







小罗碎碎念
这篇文章介绍了一种基于深度学习的人工智能模型(DeepGEM),该模型能够从常规组织学切片中准确预测肺癌患者的基因突变情况,显示出在临床治疗指导中的潜在应用价值。
准确检测驱动基因突变对于肺癌患者的治疗计划和预后预测至关重要。传统的基因组测试需要高质量的组织样本,耗时且资源消耗大,因此大多数患者无法进行这种测试,特别是在资源有限的地区。
研究的主要目的是开发一种基于深度学习的人工智能方法(DeepGEM),用于从常规获取的组织学切片中预测肺癌患者的基因突变情况。该模型能使重症症状患者更快接受靶向治疗,并使在无法进行全面基因组检测的不发达地区的患者受益,从而可能改善更广泛患者的治疗结果。DeepGEM模型的准确性和泛化能力令人鼓舞,将其定位为辅助工具,用于识别可能从靶向治疗和免疫治疗中受益的患者,从而促进患者管理和临床决策。

| 作者类型 | 姓名 | 单位(中文) |
|---|---|---|
| 第一作者 | Yu Zhao | 广州医科大学第一附属医院胸外科和肿瘤科;腾讯AI实验室,深圳,中国 |
| 第一作者 | Shan Xiong | 广州医科大学第一附属医院胸外科和肿瘤科;横琴医院,广州医科大学第一附属医院,中国 |
| 第一作者 | Qin Ren | 腾讯AI实验室,深圳,中国 |
| 第一作者 | Jun Wang | 腾讯AI实验室,深圳,中国 |
| 第一作者 | Min Li | 中南大学湘雅医院呼吸内科,国家重点临床专科,国家临床研究中心呼吸病分中心,长沙,中国 |
| 通讯作者 | Wenhua Liang | 广州医科大学第一附属医院胸外科和肿瘤科,呼吸病国家重点实验室&国家呼吸病临床研究中心,广州,中国 |
文献概述
研究收集了来自中国16家医院的肺癌患者的活检和多基因下一代测序数据,形成了一个大型多中心数据集,包含配对的病理图像和多基因突变信息。
研究还包括了来自公开数据集The Cancer Genome Atlas (TCGA)的患者数据。开发的模型是一种实例级和包级共同监督的多重实例学习方法,具有标签消歧设计。模型在内部数据集上进行训练和初步测试,并在外部数据集和公开的TCGA数据集上进行进一步评估。
研究纳入了3637名患者(3767张图像),模型在内部数据集上表现出稳健的性能。对于切除活检样本,基因突变预测的AUC值范围为0.90到0.97,准确度值范围为0.91到0.97。对于穿刺活检样本,AUC值范围为0.85到0.95,准确度值范围为0.79到0.99。在多中心外部数据集上,模型也表现出强大的性能。此外,模型在TCGA数据集上也表现出色。
一、预后研究
今天分享的这篇文章属于目前比较热门的“预后研究”范畴,所以在正式介绍这篇论文前,我想和大家先分享一下目前预后领域的论文发表情况。
熟悉柳叶刀肿瘤风格的同学,对于下面这个部分一定很熟悉——描述作者如何进行背景调研。

那我们既然是分享文献,那不妨深入探索一下,我们也来模仿作者做一个背景调研,只不过我们是针对整个预后的研究领域做一个调研!
1-1:趋势分析
预后相关的研究,热度持续高涨,2024年的发表的论文数量接近前一年的两倍。
医学AI在肿瘤预后中的研究始于2019年,即使在剔除掉部分低质量文献以后,目前也已经累计发表了3114篇文献。
| 年份 | 相关论文数量 |
|---|---|
| 2019 | 7 |
| 2020 | 423 |
| 2021 | 465 |
| 2022 | 541 |
| 2023 | 596 |
| 2024 | 1070 |
| 2025 | 12 |
下表展示了2024年发表的1070篇预后相关文章的分区情况,我们会发现,大部分文章都发表在较好的期刊,所以预后还是一个值得持续投入的研究。但是按照目前这种趋势来看,如何在预后这个大背景下,真正做出面向临床的成果才是我们迫切需要解决的问题!
