







欢迎大家关注全网生信学习者系列:
- WX公zhong号:生信学习者
- Xiao hong书:生信学习者
- 知hu:生信学习者
- CDSN:生信学习者2
介绍
Alpha多样性主要关注的是样品内部的多样性,即一个特定区域或生态系统内的物种丰富度和均匀度。它的原理是通过统计一个群落中不同物种的数量和相对丰度来评估该群落的生物多样性。它可以用来评估不同环境条件下的微生物群落结构,比如不同土壤样本或不同人体部位的微生物组成。它可以帮助我们了解单个样本内部的微生物组成复杂性,比如一个特定人体部位的微生物多样性水平。它通过以下几个指数来衡量:
- Chao1指数和ACE指数:用于估计群落中物种总数,反映群落的丰富度。
- Shannon指数:综合考虑了群落的丰富度和均匀度,指数值越高,表明群落的多样性越高。
- Simpson指数:用来估算样品中微生物的多样性,值越大,说明群落多样性越低。
Beta多样性关注的是样品间的多样性,即不同生态系统或同一生态系统内不同位置的微生物群落之间的差异。它的原理是通过比较不同样本间的微生物群落组成来揭示它们之间的相似性或差异性。这有助于研究不同环境因素如何影响微生物群落结构,例如不同地理位置、不同宿主或不同疾病状态下的微生物群落变化。它可以揭示不同样本间的微生物群落结构差异,比如健康和疾病状态下的微生物群落差异,或者不同环境条件下的微生物群落差异。它的计算通常基于样本间的物种组成和丰度差异,使用以下方法:
- 距离矩阵:基于OTU的群落比较方法,如欧式距离、Jaccard距离等,以及考虑系统发生关系的Unifrac距离。
- PCA(主成分分析)、PCoA(主坐标分析)**和**NMDS(非度量多维尺度分析):这些方法用于可视化样本间的相似性和差异性。
加载R包
library(openxlsx)
library(tidyverse)
library(CLME)
library(ggprism)
library(ggsci)
library(ggpubr)
library(RColorBrewer)
library(microbiome)
library(jtools)
library(vegan)
library(rstatix)
library(RVAideMemoire)
导入数据
大家通过以下链接下载数据:
- 百度网盘链接:https://pan.baidu.com/s/1fz5tWy4mpJ7nd6C260abtg
- 提取码: 请关注WX公zhong号_生信学习者_后台发送 复现gmsb 获取提取码
# OTU table
otu_table <- read_tsv("./data/GMSB-data/otu-table.tsv")
# Taxonomy table
tax <- read_tsv("./data/GMSB-data/taxonomy.tsv")
# Tree
tree <- read_tree("./data/GMSB-data/tree.nwk")
# Metadata
meta_data <- read_csv("./data/GMSB-data/df_v1.csv")
数据预处理
-
Phyloseq object:生成phyloseq数据对象
-
rarefy_even_depth:抽平处理
# OTU table
otu_id <- otu_table$`#OTU ID`
otu_table <- data.frame(otu_table[, -1], check.names = FALSE, row.names = otu_id)
# Taxonomy table
otu_id <- tax$`Feature ID`
tax <- data.frame(tax[, - c(1, 3)], row.names = otu_id)
tax <- tax %>%
tidyr::separate(col = Taxon,
into = c("Kingdom", "Phylum", "Class", "Order",
"Family", "Genus", "Species"),
sep = ";") %>%
dplyr::rowwise() %>%
dplyr::mutate_all(function(x) strsplit(x, "__")[[1]][2]) %>%
dplyr::mutate(Species = ifelse(!is.na(Species) & !is.na(Genus),
paste(ifelse(strsplit(Genus, "")[[1]][1] == "[",
strsplit(Genus, "")[[1]][2],
strsplit(Genus, "")[[1]][1]), Species, sep = "."), NA)) %>%
dplyr::ungroup()
tax <- as.matrix(tax)
rownames(tax) <- otu_id
tax[tax == ""] <- NA
# Meta data
meta_data$status <- factor(meta_data$status, levels = c("nc", "sc"))
meta_data$time2aids <- factor(meta_data$time2aids,
levels = c("never", "> 10 yrs",
"5 - 10 yrs", "< 5 yrs"))
# Phyloseq object
OTU <- otu_table(otu_table, taxa_are_rows = TRUE)
META <- sample_data(meta_data)
sample_names(META) <- meta_data$sampleid
TAX <- tax_table(tax)
otu_data <- phyloseq(OTU, TAX, META, tree)
species_data <- aggregate_taxa(otu_data, "Species")
