







小罗碎碎念
上个月分享过影像组学和病理组学领域的公开数据集,不过那批数据是从已发表的文献中提取的。
这两天我在查文献的时候,发现了另外一种查找公开数据集的方式——直接搜索标题中含有“dataset”的文献。
首先采用上面提到的方法进行文献检索,然后经过筛选,最终挑出了37篇文献,有一半的文章属于一区。
| 选项 | 数量 |
|---|---|
| Q1 | 20 |
| Q2 | 2 |
| Q3 | 4 |
| #N/A | 11 |
再来看一下文献发表的时间,我们可以很清楚的看到公开数据集的数量是越来越多的。
| 年份 | 数量 |
|---|---|
| 2020 | 2 |
| 2021 | 3 |
| 2022 | 7 |
| 2023 | 10 |
| 2024 | 15 |
再来看一个我们最关心的问题——**这些数据我能不能用?**这里考虑到篇幅原因,我只展示一部分,完整版数据请见表格。
| 项目 | 数量 |
|---|---|
| 多设备/染色 | 1 |
| 多重染色数据集 | 1 |
| 泛癌 | 2 |
| 肺癌多重IHC | 1 |
| 肺部 | 1 |
| 骨关节炎软骨 | 1 |
| 骨髓增生性肿瘤 | 1 |
| 核分割 | 1 |
| 核实例分割 | 2 |
| 空间转录组 | 1 |
| …… | …… |
在本期推文中我会选择部分文章进行分析,分享我是如何通过文献来查找数据集的。
获取方式
我把结果整理成了下面的表格,提供了对应的文章、期刊、影像因子、发表时间以及DOI,方便大家快速查找适合自己的数据集。
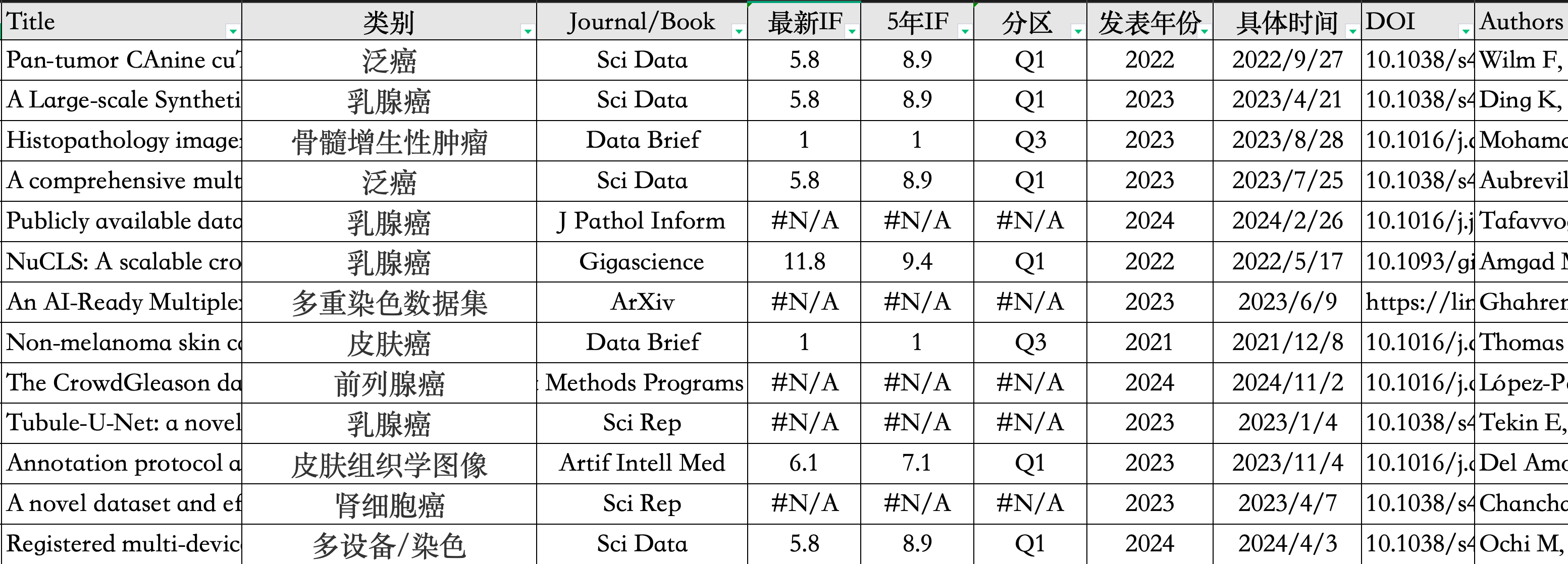
表格我会上传到知识星球的【普遍关注】专栏,感兴趣的可以前往获取。
一、多重染色&空间转录组数据
这一部分总共有三篇文献,为了不影响大家阅读,所以DOI也都给出来了。
| Title | 类别 | Journal/Book | 最新IF | 具体时间 | DOI |
|---|---|---|---|---|---|
| An AI-Ready Multiplex Staining Dataset …… | 头颈癌多重染色 | ArXiv | #N/A | 2023/6/9 | https://link.springer.com/chapter/10.1007/978-3-031-43987-2_68 |
| MIHIC | 肺癌多重IHC | Front Immunol | 5.7 | 2024/2/19 | 10.3389/fimmu.2024.1334348 |
| SpatialCTD | 空间转录组 | J Comput Biol | 1.4 | 2024/8/8 | 10.1089/cmb.2024.0532 |
1-1:头颈鳞状细胞癌多重染色数据集
数据集链接:https://github.com/nadeemlab/DeepLIIF
这篇文章旨在解决如何通过AI技术实现肿瘤免疫微环境的可重复且准确的表征。具体来说,文章探讨了使用较便宜的多重免疫组化(mIHC)染色法替代昂贵的多重免疫荧光(mIF)染色法的可行性。
这篇文章收录在MICCAI2023的文献集中,大家找起来会有些麻烦,为了减轻星球订阅用户的工作量,我会把原文也同步上传!

