确性,尤其是在进行形态学研究时,错误的图像覆盖会导致对脑组织体积或形状的错误测量。
-
强度伪影(Intensity Artifact):
- 原因:由金属植入物引起的磁敏感性问题。
- 表现:在金属植入物附近产生异常的信号强度,这可能会导致图像的某些区域出现过度亮或暗的区域。
- 影响:强度伪影可能会干扰对脑部病变的检测和分析,因为它们可能会被误认为是病理变化,或者掩盖真实的病变。
-
运动伪影(Motion Artifact):
- 原因:由于头部运动引起。
- 表现:包括吉布斯环(Gibbs ringing),这是一种在快速变化的信号(如头部运动产生的信号)附近出现的振荡或“振铃”效应。
- 影响:运动伪影可能会导致图像模糊,影响对脑部结构细节的观察,进而影响诊断的准确性。
这些伪影的存在强调了在进行MRI图像分析之前,进行质量控制和伪影检测的重要性。自动化的伪影检测方法,如本文提出的深度学习方法,可以帮助提高MRI图像分析的效率和准确性,从而为临床研究和诊断提供更可靠的数据。
二、QP-Net|提高模型在弱势子群体中的性能

文献概述
文章主要讨论了在医疗诊断中应用人工智能(AI)模型时所面临的普适性和公平性挑战。
研究者们指出,在大型甲状腺超声数据集中,不同子群体之间的诊断性能存在显著差异,这种差异与样本大小不平衡有因果关系。
为了解决这一问题,文章引入了一种称为准帕累托改进(Quasi-Pareto Improvement, QPI)的方法和一种深度学习实现(QP-Net),结合了多任务学习和领域适应,以提高模型在弱势子群体中的性能,同时不损害整体人群的性能。
在甲状腺超声数据集上,QPI方法显著减少了三个较少见子群体的AUC(曲线下面积)差异,分别为0.213、0.112和0.173,同时保持了主导子群体的AUC。此外,研究者还在两个公共数据集上进一步证实了这种方法的普适性:ISIC2019皮肤疾病数据集和CheXpert胸部X光数据集。研究表明,QPI方法在促进AI实现公平医疗结果方面具有广泛的适用性。
文章还讨论了AI作为临床诊断工具在多种疾病中取得的实质性进展,并指出了以往研究通常只关注整体人群或流行疾病亚型的结果,而忽视了罕见或特定的子群体。例如,在肺癌研究中,典型的深度学习研究可能只将肺癌分为主要的LUAD和LUSC亚型以及正常肺组织,而忽视了罕见亚型的识别。这种疏忽也体现在乳腺癌的超声图像诊断中,导致假阴性率高和漏诊。
文章还介绍了QP-Net的实现细节,包括多任务学习模块和领域适应模块的结构和功能。通过最小化类标签(良性-恶性)和子群体(主导子群体-较少见子群体)预测器自身的损失,同时尝试学习一个特征提取器,生成子群体不变的特征。