| 季度 | 论文数量 |
|---|---|
| Q1 | 672 |
| Q2 | 295 |
| Q3 | 86 |
| Q4 | 17 |
1-2:最新进展
截止我写完推文(24-12-10),预后研究领域已有10篇Nat Med于2024年发表。
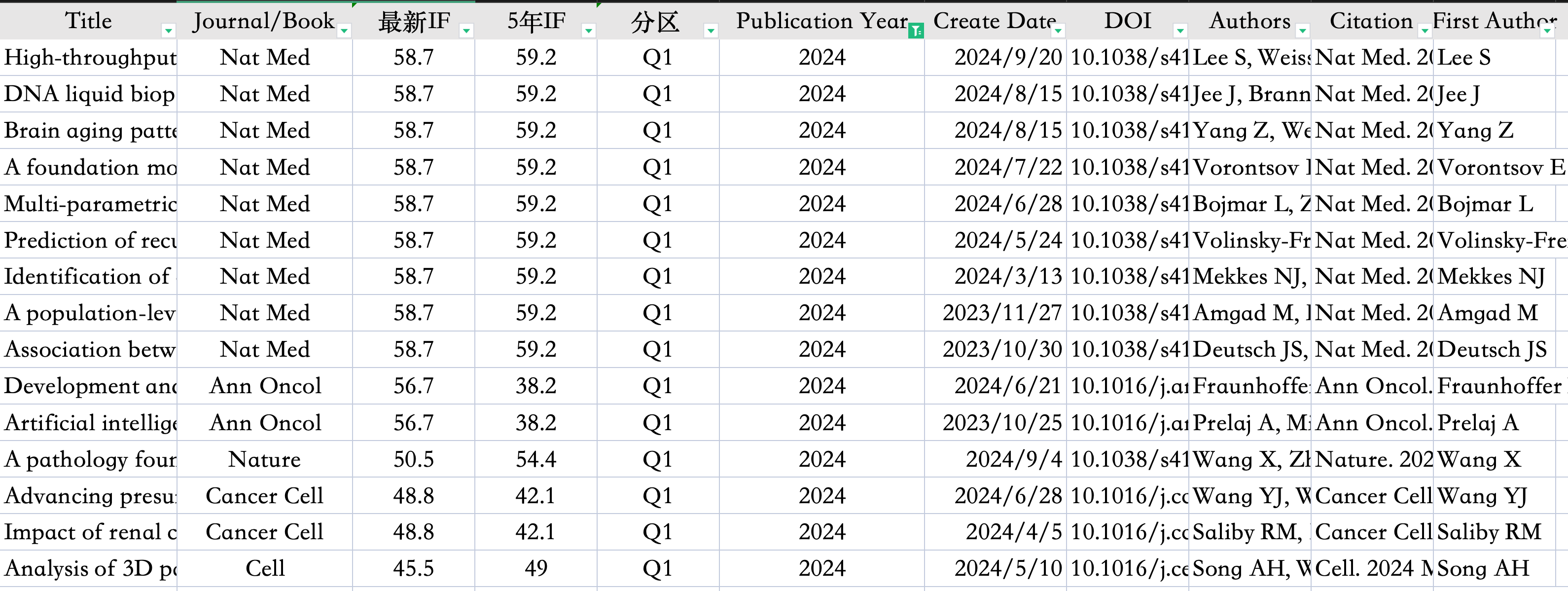
但是也要提醒大家,目前这个领域已经被大部分人盯上了,所以竞争非常激烈。我按照发表日期进行了降序排列,大家可以清晰的看到,最新发表的很多文章,只有今天分享的这篇超过了10分,并且1区和2区几乎对半分——这表明,两极分化很严重——也意味着,想不费力就发一个好文章,需要再找下一个热点了!
二、研究方法
2-1:研究设计与参与者
本研究纳入了2018年1月1日至2022年3月31日在16个中心接受活检和多基因下一代测序的所有符合条件的肺癌患者。
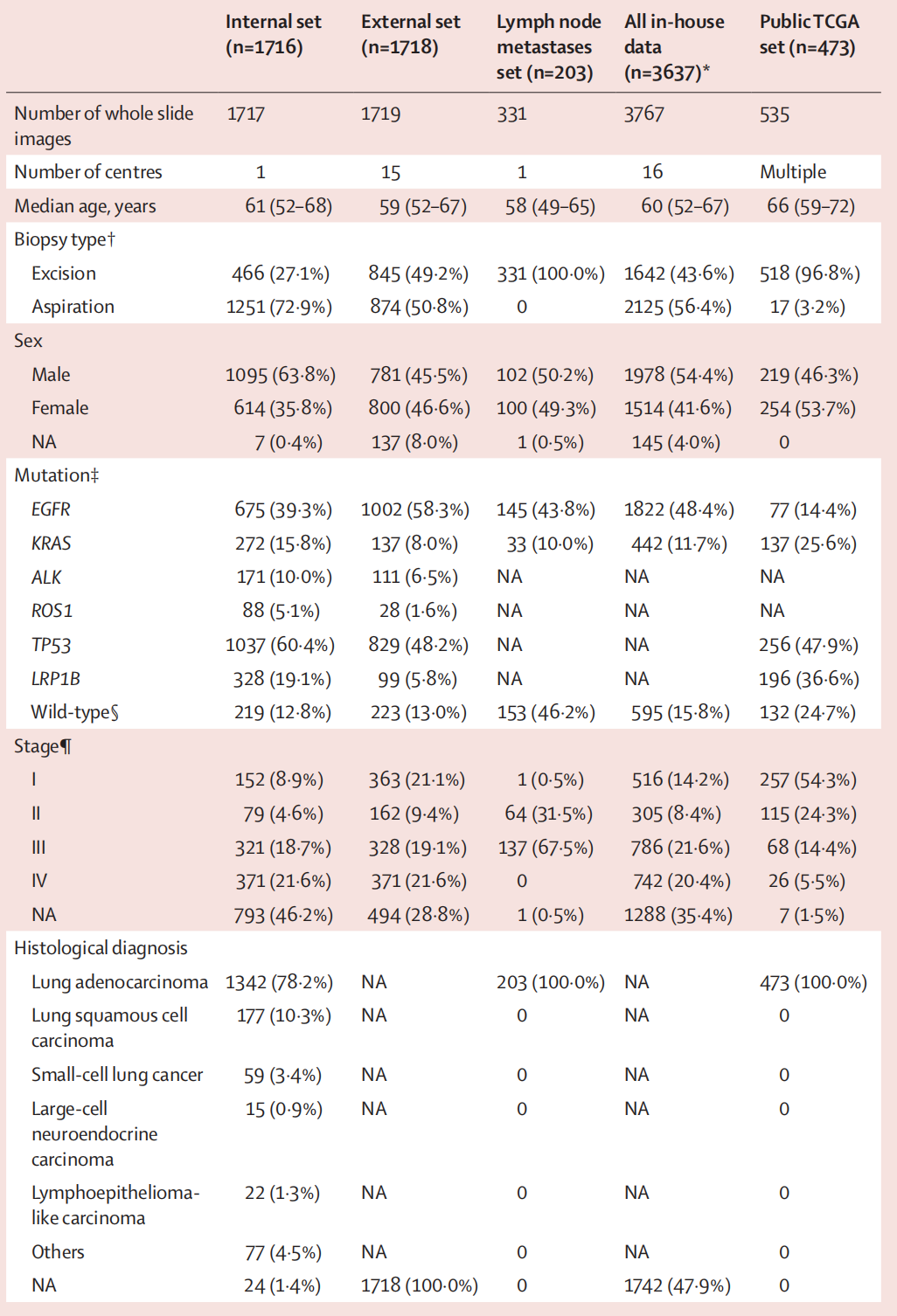
收集了参与者的基线特征,包括年龄、性别、肿瘤分期和组织学类型,这些数据来源于16个参与医疗中心的病历记录。记录中未包含种族数据。数据收集于2022年4月完成。
纳排标准
纳入标准为患者具有可评估的病理图像和可用的基因突变信息,排除标准为图像质量低。
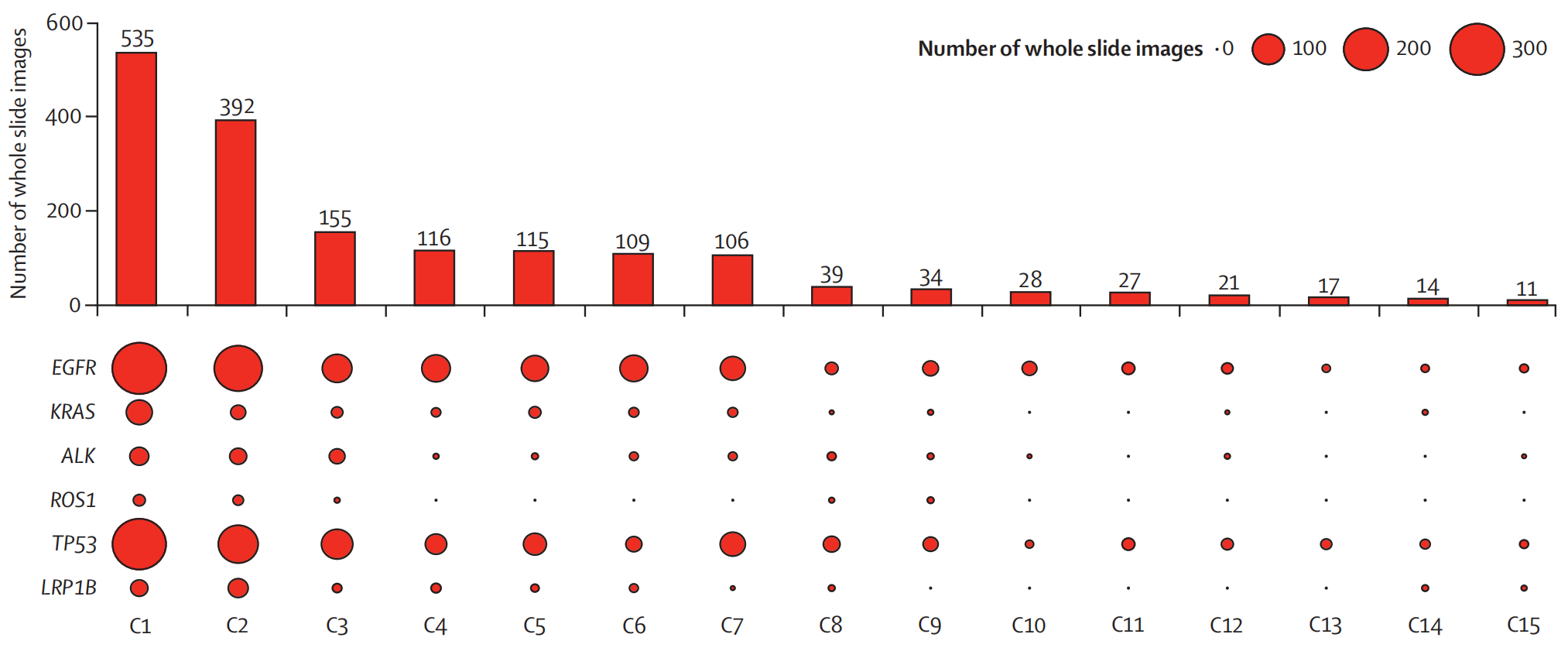
