






免费查看,个人自用

特征重用是轻量卷积神经网络设计的关键技术。当前的方法涌常利用连接运算符通过重用其他层的特征映射来廉价地保持大通道数(以而增加网络容量)。虽然连接不需要参数和fps,但它在硬件设备上的计算成本是不可忽略的。针对这一问题,本文提出了利用结构重参数化技术实现特征重用的新思路。
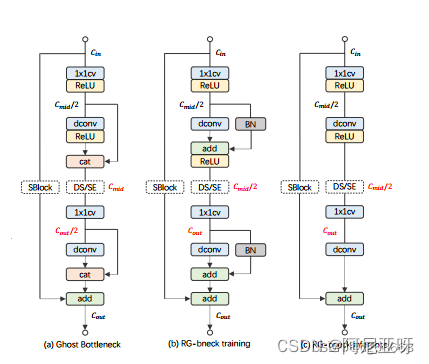
Ghost Bottleneck模块
改进步骤:
1.步骤一
在models文件夹下新建RepGhost.py文件,加入以下代码
import copy
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8 mg
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
def hard_sigmoid(x, inplace: bool = False):
if inplace:
return x.add_(3.0).clamp_(0.0, 6.0).div_(6.0)
else:
return F.relu6(x + 3.0) / 6.0
class SqueezeExcite(nn.Module):
def __init__(
self,
in_chs,
se_ratio=0.25,
reduced_base_chs=None,
#act_layer=nn.ReLU,
act_layer=nn.SiLU,
gate_fn=hard_sigmoid,
divisor=4,
**_,
):
super(SqueezeExcite, self).__init__()
self.gate_fn = gate_fn
reduced_chs = _make_divisible(
(reduced_base_chs or in_chs) * se_ratio, divisor,
)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_reduce = nn.Conv2d(in_chs, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, in_chs, 1, bias=True)
def forward(self, x):
x_se = self.avg_pool(x)
x_se = self.conv_reduce(x_se)
x_se = self.act1(x_se)
x_se = self.conv_expand(x_se)
x = x * self.gate_fn(x_se)
return x
class ConvBnAct(nn.Module):
def __init__(self, in_chs, out_chs, kernel_size, stride=1, act_layer=nn.SiLU):
super(ConvBnAct, self).__init__()
self.conv = nn.Conv2d(
in_chs, out_chs, kernel_size, stride, kernel_size // 2, bias=False,
)
self.bn1 = nn.BatchNorm2d(out_chs)
self.act1 = act_layer(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn1(x)
x = self.act1(x)
return x
class RepGhostModule(nn.Module):
def __init__(
self, inp, oup, kernel_size=1, dw_size=3, stride=1, relu=True, deploy=False, reparam_bn=True, reparam_identity=False
):
super(RepGhostModule, self).__init__()
init_channels = oup
new_channels = oup
self.deploy = deploy
self.primary_conv = nn.Sequential(
nn.Conv2d(
inp, init_channels, kernel_size, stride, kernel_size // 2, bias=False,
),
nn.BatchNorm2d(init_channels),
nn.SiLU(inplace=True) if relu else nn.Sequential(),
)
fusion_conv = []
fusion_bn = []
if not deploy and reparam_bn:
fusion_conv.append(nn.Identity())
fusion_bn.append(nn.BatchNorm2d(init_channels))
if not deploy and reparam_identity:
fusion_conv.append(nn.Identity())
fusion_bn.append(nn.Identity())
self.fusion_conv = nn.Sequential(*fusion_conv)
self.fusion_bn = nn.Sequential(*fusion_bn)
self.cheap_operation = nn.Sequential(
nn.Conv2d(
init_channels,
new_channels,
dw_size,
1,
dw_size // 2,
groups=init_channels,
bias=deploy,
),
nn.BatchNorm2d(new_channels) if not deploy else nn.Sequential(),
# nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
if deploy:
self.cheap_operation = self.cheap_operation[0]
if relu:
self.relu = nn.SiLU(inplace=False)
else:
self.relu = nn.Sequential()
def forward(self, x):
x1 = self.primary_conv(x)#mg
x2 = self.cheap_operation(x1)
for conv, bn in zip(self.fusion_conv, self.fusion_bn):
x2 = x2 + bn(conv(x1))
return self.relu(x2)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.cheap_operation[0], self.cheap_operation[1])
for conv, bn in zip(self.fusion_conv, self.fusion_bn):
kernel, bias = self._fuse_bn_tensor(conv, bn, kernel3x3.shape[0], kernel3x3.device)
kernel3x3 += self._pad_1x1_to_3x3_tensor(kernel)
bias3x3 += bias
return kernel3x3, bias3x3
@staticmethod
def _pad_1x1_to_3x3_tensor(kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
@staticmethod
def _fuse_bn_tensor(conv, bn, in_channels=None, device=None):
in_channels = in_channels if in_channels else bn.running_mean.shape[0]
device = device if device else bn.weight.device
if isinstance(conv, nn.Conv2d):
kernel = conv.weight
assert conv.bias is None
else:
assert isinstance(conv, nn.Identity)
kernel_value = np.zeros((in_channels, 1, 1, 1), dtype=np.float32)
for i in range(in_channels):
kernel_value[i, 0, 0, 0] = 1
kernel = torch.from_numpy(kernel_value).to(device)
if isinstance(bn, nn.BatchNorm2d):
running_mean = bn.running_mean
running_var = bn.running_var
gamma = bn.weight
beta = bn.bias
eps = bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
assert isinstance(bn, nn.Identity)
return kernel, torch.zeros(in_channels).to(kernel.device)
def switch_to_deploy(self):
if len(self.fusion_conv) == 0 and len(self.fusion_bn) == 0:
return