此外,文章还探讨了如何使用中心核对齐(Centered Kernel Alignment, CKA)方法来量化网络特征在迁移学习前后的相似性,并评估了QPI方法在CheXpert和ISIC2019数据集上的性能。
最后,文章讨论了QPI方法的优势和局限性,并提出了未来研究的方向,包括在更广泛的疾病范围中验证该方法,以及在更复杂的现实世界场景中进一步调查潜在的机制。文章强调了医学AI的公平性是一个高度复杂的问题,对其背后的机制和后果的理解仍处于初级阶段,并呼吁不同专家和利益相关者通过深入讨论来帮助更深入地理解医学中的AI应用,并制定适当的研究标准和公共政策。
重点关注
Fig. 1 展示了处理较少见亚群(less-prevalent subgroups)的三种不同方法:
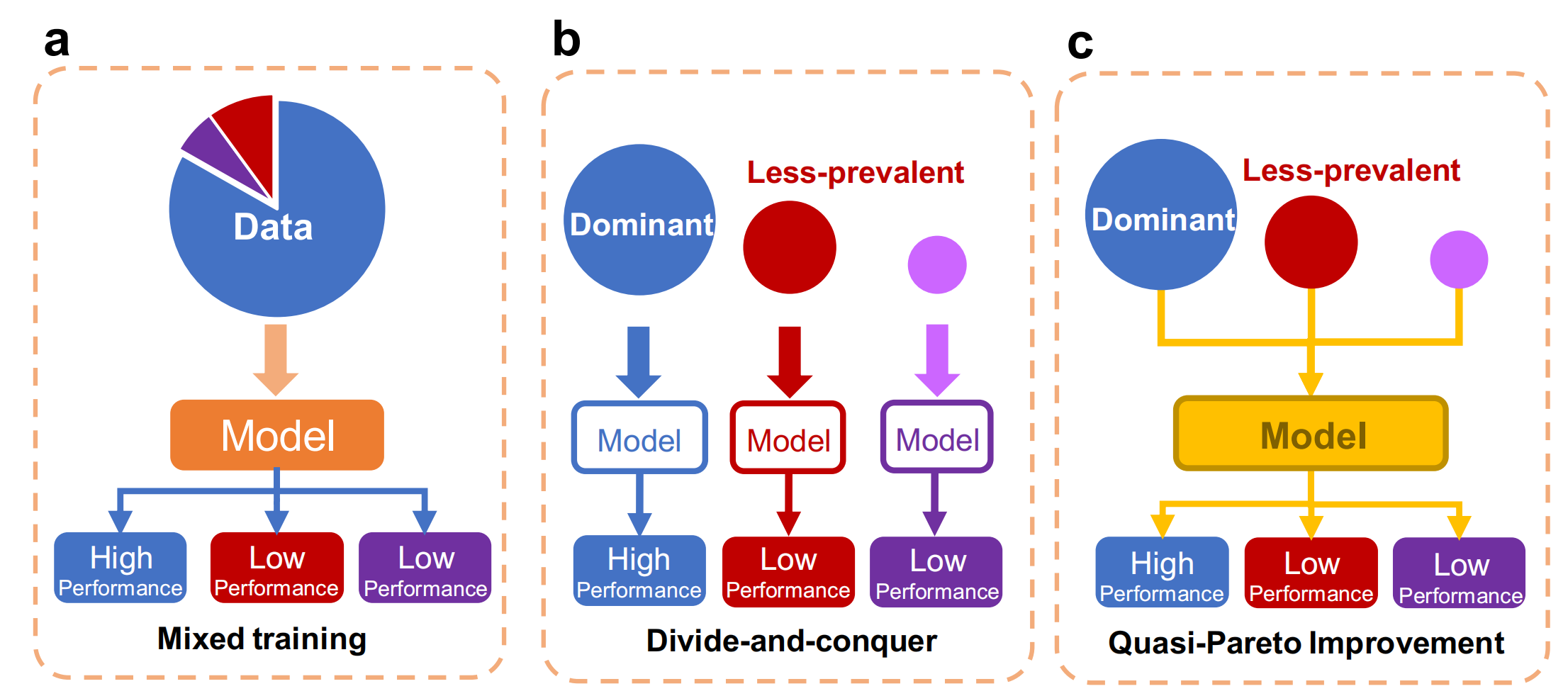
a. 混合训练(Mixed training):这种方法涉及使用来自多个亚群的混合数据进行训练。其目标是训练一个能够在所有亚群上表现良好的AI模型。混合训练的潜在风险是模型可能会忽视较少见亚群的特征,因为这些特征在整体数据中所占比例较小。
b. 分而治之(Divide-and-conquer):与混合训练不同,分而治之方法将不同亚群的数据作为独立的训练集,并分别为每个亚群训练模型。这种方法可以确保每个亚群都有足够的机会学习其特定特征。然而,较少见的亚群通常样本量不足,可能无法支持AI模型的训练,导致性能不佳。
c. 准帕累托改进(Quasi-Pareto Improvement, QPI)方法:QPI方法旨在改善不平衡亚群的预测性能,同时保持模型在整体人群上的预测性能。这是通过结合多任务学习和领域适应技术来实现的。QPI方法试图在不损害主导亚群性能的前提下,提升较少见亚群的性能,从而实现更公平的模型预测。
在Fig. 1中,每种方法旁边都有一个模型和数据的图示,表示不同方法对模型训练和预测性能的影响。混合训练可能导致较少见亚群的性能较低,因为它可能会被主导亚群的特征所淹没。分而治之可能在较少见亚群上表现更好,但由于样本量不足,可能仍然存在性能限制。而QPI方法则旨在提升所有亚群的性能,特别是通过改善较少见亚群的特征学习,同时保持对主导亚群的高性能。
总结来说,Fig. 1强调了在AI模型开发中处理不同亚群的重要性,并提出了QPI作为一种创新方法,以提高模型在所有亚群上的公平性和准确性。
三、标签数据的稀缺?FocAL方法重塑病理图像分类!