鉴于中国各中心医疗资源存在显著不平衡,所选医疗中心范围从资源丰富、声誉高、患者数量多的中心到资源较少、患者数量少的中心(图1A;中心类型和位置详情见附录2第11页)。
我们将多中心数据分为三个数据集:内部数据集(来自中国广州医科大学第一附属医院的 患者)、外部数据集(来自其他15个中心的 患者)和淋巴结转移数据集(来自中国广州医科大学第一附属医院的淋巴结转移患者,与内部数据集无重叠)。
此外,为了评估DeepGEM模型在不同种族背景患者中的表现,纳入了公共TCGA数据集中的额外患者。与用于DeepPATH研究的患者队列相似,22仅纳入了肺腺癌患者。
注意,内部数据集和外部数据集的分配由各中心完成,并在模型开发过程中采用了广泛使用的随机训练-验证-测试数据分割方法,以防止引入偏差。
2-2:具体细节
内部和外部数据集中的全切片图像是使用Leica Aperio CS2扫描仪(Leica Biosystems, Buffalo Grove, IL, USA)制作的,标本级像素大小为0·250 μm× 0·250 μm。使用了20倍物镜,并将全切片图像统一到0·500 μm× 0·500 μm的像素大小。
淋巴结转移数据集中的切片使用3DHISTECH Pannoramic 250 Flash III扫描仪(3DHISTECH, Budapest, Hungary)进行数字化,标本级像素大小为0·500 μm× 0·500 μm。