kernel, bias = self.get_equivalent_kernel_bias()
self.cheap_operation = nn.Conv2d(in_channels=self.cheap_operation[0].in_channels,
out_channels=self.cheap_operation[0].out_channels,
kernel_size=self.cheap_operation[0].kernel_size,
padding=self.cheap_operation[0].padding,
dilation=self.cheap_operation[0].dilation,
groups=self.cheap_operation[0].groups,
bias=True)
self.cheap_operation.weight.data = kernel
self.cheap_operation.bias.data = bias
self.__delattr__('fusion_conv')
self.__delattr__('fusion_bn')
self.fusion_conv = []
self.fusion_bn = []
self.deploy = True
class RepGhostBottleneck(nn.Module):
"""RepGhost bottleneck w/ optional SE"""
def __init__(
self,
in_chs,
mid_chs,
out_chs,
dw_kernel_size=3,
stride=1,
se_ratio=0.0,
shortcut=True,
reparam=True,
reparam_bn=True,
reparam_identity=False,
deploy=False,
):
super(RepGhostBottleneck, self).__init__()
has_se = se_ratio is not None and se_ratio > 0.0
self.stride = stride
self.enable_shortcut = shortcut
self.in_chs = in_chs
self.out_chs = out_chs
# Point-wise expansion
self.ghost1 = RepGhostModule(
in_chs,
mid_chs,
relu=True,
reparam_bn=reparam and reparam_bn,
reparam_identity=reparam and reparam_identity,
deploy=deploy,
)
# Depth-wise convolution
if self.stride > 1:
self.conv_dw = nn.Conv2d(
mid_chs,
mid_chs,
dw_kernel_size,
stride=stride,
padding=(dw_kernel_size - 1) // 2,
groups=mid_chs,
bias=False,
)
self.bn_dw = nn.BatchNorm2d(mid_chs)
# Squeeze-and-excitation
if has_se:
self.se = SqueezeExcite(mid_chs, se_ratio=se_ratio)
else:
self.se = None
# Point-wise linear projection
self.ghost2 = RepGhostModule(
mid_chs,
out_chs,
relu=False,
reparam_bn=reparam and reparam_bn,
reparam_identity=reparam and reparam_identity,
deploy=deploy,
)
# shortcut
if in_chs == out_chs and self.stride == 1:
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
nn.Conv2d(
in_chs,
in_chs,
dw_kernel_size,
stride=stride,
padding=(dw_kernel_size - 1) // 2,
groups=in_chs,
bias=False,
),
nn.BatchNorm2d(in_chs),
nn.Conv2d(
in_chs, out_chs, 1, stride=1,
padding=0, bias=False,
),
nn.BatchNorm2d(out_chs),
)
def forward(self, x):
residual = x
x1 = self.ghost1(x)
if self.stride > 1:
x = self.conv_dw(x1)
x = self.bn_dw(x)
else:
x = x1
if self.se is not None:
x = self.se(x)
# 2nd repghost bottleneck mg
x = self.ghost2(x)
if not self.enable_shortcut and self.in_chs == self.out_chs and self.stride == 1:
return x
return x + self.shortcut(residual)
# def repghost_model_convert(model:torch.nn.Module, save_path=None, do_copy=True):
# """
# taken from from https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
# """
# if do_copy:
# model = copy.deepcopy(model)
# for module in model.modules():
# if hasattr(module, 'switch_to_deploy'):
# module.switch_to_deploy()
# if save_path is not None:
# torch.save(model.state_dict(), save_path)
# return model
def repghost_model_convert(model:torch.nn.Module, save_path=None, do_copy=True):
"""
taken from from https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
"""
if do_copy:
model = copy.deepcopy(model)
for module in model.modules():
if hasattr(module, 'switch_to_deploy'):
module.switch_to_deploy()
if save_path is not None:
torch.save(model, save_path)
return model2.步骤二
在common.py文件中加入如下代码
class C2frepghost(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) #
self.m = nn.ModuleList(RepGhostBottleneck(self.c, self.c, self.c,dw_kernel_size=((3),(3))) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))3.步骤三
在yolo.py文件中加入以下代码:
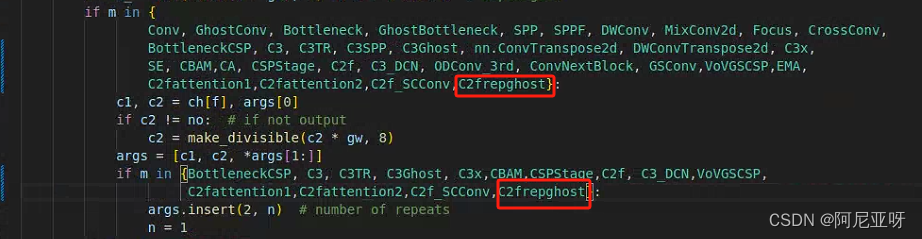
4.步骤四
创建yaml文件:
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 45 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C2frepghost, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C2frepghost, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C2frepghost, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C2frepghost, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C2frepghost, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C2frepghost, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C2frepghost, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C2frepghost, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]

















 802
802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