文献概述
这篇文章是关于一种新的主动学习方法(Focused Active Learning, FocAL),它专门针对病理图像分类任务。该方法由Arne Schmidt等人提出,旨在解决数字病理学中的一个主要问题:为机器学习算法有效地获取标记数据。
背景:
- 主动学习(Active Learning, AL)是机器学习方法的一种,它通过主动查询最有价值的标签来提高学习效率。
- 在医疗领域,获取精确的不确定性估计是一个挑战,因为现有方法在现实环境中常常难以处理
伪影、模糊性和类别不平衡问题。
FocAL方法:
- 结合了
贝叶斯神经网络(Bayesian Neural Network, BNN)和离群值检测(Out-of-Distribution, OoD)来估计不同的不确定性,以改进获取函数。 - 通过加权认识不确定性(epistemic uncertainty)来考虑
类别不平衡,用随机不确定性(aleatoric uncertainty)处理模糊图像,以及使用OoD分数来识别伪影。 - 在
MNIST数据集和现实世界的Panda数据集上进行了广泛的实验,以验证所提方法的有效性。
实验结果:
- 证实了其他AL方法容易被模糊性和伪影“分心”,从而损害性能。
- FocAL专注于获取最具信息价值的图像,在获取过程中避免模糊性和伪影。
- 在两个实验中,FocAL都优于现有的AL方法,特别是在仅有0.69%标记的Panda数据时,达到了0.764的Cohen’s kappa系数。
结论与未来工作:
- FocAL通过精确的不确定性估计成功解决了医疗图像中的类别不平衡、模糊性和伪影问题,从而提高了性能。
- 未来的工作可能包括将FocAL与其他学习方法结合,以及在其他类型的医学图像上应用和评估FocAL方法。
这篇文章为数字病理学中的图像分类问题提供了一种新的视角,通过结合贝叶斯方法和离群值检测,提高了学习效率并解决了一些关键问题。
重点关注
Fig. 1 展示了所提出的 Focused Active Learning (FocAL) 方法的模型概览。
该模型由三个主要部分组成:特征提取器(feature extractor)、贝叶斯神经网络(Bayesian Neural Network, BNN)、以及离群值检测(Out-of-Distribution detection, OoD detection),这三个部分在图中用蓝色框表示。
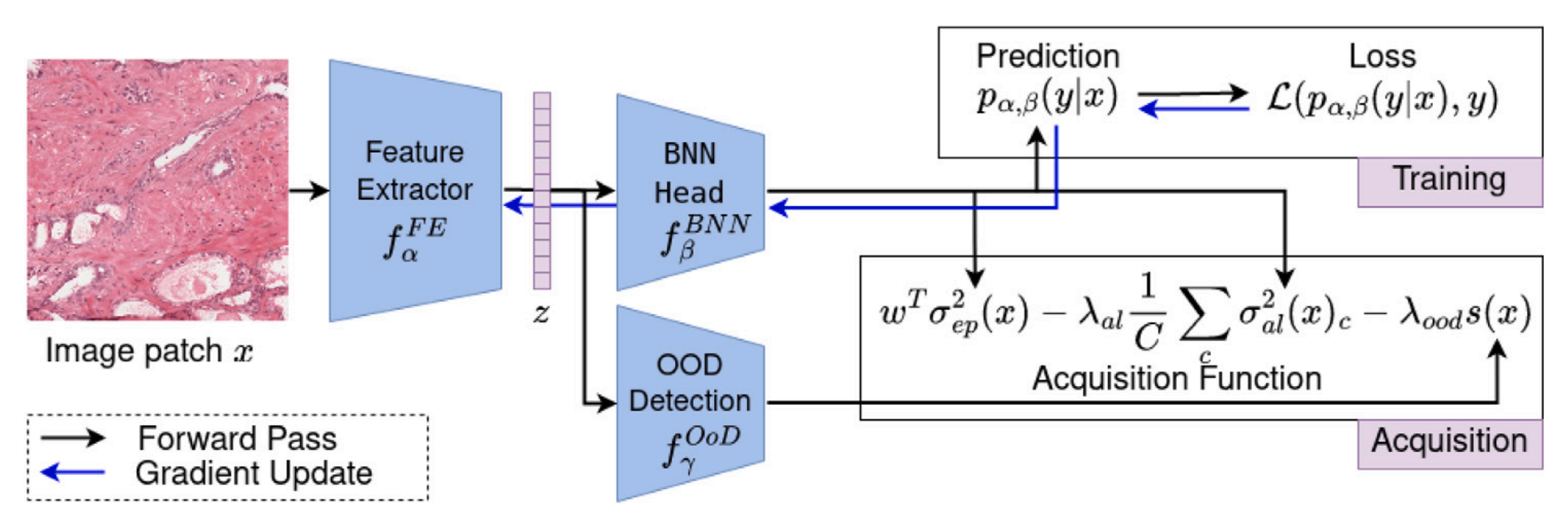
各组件的功能如下:
-
特征提取器 (Feature Extractor):
- 负责从图像中提取高级特征。
- 通常使用卷积神经网络(CNN)来实现。
- 这些特征随后被用于BNN和OoD检测。
-
贝叶斯神经网络 (BNN):