内部数据集、外部数据集和淋巴结转移数据集中的所有肿瘤样本均进行了Hotspot panel基因组测序,使用包含168个或520个癌症相关基因的测序面板,测序覆盖深度为1000×,测序工作由广州燃石生物科技有限公司完成(具体细节见附录2第3-4页)。
所有切片和遗传测试结果由广州医科大学第一附属医院的两位专家病理学家(PH和YZhe)进行审查。
2-3:模型介绍
DeepGEM模型利用实例级和包级共监督的多实例学习流程,有效地从整个全切片图像中学习信息性特征。
模型主要包括三个部分:
- 一个预训练特征编码器,这是我们之前开发的通用特征编码器CTransPath20,使用自监督学习方法在大规模未标记病理图像数据集上预训练的;
- 一个由残差变换块组成的变换器骨干,用于校准获得的斑块特征并编码上下文信息和斑块相关性;
- 一个特殊设计的全切片图像(包)级和斑块(实例)级共监督模块,共同优化DeepGEM模型。
共监督设计还使得DeepGEM模型能够作为一个多任务学习框架。包级监督通道更侧重于全局总结整个切片图像以进行预测,而实例级监督通道则专注于局部识别关键相关斑块。
在推理阶段,由于包级监督通道被训练为从所有斑块中全局总结信息以进行预测,因此包级输出作为最终预测。标签消歧模块在实例级监督中扮演核心角色,负责纠正分配给斑块的模糊标签。
详细方法见附录2(第4-7页,第41页)。
三、模型性能介绍