该数据集包含来自八位头颈鳞状细胞癌患者的重新染色和配准的数字化图像。具体来说,同一肿瘤切片首先使用昂贵的多重免疫荧光(mIF)染色法染色,然后使用较便宜的多重免疫组化(mIHC)染色法重新染色。这是第一个公开的数据集,证明了这两种染色方法的等效性,从而允许多种用例。
这篇论文通过实验证明了mIHC染色法可以替代mIF染色法,并展示了多种应用场景的潜力,具有重要的临床和研究价值。
1-2:肺癌免疫微环境量化的多重IHC病理数据集
链接:https://zenodo.org/records/10065510
这篇文章要解决的问题是如何利用深度学习模型对肺癌免疫微环境(TIME)进行量化分析。具体来说,研究旨在通过多色免疫组化(IHC)染色组织切片图像,构建一个公开可用的数据集(MIHIC),并利用卷积神经网络(CNN)和Transformer模型对这些图像进行分类,以预测患者的生存结果。

研究收集了来自辽宁省肿瘤医院&研究所的47个组织芯片(TMA)切片,包含114名患者的样本。每个TMA切片经过12种不同的IHC染色,包括CD3、CD20、CD34等。
通过两位病理学家的手动注释,识别出不同组织类型的感兴趣区域(ROI),并将其分割成128x128像素的图像块,最终生成309,698个图像块。
1-3:肿瘤微环境空间转录组数据集
链接:https://github.com/OmicsML/SpatialCTD
这篇论文介绍了SpatialCTD,一个大规模的肿瘤微环境空间转录组数据集,用于评估细胞类型反卷积在免疫肿瘤学中的应用。

数据收集:
- 从CosMx平台收集人类肺、肾和肝组织的单细胞分辨率的空间转录组数据,共20个样本。
- 数据集涵盖约180万个细胞,分为肺、肾和肝三个组织。
补充:什么是细胞类型反卷积?
细胞类型反卷积是一种生物信息学方法,用于从混合细胞群体的转录组数据中推断出各个细胞类型的相对丰度。它通常应用于空间转录组学(ST)数据,这些数据在空间上解析了组织的基因表达,但由于每个检测点(spot)可能包含多个细胞,导致基因表达谱是混合的。
反卷积的目标是将这些混合的基因表达谱分解成单个细胞类型的贡献比例。这对于理解组织中的细胞异质性和细胞间相互作用非常重要,尤其是在癌症等复杂疾病的研究中。
常见的细胞类型反卷积方法包括:
-
基于参考的单细胞RNA测序(scRNA-seq)数据的方法:使用已知的单细胞数据进行训练,然后应用于空间转录组数据以推断细胞类型比例。
-
深度学习方法:利用深度学习模型直接从空间转录组数据中学习细胞类型的分布模式。
-
贝叶斯模型:结合单细胞和空间转录组数据,估计每个位置的细胞类型概率。
这些方法帮助研究人员更准确地量化不同细胞类型在组织中的分布,从而更好地理解疾病的机制和潜在的治疗靶点。
二、细胞&核分割
这一部分和大家分享5篇文献,为了不影响大家阅读,DOI也都给出来了。
| Title | 类别 | Journal/Book | 最新IF | 具体时间 | DOI |
|---|---|---|---|---|---|
| CryoNuSeg | 核实例分割 | Comput Biol Med | 7 | 2021/3/28 | 10.1016/j.compbiomed.2021.104349 |
| An annotated fluorescence image dataset for …… | 核分割 | Sci Data | 5.8 | 2020/8/13 | 10.1038/s41597-020-00608-w |
| EVICAN-a balanced dataset for …… | 细胞和细胞核分割 | Bioinformatics | 4.4 | 2020/4/3 | 10.1093/bioinformatics/btaa225 |
| Cyto R-CNN and CytoNuke Dataset | 全细胞分割 | Comput Methods Programs Biomed | #N/A | 2024/5/23 | 10.1016/j.cmpb.2024.108215 |
| NuInsSeg | 核实例分割 | Sci Data | 5.8 | 2024/3/15 | 10.1038/s41597-024-03117-2 |
2-1:CryoNuSeg:核实例分割数据集
链接:https://github.com/masih4/CryoNuSeg
这篇论文介绍了CryoNuSeg数据集,这是第一个完全注释的基于冷冻组织样本(FS)的H&E染色细胞核实例分割数据集。