- 用于基于提取的特征进行概率推理。
- BNN不仅能够进行准确的分类预测,还能够估计认识不确定性(epistemic uncertainty)和随机不确定性(aleatoric uncertainty)。
- 认识不确定性与模型参数的不确定性有关,可以通过更多标记训练数据来减少。
- 随机不确定性描述了数据中固有的、无法通过更多标记数据减少的不确定性。
-
离群值检测 (OoD Detection):
- 用于检测和避免获取包含伪影的图像。
- 伪影可能包括笔标记、组织褶皱、血液或墨水等,这些都是在现实世界数据中不可避免的。
- OoD检测通过给每个未标记图像的特征向量分配一个局部异常因子(LOF)得分来实现。
组件如何结合用于训练和获取:
-
训练过程:
- 初始阶段,使用一小部分标记数据训练特征提取器和BNN。
- 随着主动学习过程的进行,模型在每个迭代步骤中通过获取函数选择未标记图像的子集进行标记。
-
获取过程:
- BNN提供关于每个未标记图像的认识和随机不确定性估计。
- OoD检测为每个未标记图像分配一个得分,以评估其是否为离群值。
- 综合这些信息,获取函数评估每个图像的信息量,并选择得分最高的图像进行标记。
-
迭代优化:
- 每次迭代后,将新标记的图像添加到训练集中,并从未标记数据池中移除。
- 然后,使用更新的训练集重新训练模型,以此迭代过程逐步提高模型性能。
Fig. 1 通过可视化的方式展示了这三个组件是如何相互作用,以及它们是如何共同支持FocAL方法在病理图像分类中的主动学习过程。通过这种方法,FocAL能够有效地专注于获取最具信息量的图像,同时避免获取那些带有伪影或模糊不清的图像,从而提高学习效率和模型性能。
四、告别海量数据标注:AI单标签学习在肿瘤学的进展

文献概述
这篇文章是关于人工智能(AI)在肿瘤组织病理学中的增强应用的综述。
文章的核心观点是,AI增强的组织病理学为肿瘤学带来了前所未有的机遇,它通过可解释的方法,仅需每个苏木精-伊红(H&E)染色玻片一个总体标签,无需组织级别的注释。文章系统回顾了这些方法,并根据它们的可验证度和在肿瘤学表征中常见的应用领域进行了分类。
文章首先讨论了形态学标记(如肿瘤存在/不存在、转移、亚型、分级),AI识别的感兴趣区域(ROIs)与病理学家识别的ROIs可验证地重叠。其次,讨论了分子标记(如基因表达、分子亚型),这些标记不是通过H&E染色来验证的,而是基于与相邻组织上阳性区域的重叠。第三,讨论了遗传标记(如突变、突变负担、微卫星不稳定性、染色体不稳定性),当前技术无法验证AI方法在空间上解析特定遗传变异的能力。第四,讨论了直接预测生存期,AI识别的组织病理学特征与生存期定量相关,但尚不能机械地验证。
文章还详细讨论了这些单标签每张幻灯片方法在肿瘤学中的机遇和挑战。
机遇:
- 降低研究和临床护理的成本
- 减少临床医生的工作量
- 个性化医疗
- 通过新的基于成像的生物标记物来充分挖掘组织病理学的潜力
目前的挑战
- 可解释性
- 通过相邻组织切片进行验证
- 可重复性
- 数据可用性
- 计算需求
- 数据需求
- 领域适应性
- 外部验证
- 数据集不平衡
- 商业化
- 临床潜力
文章强调,
WS-MIL(弱监督多实例学习)方法的采用将在计算病理学和肿瘤学的临床需求中发挥变革性作用。
通过利用这些高级方法,病理数据的分析和解释将变得容易获取,有助于病理学家和肿瘤学家之间的专业知识无缝整合。
WS-MIL将使病理数据得到有效处理,并可用于快速分析和解释,从而使肿瘤学家能够利用WS-MIL驱动分析提供的丰富见解来做出决策。病理学家在识别和表征癌组织方面的专业知识将通过WS-MIL识别微妙模式和异常的能力得到加强,从而丰富诊断过程。配备有全面病理信息和AI生成的见解的肿瘤学家将更好地装备起来,为每个患者的特定需求量身定制准确的治疗决策。
最后,文章总结了WS-MIL在肿瘤组织病理学中的应用,并展望了这一领域未来的发展前景。作者认为,随着相关数据的容易获取以及大量可用的AI方法用于结果驱动的分析,将克服当前的限制,并实现与AI驱动的组织病理学相关的无数机遇,造福于肿瘤学领域。
重点关注
Fig. 1 展示了多实例学习(MIL)和弱标注的概念。
在MIL中,数据被组织成“包”(bag),每个包包含多个“实例”(instance)。弱标注意味着每个包只有一个标签,而不是每个实例都有一个标签。
图的上半部分展示了正常组织切片图像(WSIs),这些图像只包含正常实例(用绿色图像块表示)。在这种情况下,我们假设从该WSI派生的每个实例隐含地都是正常的。因此,生成的包由正常实例组成,并被弱标注为“正常”用于MIL。
图的下半部分展示了肿瘤组织切片图像,这些图像包含肿瘤实例(用红色图像块表示)和正常实例。在这种情况下,我们假设一些实例隐含地是肿瘤,而另一些实例隐含地是正常的。因此,生成的包包含肿瘤和正常实例,并被弱标注为“肿瘤”用于MIL。
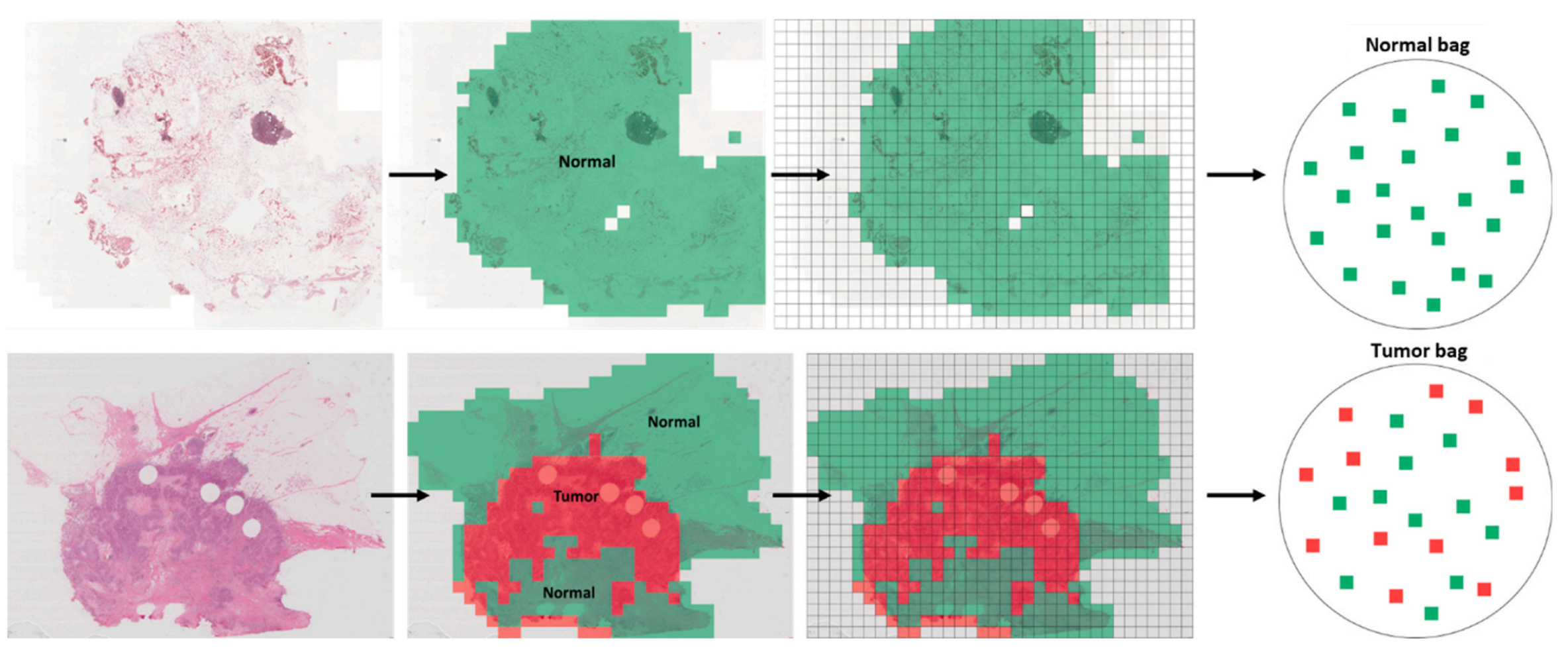
图中的绿色和红色注释仅用于说明目的,MIL框架无法访问这些注释。这意味着MIL算法必须在没有任何具体实例级别标注的情况下,通过整体的包标签来学习识别和区分肿瘤和正常组织。
分析这个图,我们可以得出以下几点:
-
弱标注的优势:通过弱标注,可以减少对每个实例进行详细标注的工作量,这在组织病理学图像分析中尤其有用,因为病理学家通常缺乏时间进行大量的像素级标注。
-
MIL的工作原理:MIL算法通过分析整个包的内容来推断包的标签。在肿瘤检测的上下文中,算法需要学会区分包含肿瘤的实例和不包含肿瘤的实例。
-