3-1:不同基因在不同样本类型中的预测性能数据
这张图片展示了一个表格,表格中包含了不同基因在不同样本类型中的预测性能数据。
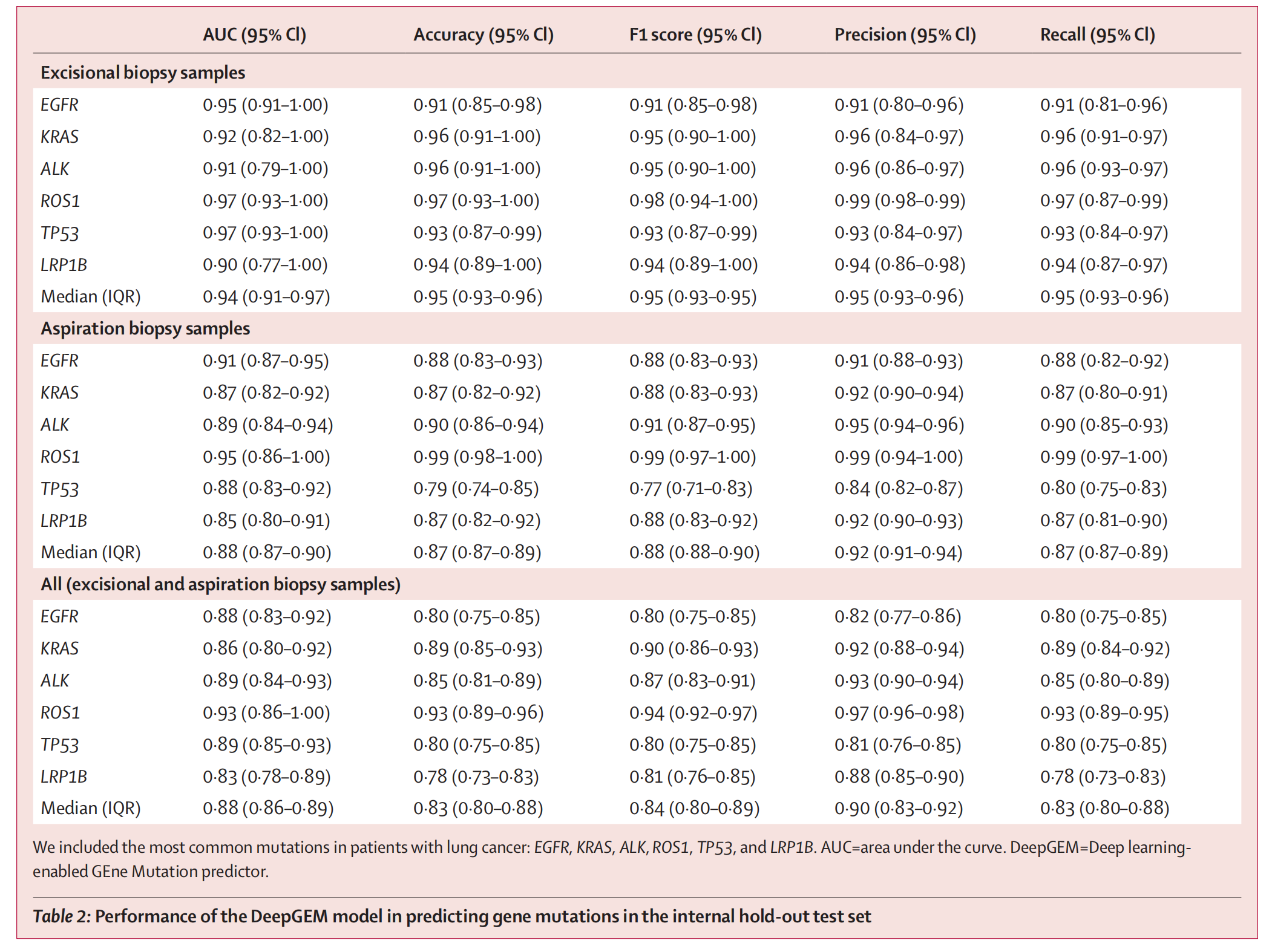
具体来说,表格分为三大部分:
-
第一部分:切除活检样本(Excisional biopsysamples)
- 这部分表格列出了在切除活检样本中,几种常见基因(EGFR、KRAS、ALK、ROS1、TP53、LRP1B)和中位(IQR)的预测性能数据。
- 每一行对应一个基因,每一列对应一个性能指标,包括AUC(曲线下面积)、Accuracy(准确率)、F1 score(F1分数)、Precision(精确率)和Recall(召回率)。
- 每个性能指标后面的括号内是95%置信区间。
-
第二部分:穿刺活检样本(Aspiration biopsysamples)
- 这部分表格列出了在穿刺活检样本中,同样几种基因和中位(IQR)的预测性能数据。
- 格式与第一部分相同,每一行对应一个基因,每一列对应一个性能指标。
-
第三部分:所有切除和穿刺活检样本(All (excisional and aspiration) biopsysamples)
- 这部分表格列出了在所有样本(包括切除和穿刺活检样本)中,同样几种基因和中位(IQR)的预测性能数据。
- 格式与前两部分相同。