数据集构建
- 从TCGA数据库中筛选出30张40倍放大倍率的FS来源的H&E染色图像,涵盖10个人体器官。
- 使用ImageJ和QuPath工具进行图像块提取和手动标注,生成二值掩码和辅助分割掩码。
- 数据集包含两位专家的三轮手动标记,以测量观察者内和观察者间的变异性。
2-2:训练核分割方法的荧光图像数据集
链接:https://www.ebi.ac.uk/biostudies/bioimages/studies/S-BSST265
由于核形态、染色强度、细胞密度和核聚集的变化,设计独立于组织类型或制备的分割方法非常复杂。这篇文章旨在解决全自动核图像分割的问题,以确保在数字病理学或定量显微镜学中能够进行统计上显著的定量分析。

- 数据收集: 数据集包括来自多种生物组织和细胞的79张荧光图像,涵盖了病理和非病理性来源的组织切片、冷冻切片、细胞涂片等。使用的样本包括神经母细胞瘤、Wilms肿瘤、正常人角质形成细胞系等。
- 图像采集: 图像使用多种显微镜(如Zeiss Axioplan II、Leica激光扫描显微镜、Zeiss LSM 780和Leica SP8X)在不同放大倍数(10x、20x、40x、63x)下采集。
- 注释过程: 核心步骤如下:
- 初始注释:由学生和经过疾病专家培训的生物学专家进行初步注释。
- 粗略注释:使用基于机器学习的框架进行初步注释,生成核轮廓的粗略注释。
- 精细注释:将注释图像导出为SVG文件,并在Adobe Illustrator中进行精细调整,以确保注释的准确性。
- 最终审核:由病理学家审核所有注释,并根据建议进行修正,形成最终的金标准。
2-3:EVICAN:细胞和细胞核分割
链接:https://edmond.mpg.de/dataset.xhtml?persistentId=doi:10.17617/3.AJBV1S
这篇论文介绍了EVICAN(Expert Visual Cell Annotation)数据集,该数据集旨在为细胞和细胞核分割算法的开发提供平衡且多样化的数据。

- 数据收集: 数据集包含来自30种不同细胞系的4600张部分标注的灰度图像,这些图像来自多个显微镜、对比机制和放大倍率。图像通过不同的显微镜设备(如Opera Phenix、AF7000、IX81和Biorevo BZ-9000)获取,涵盖了多种光学设置。
- 数据标注: 图像中的细胞和细胞核由细胞培养专家手动标注,并与荧光图像匹配以确保准确性。标注过程包括在每个图像中随机选择3-10个细胞和细胞核进行标注,以减少人为偏见。
- 数据集划分: 数据集分为三个子集:训练集(4464张图像)、验证集(1176张图像)和评估集(98张图像)。所有标注均导出为JSON格式,以便于现代机器学习训练。
2-4:CytoNuke Dataset:全细胞分割
链接:https://zenodo.org/records/10560728
这篇文章旨在解决明场组织学切片中全细胞(包括细胞核和细胞质)的分割问题。现有的大多数分割方法仅限于细胞核的分割,无法准确分割细胞质。

- 数据收集: 使用CPTAC数据集中的头颈部鳞状细胞癌图像,手动在QuPath中进行细胞核和细胞注释。所有注释由第三方审查员审核并由高级病理学家批准。
- 数据预处理: 使用Macenko算法对图像进行标准化处理,以消除不同设施之间的染色强度差异。图像被分割成256x256像素的补丁,分辨率为0.5μm/px。
2-5:NulnsSeg:细胞核实例分割数据集
链接:https://github.com/masih4/NuInsSeg
本文介绍了NulnsSeg数据集,这是目前最大的完全手动注释的H&E染色组织学图像中的细胞核实例分割数据集。

这篇文章要解决的问题是如何在计算病理学中实现自动化的细胞核实例分割。
- 数据收集:数据集包含来自31个人类和小鼠器官的665个图像块,每个图像块包含超过30,000个手动分割的细胞核。这些图像块是从23种不同的人类组织中获得的,使用TissueFAXS扫描系统生成全视野图像(WSIs),并选择最具代表性的视野生成数据集。
- 数据注释:使用ImageJ软件手动绘制细胞核边界,并使用Matlab软件生成二进制和标记的分割图像。此外,还提供了辅助分割掩码和模糊区域掩码,这些掩码有助于开发基于计算机的分割模型。
三、更多数据集
考虑到篇幅和时间,我就暂且分析上述八篇文章对应的数据集,如果需要更多的数据集,可以前往知识星球获取完整版表格!


















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