实例的隐含标签:在正常WSI中,所有实例都被认为是正常的;而在肿瘤WSI中,实例可能是正常的也可能是肿瘤的,这增加了MIL算法学习任务的复杂性。
-
可视化辅助:虽然注释用于帮助理解,但在实际的MIL框架中,算法需要独立地从数据中学习模式,而没有直接访问这些可视化辅助。
-
应用前景:这种弱监督学习方法为开发能够处理大规模组织病理学图像的AI系统提供了一种有效的途径,有助于在资源有限的情况下提高病理诊断的效率和准确性。
五、病理科医生的新盟友:SynCLay框架|自定义细胞布局生成高质量组织学图像

文献概述
这篇文章是关于一种名为
SynCLay(Synthesis from Cellular Layouts)的新型框架,它能够根据用户定义的细胞布局生成逼真且高质量的组织学图像。
该框架在计算病理学领域具有潜在应用,特别是对于自动化合成组织学图像的研究。SynCLay框架能够根据用户定义的细胞布局生成具有注释的细胞边界的组织学图像,允许用户生成不同的组织学模式,通过任意拓扑排列不同类型的细胞(例如中性粒细胞、淋巴细胞、上皮细胞等)。
SynCLay框架的主要贡献包括:
- 提出了一个交互式框架,可以根据定制的细胞布局生成组织图像,并允许用户通过控制细胞布局来生成自定义的组织图像。
- 该方法可以根据用户定义的参数(如癌症分化程度和不同类型细胞的细胞密度)生成逼真的合成组织学图像及其相关的细胞计数。
- 框架中整合了一个基于
核分割模型(HoVerNet)的核形态损失函数,以提高生成的核质量,并且能够同时生成核分割掩模。 - 通过训练病理学家的帮助,评估了合成图像的真实性,并证明了生成的图像质量与真实图像相当。
- 强调了使用合成生成的结直肠组织学图像数据对下游细胞组成预测和核存在检测任务的益处。
此外,SynCLay框架还接受了对抗性训练,并在训练过程中整合了一个核分割和分类模型,以细化核结构并生成与合成图像一起的核掩模。
在推理过程中,将该模型与另一个参数模型结合,用于生成结直肠图像及其相关的细胞计数作为注释,给定分化等级和不同细胞的细胞密度。通过Frechet Inception Distance对生成的图像进行了定量评估,并且训练病理学家对框架生成的一组图像进行了真实性评分反馈。所有病理学家对合成图像的平均真实性评分与真实图像一样高。
通过病理学家的帮助,展示了生成的图像准确区分良性和恶性肿瘤的能力,从而加强了它们的可靠性。展示了所提出的框架可以用于向组织图像中添加新细胞并改变细胞位置的能力。此外,展示了通过我们的框架生成的合成数据增强有限的真实数据可以显著提高细胞组成预测任务的预测性能。
文章还讨论了SynCLay框架的潜在应用,包括扩展现有的组织学图像分析分割数据集,以及将该框架推广到生成完整幻灯片图像的可能性。
重点关注