在表格的底部,有一段注释,说明了表格中包含的常见基因(EGFR、KRAS、ALK、ROS1、TP53、LRP1B)以及DeepGEM(深度学习基因变异预测器)的相关信息。
3-2:DeepGEM模型在预测TCGA数据集中基因突变的性能
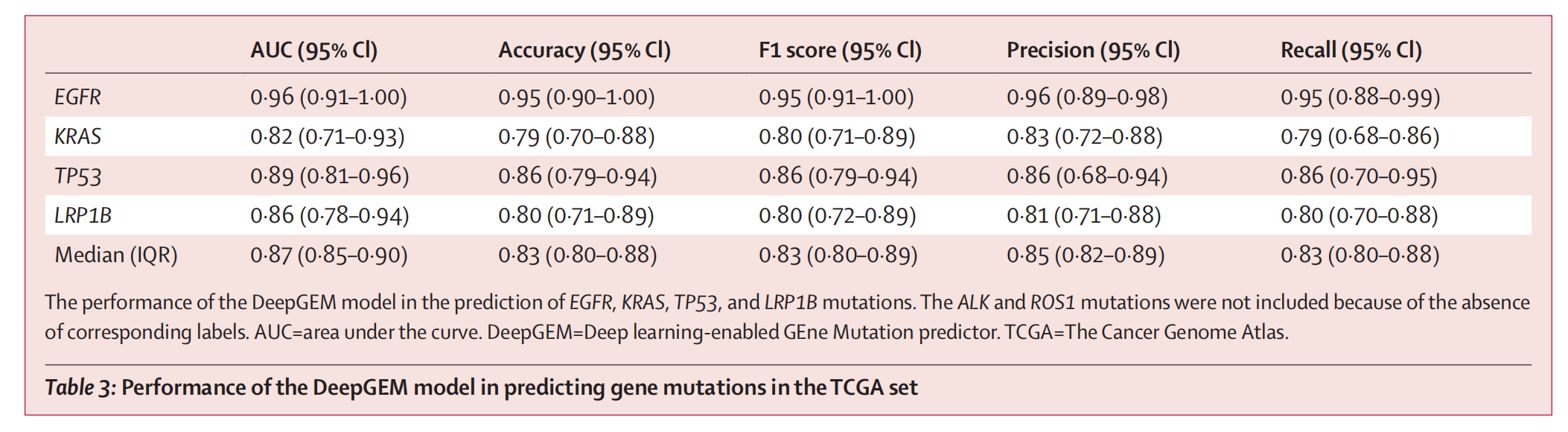
- 表格结构
- 表格有六列,分别是:
- AUC (95% CI):曲线下面积(95% 置信区间)
- Accuracy (95% CI):准确率(95% 置信区间)
- F1 score (95% CI):F1分数(95% 置信区间)
- Precision (95% CI):精确率(95% 置信区间)
- Recall (95% CI):召回率(95% 置信区间)
- 表格有5行,分别对应不同的基因和一个中位数(IQR):
- EGFR
- KRAS
- TP53
- LRP1B
- Median (IQR)
- 表格有六列,分别是:
- 表格底部注释
- DeepGEM模型在预测EGFR、KRAS、TP53和LRP1B基因突变的性能。由于缺乏相应标签,ALK和ROS1突变未包括在内。AUC=曲线下面积。DeepGEM=深度学习支持的基因突变预测器。TCGA=癌症基因组图谱。
这张表格主要展示了DeepGEM模型在预测特定基因突变时的各项性能指标,帮助评估模型在不同基因上的预测准确性。
3-3:DeepGEM模型对淋巴结转移活检样本的泛化性能
