







本文参考:
[1]知乎专栏:https://zhuanlan.zhihu.com/p/27627299
[2]博客园:https://www.cnblogs.com/LBSer/p/4440590.html
[3]Andrew Ng:https://class.coursera.org/ml-003/lecture/21
定义
数据标准化(Normalization),也称为归一化,归一化就是将你需要处理的数据在通过某种算法经过处理后,限制将其限定在你需要的一定的范围内。
数据标准化处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要对数据进行归一化处理,解决数据指标之间的可比性问题。
为什么归一化
在喂给机器学习模型的数据中,对数据要进行归一化的处理。
为什么要进行归一化处理,下面从寻找最优解这个角度给出自己的看法。
例子
假定为预测房价的例子,自变量为面积,房间数两个,因变量为房价。
那么可以得到的公式为:
![[公式]](https://img-blog.csdnimg.cn/20210127022550437.png)
其中x1代表房间数,
其中x2代表面积。
首先我们祭出两张图代表数据是否均一化的最优解寻解过程。
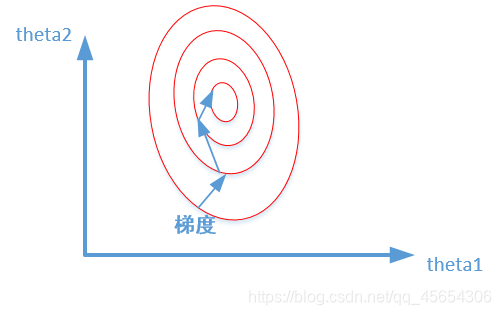
未归一化:
归一化之后
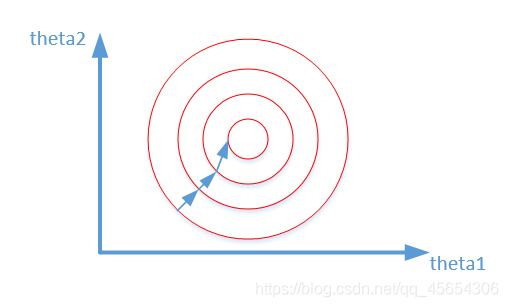
我们在寻找最优解的过程也就是在使得损失函数值最小的theta1,theta2。
上述两幅图代码的是损失函数的等高线。
我们很容易看出,当数据没有归一化的时候,面积数的范围可以从0 ~ 1000,房间数的范围一般为0~10,可以看出面积数的取值范围远大于房间数。
不归一化的影响
数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
归一化的作用
维基百科给出的解释:
1)归一化后加快了梯度下降求最优解的速度;
2)归一化有可能提高精度。
归一化的类型
线性归一化
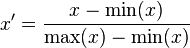
这种归一化方法比较适用在数值比较集中的情况。这种方法有个缺陷,如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量值来替代max和min。
标准差标准化
经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
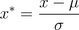
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
非线性归一化
经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等。需要根据数据分布的情况,决定非线性函数的曲线,比如log(V, 2)还是log(V, 10)等。















 1263
1263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