Fig. 3 展示了从 CoNiC 数据集中生成的图像样本以及细胞核分割掩模。在细胞布局的最顶行中,不同类型的细胞以不同的颜色显示位置。
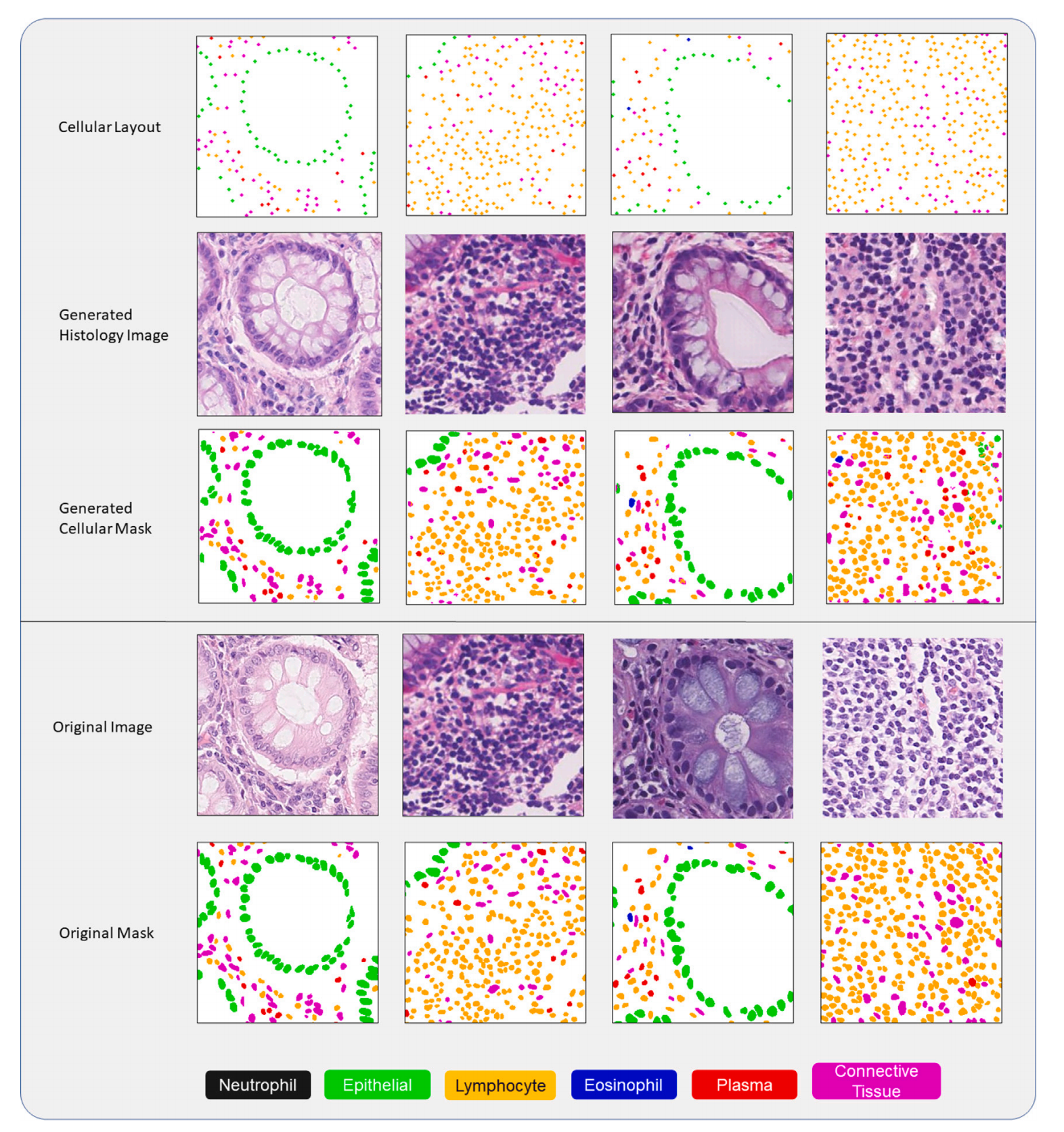
分析这个图表时,我们可以注意到以下几点:
-
细胞类型的可视化:图中最顶行展示了不同类型细胞的布局,每种类型的细胞都用不同的颜色来表示,这有助于用户快速识别和区分不同类型的细胞。
-
细胞核分割掩模:在生成的图像中,细胞核被准确地分割出来,并且每个细胞核的边界都被清晰地标记。这表明 SynCLay 框架在核分割方面表现出色,能够为每个细胞生成精确的掩模。
-
图像质量:生成的图像在视觉上与真实的组织学图像非常相似,保持了组织结构的细节,如腺体的形状、细胞的形态特征等。
-
真实感:图中展示的合成图像具有很高的真实感,这可以从细胞的分布和组织结构的自然外观中看出。
-
应用潜力:通过展示不同细胞类型的精确布局和分割,图表强调了 SynCLay 框架在计算病理学中的潜在应用,如算法开发、教育、临床质量保证等。
-
定制化能力:由于 SynCLay 允许用户定义细胞布局,这意味着可以生成具有特定细胞类型和分布的定制图像,这对于研究特定病理条件或进行教育演示非常有用。
-
对比与评估:通过将生成的图像与真实图像进行比较,可以评估 SynCLay 生成图像的质量,这对于进一步改进模型和验证其在实际应用中的有效性至关重要。
综上所述,Fig. 3 有效地展示了 SynCLay 框架在生成高质量、逼真的组织学图像方面的先进能力,并通过视觉化的方式突出了其在细胞分割和图像合成方面的准确性和应用潜力。
六、智能标签:自监督学习在单细胞数据注释方面的进展

文献概述
这篇文章标题为《The impacts of active and self-supervised learning on efficient annotation of single-cell expression data》,作者为Michael J. Geuenich、Dae-won Gong和Kieran R. Campbell。
文章的核心内容是探讨主动学习和自监督学习方法在单细胞表达数据高效注释上的影响。
在单细胞数据分析中,将细胞注释到特定类型和状态是一个关键步骤。尽管已经提出了多种方法,但手动标记细胞以创建训练数据集仍然是繁琐和耗时的。在机器学习领域,主动学习和自监督学习方法已被提出,旨在在减少注释时间和标签预算的同时提高分类器的性能。然而,这些策略在现实环境中对单细胞注释的好处尚未得到评估。
本研究对不同的单细胞技术和细胞类型注释算法进行了主动学习和自监督标记策略的全面基准测试。研究量化了在细胞类型不平衡和相似性变化的情况下,主动学习和自监督策略的好处。