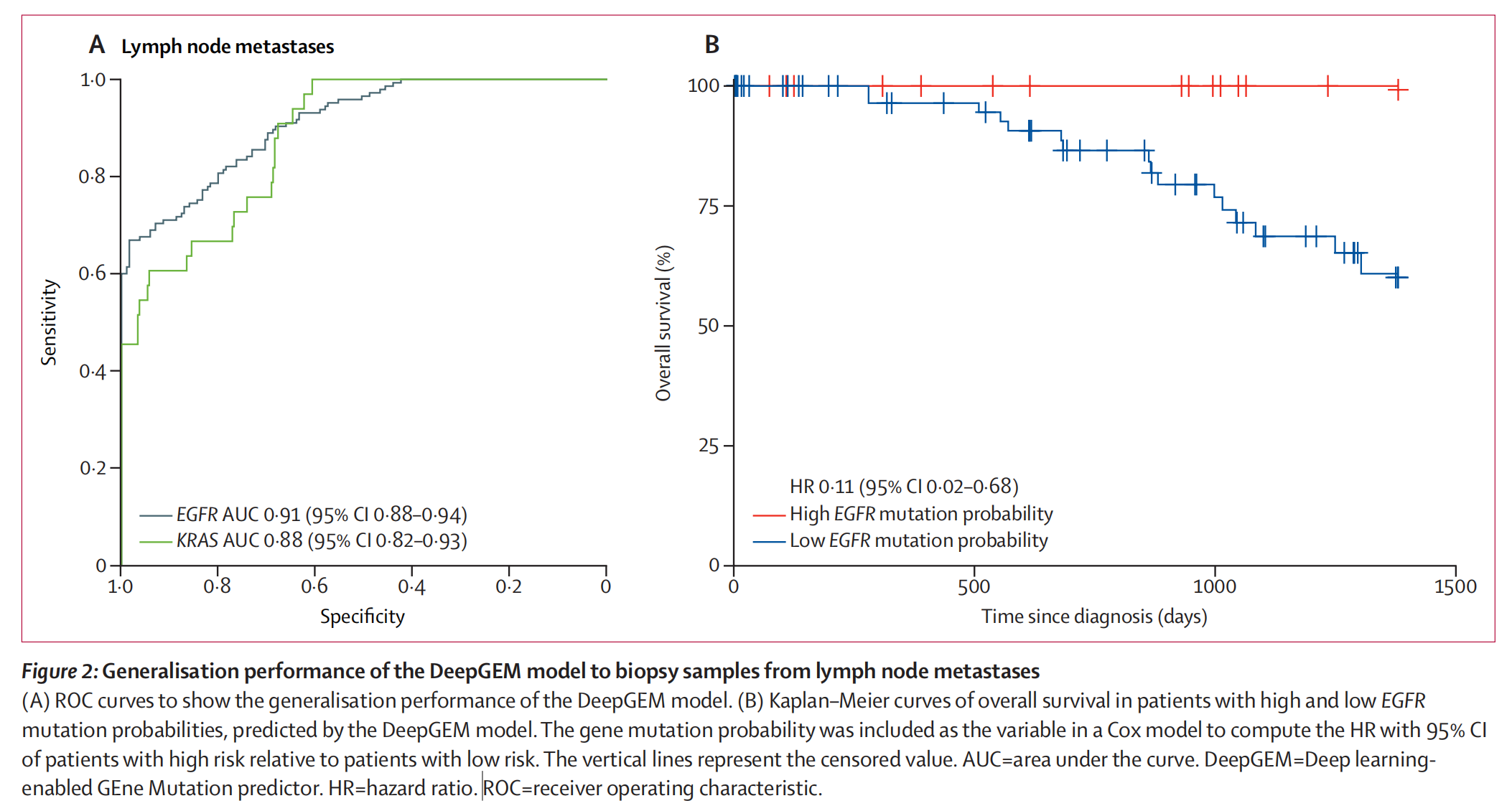
图表A
- 这是一个ROC(Receiver Operating Characteristic)曲线图表,展示了DeepGEM模型在预测淋巴结转移时的泛化性能。
- 横轴(Specificity):特异性,范围从0到1。
- 纵轴(Sensitivity):敏感性,范围从0到1。
- 曲线:
- 绿色曲线代表KRAS的AUC(Area Under the Curve)为0.88(95% CI: 0.82-0.93)。
- 黑色曲线代表EGFR的AUC为0.91(95% CI: 0.88-0.94)。
- 这些曲线展示了模型在不同阈值下的敏感性和特异性之间的权衡。
图表B
- 这是一个Kaplan-Meier生存曲线图表,展示了高和低EGFR突变概率患者的总体生存率。
- 横轴(Time since diagnosis, days):自诊断以来的时间,范围从0到1500天。
- 纵轴(Overall survival, %):总体生存率,范围从0到100%。
- 曲线:
- 蓝色曲线代表低EGFR突变概率患者的生存曲线。
- 红色曲线代表高EGFR突变概率患者的生存曲线。
- 图中显示高EGFR突变概率患者的总体生存率较高,HR(Hazard Ratio)为0.11(95% CI: 0.02-0.68)。