th <- quantile(sample_sums(species_data), 0.1) # 12,158
species_data <- prune_samples(sample_sums(species_data)>=th, species_data)
species_rarefied <- rarefy_even_depth(
species_data,
rngseed = 1,
sample.size = th,
replace = FALSE)
species_rarefied
phyloseq-class experiment-level object
otu_table() OTU Table: [ 113 taxa and 218 samples ]
sample_data() Sample Data: [ 218 samples by 45 sample variables ]
tax_table() Taxonomy Table: [ 113 taxa by 8 taxonomic ranks ]
画图函数
plot_clme: Constrained Inference for Linear Mixed Effects Models(线性混合效应模型的约束推理)的可视化结果
plot_clme <- function (
clme_obj, group,
y_min, y_max,
p_gap, ann_pos,
decreasing = FALSE, ...) {
overall_p <- clme_obj$p.value
ind_p <- clme_obj$p.value.ind
est_mean <- clme_obj$theta[group]
est_se <- sqrt(diag(clme_obj$cov.theta))[group]
df_fig <- data.frame(x = group, y = est_mean, err = est_se)
if (decreasing) {
df_p <- data.frame(group1 = group[seq_len(length(group) - 1)],
group2 = group[-1],
x = group[-1],
label = paste0("p = ", round(ind_p, 3)),
y.position = seq.int(from = ifelse(est_mean[1] > min(est_mean),
est_mean[1] + p_gap,
est_mean[1] + 2 * p_gap),
to = min(est_mean) + p_gap,
length.out = length(group) - 1))
} else {
df_p <- data.frame(group1 = group[seq_len(length(group) - 1)],
group2 = group[-1],
x = group[-1],
label = paste0("p = ", round(ind_p, 3)),
y.position = seq.int(from = est_mean[2] + p_gap,
to = ifelse(est_mean[2] < max(est_mean),
max(est_mean) + p_gap,
max(est_mean) + 2 * p_gap),
length.out = length(group) - 1))
}
df_ann <- data.frame(x = group[1], y = ann_pos,
fill = "white",
label = paste0("Trend p-value = ", round(overall_p, 3)))
fig <- df_fig %>%
ggplot(aes(x = x, y = y)) +
geom_bar(stat = "identity", color = "black", aes(fill = x)) +
geom_errorbar(aes(ymin = y - 1.96 * err, ymax = y + 1.96 * err),
width = .2, position = position_dodge(.9)) +
add_pvalue(df_p,
xmin = "group1",
xmax = "group2",
label = "label",
y.position = "y.position",
remove.bracket = FALSE,
...) +
geom_label(data = df_ann, aes(x = x, y = y, label = label),
size = 4, vjust = -0.5, hjust = 0, color = "black") +
ylim(y_min, y_max) +
theme_bw()
return(fig)
}
Primary group
Primary group: 按照频率分组
-
G1: # receptive anal intercourse = 0
-
G2: # receptive anal intercourse = 1
-
G3: # receptive anal intercourse = 2 - 5
-
G4: # receptive anal intercourse = 6 +
Alpha diversities
-
Observed species: richness measure, which returns observed richness.
-
Shannon index: diversity measure, which takes into account richness, divergence and evenness.
-
P-value is obtained by linear regressions adjusting for abx usage.