文章介绍了一种适应性重新加权的启发式程序,这是为单细胞数据量身定制的,包括一个标记意识版本,其表现与现有方法具有竞争力。此外,研究表明,拥有关于细胞类型标记的先验知识可以提高注释的准确性。最后,文章将发现总结为一系列建议,供那些正在实施细胞类型注释程序或平台的人参考。
研究使用了多种单细胞表达数据集,包括来自乳腺癌和肺癌细胞系的单细胞RNA测序(scRNASeq)数据集、胰腺癌单核RNA测序(snRNASeq)数据集、CyTOF数据集(测量小鼠骨髓细胞)、健康捐赠者的肝脏图谱数据集和血管图谱scRNASeq数据集。这些数据集覆盖了以前被指定为金标准(细胞系)和银标准(门控)的细胞类型标签。
实验结果表明,随机森林模型和先验标记知识最适合主动学习。研究还发现,利用关于标记基因的已知信息可以帮助选择初始细胞并提高主动学习结果。此外,文章提出了适应性重新加权,作为一种补充主动学习的细胞选择程序,可以在单细胞数据上取得良好的性能。
文章还探讨了主动学习在处理细胞类型不平衡数据时的有效性,并发现主动学习方法通常在不平衡的数据集中表现优于随机选择和适应性重新加权方法。此外,研究还测试了主动学习在初始训练集中未标记的细胞类型上的识别能力,发现即使在初始训练阶段未选择这些细胞类型,主动学习方法也能迅速识别出新的细胞类型,尤其是当这些细胞类型彼此足够不同时。
最后,文章还研究了自训练(一种自监督学习方法)在提升细胞类型分类性能方面的效用,并发现自训练可以通过使用一小部分已标记的数据集来训练分类器,然后预测所有剩余(未标记)样本的标签,从而提高分类性能。自训练对分类性能的提升在数据集中已标记细胞较少时最为明显,并且在标记了500个细胞后,这种提升就消失了。
重点关注
一套针对科研实践者的建议,旨在指导他们如何根可用的先验知识、数据集的不平衡性以及希望注释的细胞数量来选择适当的细胞类型选择方法,以辅助基于机器学习的高效注释。
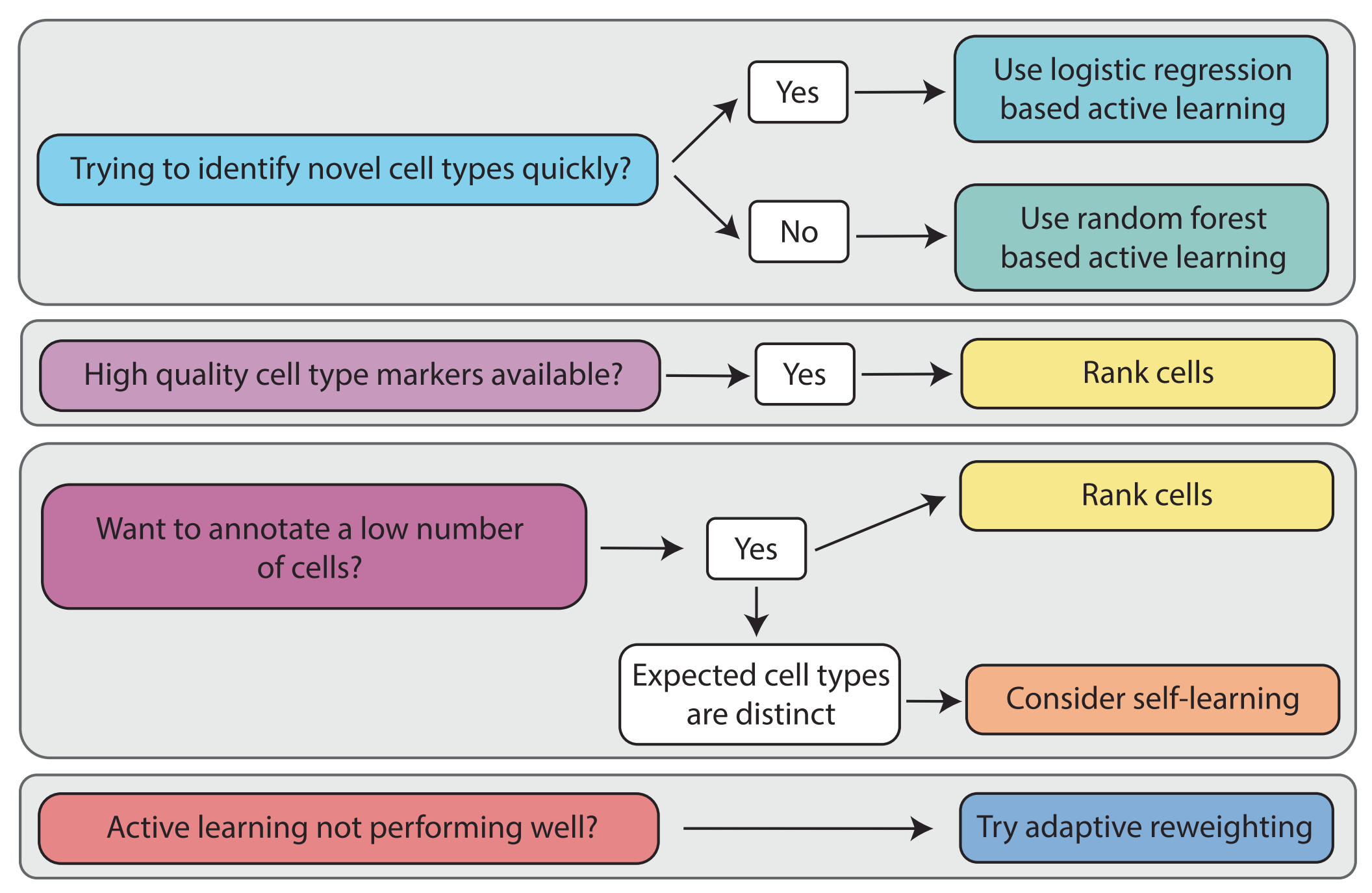
-
数据集不平衡的处理:当某些细胞类型在数据集中占比较少时,可能需要特别设计的算法来确保这些稀有类型的准确注释。
-
注释数量的考量:如果用户只需要注释少量细胞,可能会推荐使用主动学习策略;而对于大规模注释任务,则可能推荐使用自监督学习或其他更自动化的方法。
-
效率与准确性的平衡:讨论在选择方法时如何平衡注释效率和结果准确性,因为不同的方法可能在这两方面有不同的表现。
-
实验设计的考虑:如果实验需要高度精确的细胞类型注释,可能需要采用更为保守和细致的注释策略。
-
资源和时间的限制:考虑用户在资源(如计算能力、资金)和时间上的限制,推荐在这些限制条件下最可行的方法。


















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