3-4:特定突变相关的主要斑块
这张图乍一看有点懵,其实就是为了展示不同基因突变与组织亚型之间的关系。
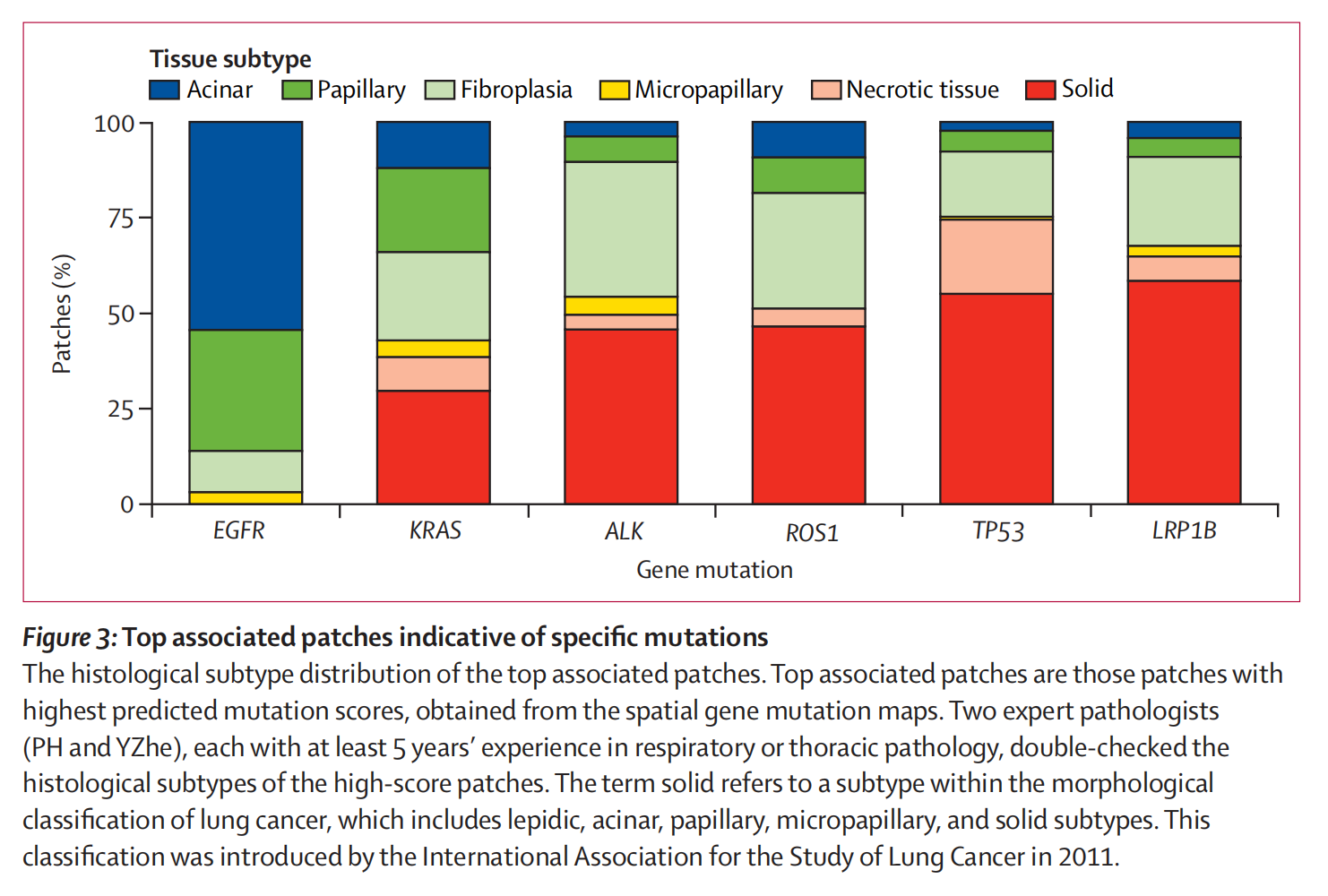
图表结构
- 横轴:表示不同的基因突变类型,包括EGFR、KRAS、ALK、ROS1、TP53和LRP1B。
- 纵轴:表示斑块的百分比(Patches (%)),范围从0到100%。
- 图例:
- 蓝色代表“Acinar”(腺泡状)
- 绿色代表“Papillary”(乳头状)
- 黄色代表“Fibroplasia”(纤维增生)
- 橙色代表“Micropapillary”(微乳头状)
- 浅橙色代表“Necrotic tissue”(坏死组织)
- 红色代表“Solid”(实性)
图例说明
- 图表底部有一段说明文字,解释了主要斑块的定义和组织亚型的分类方法。主要斑块是指从空间基因变异图中获得的预测突变分数最高的斑块。
- 组织亚型的分类由两位至少有5年呼吸或胸科病理学经验的专家病理学家(PH和YZhe)进行了双重检查。
- “Solid”是指肺癌形态学分类中的一种亚型,包括脂质、腺泡状、乳头状、微乳头状和实性亚型,这一分类由国际肺癌研究协会在2011年提出。


















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