d_alpha <- microbiome::alpha(species_rarefied, index = c("observed", "diversity_shannon"))
df_alpha <- data.frame(sampleid = meta(species_rarefied)$sampleid,
subjid = meta(species_rarefied)$subjid,
group = meta(species_rarefied)$group1,
abx_use = meta(species_rarefied)$abx_use,
Observed = d_alpha$observed,
Shannon = d_alpha$diversity_shannon,
check.names = FALSE) %>%
dplyr::filter(group != "missing")
df_alpha$group <- recode(df_alpha$group,
`g1` = "G1", `g2` = "G2",
`g3` = "G3", `g4` = "G4")
df_fig <- df_alpha %>%
tidyr::gather(key = "measure", value = "value", Observed:Shannon)
df_fig$measure <- factor(df_fig$measure,
levels = c("Observed", "Shannon"))
df_fig$group <- factor(df_fig$group, levels = c("G1", "G2", "G3", "G4"))
stat_test1 <- df_fig %>%
dplyr::filter(measure == "Observed") %>%
lm(formula = value ~ group + abx_use)
stat_test2 <- df_fig %>%
dplyr::filter(measure == "Shannon") %>%
lm(formula = value ~ group + abx_use)
- Observed species
summ(stat_test1)
MODEL INFO:
Observations: 216
Dependent Variable: value
Type: OLS linear regression
MODEL FIT:
F(4,211) = 1.91, p = 0.11
R² = 0.03
Adj. R² = 0.02
Standard errors: OLS
------------------------------------------------
Est. S.E. t val. p
----------------- ------- ------ -------- ------
(Intercept) 22.39 0.61 36.78 0.00
groupG2 0.26 0.82 0.31 0.75
groupG3 -0.20 0.75 -0.26 0.80
groupG4 -1.08 0.95 -1.14 0.26
abx_useyes -1.20 0.59 -2.03 0.04
------------------------------------------------
- Shannon index
summ(stat_test2)
MODEL INFO:
Observations: 216
Dependent Variable: value
Type: OLS linear regression
MODEL FIT:
F(4,211) = 0.50, p = 0.73
R² = 0.01
Adj. R² = -0.01
Standard errors: OLS
------------------------------------------------
Est. S.E. t val. p
----------------- ------- ------ -------- ------
(Intercept) 1.22 0.03 37.69 0.00
groupG2 0.03 0.04 0.71 0.48
groupG3 -0.02 0.04 -0.46 0.65
groupG4 -0.03 0.05 -0.55 0.58
abx_useyes 0.02 0.03 0.64 0.52
------------------------------------------------
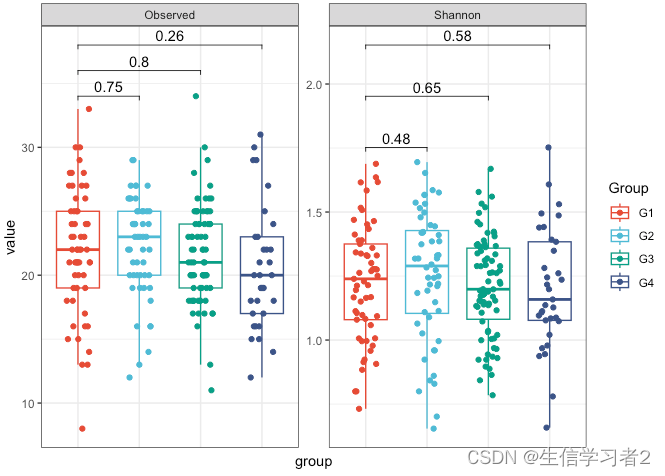
- Box plot
df_stat <- data.frame(p = round(summary(stat_test1)$coef[2:4, "Pr(>|t|)"], 2)) %>%
dplyr::mutate(x = "group", y = "value", measure = "Observed",
group1 = "G1", group2 = c("G2", "G3", "G4"),
y.position = max(stat_test1$model$value) + seq(0, 4, 2)) %>%
dplyr::bind_rows(
data.frame(p = round(summary(stat_test2)$coef[2:4, "Pr(>|t|)"], 2)) %>%
dplyr::mutate(x = "group", y = "value", measure = "Shannon",
group1 = "G1", group2 = c("G2", "G3", "G4"),
y.position = max(stat_test2$model$value) + seq(0, 0.4, 0.2))
)
p <- df_fig %>%
ggboxplot(x = "group", y = "value", color = "group",
add = "jitter",
xlab = FALSE, ylab = FALSE, title = FALSE) +
stat_pvalue_manual(df_stat, label = "p", tip.length = 0.01) +
scale_color_npg(name = "Group") +
facet_wrap(.~measure, scale = "free", nrow = 1) +
theme_bw() +
theme(axis.ticks.x = element_blank(),
axis.text.x = element_blank(),
plot.title = element_text(hjust = 0.5))
p
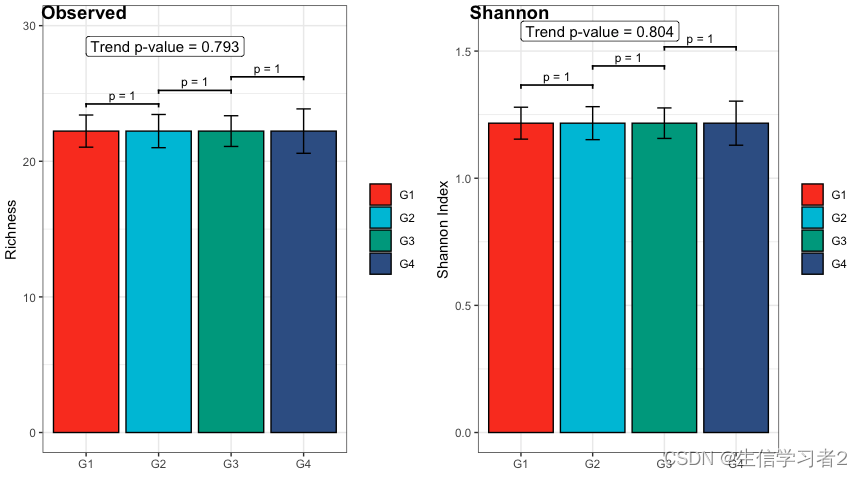
- Monotonically increasing trend test
df_alpha$group <- factor(df_alpha$group, levels = c("G1", "G2", "G3", "G4"), ordered = TRUE)
cons <- list(order = "simple", decreasing = FALSE, node = 1)
fit1 <- clme(Observed ~ group + abx_use, data = df_alpha, constraints = cons, seed = 123)
summ_fit1 <- summary(fit1)
fig1_increase_species <- plot_clme(
summ_fit1,
group = c("G1", "G2", "G3", "G4"),
y_min = 0, y_max = 30,
p_gap = 2, ann_pos = 27) +
scale_fill_npg(name = NULL) +
labs(x = NULL, y = "Richness")
fit2 <- clme(Shannon ~ group + abx_use, data = df_alpha, constraints = cons, seed = 123)
summ_fit2 <- summary(fit2)
fig2_increase_species <- plot_clme(
summ_fit2,
group = c("G1", "G2", "G3", "G4"),
y_min = 0, y_max = 1.6,
p_gap = 0.15, ann_pos = 1.5) +
scale_fill_npg(name = NULL) +
labs(x = NULL, y = "Shannon Index")
cowplot::plot_grid(
fig1_increase_species, fig2_increase_species,
align = "h", ncol = 2,
labels = c("Observed", "Shannon"))
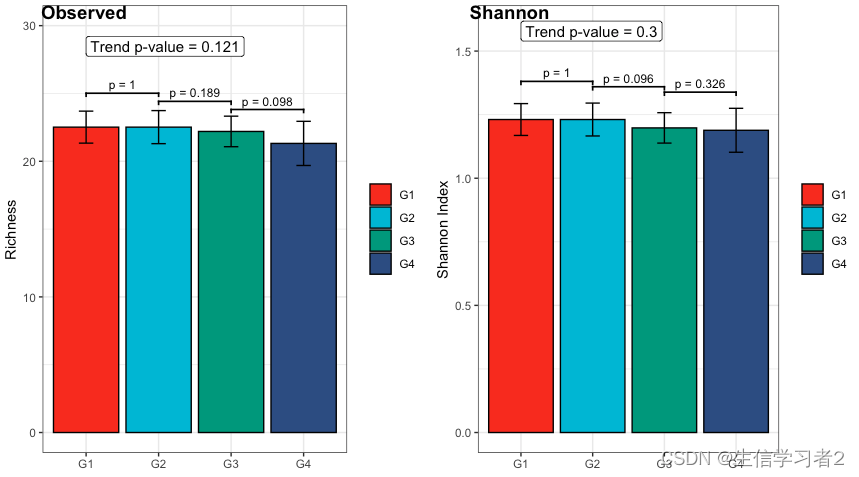
- Monotonically decreasing trend test
cons <- list(order = "simple", decreasing = TRUE, node = 1)
fit1 <- clme(Observed ~ group + abx_use, data = df_alpha, constraints = cons, seed = 123)
summ_fit1 <- summary(fit1)
fig1_decrease_species <- plot_clme(
summ_fit1,
group = c("G1", "G2", "G3", "G4"),
y_min = 0, y_max = 30,
p_gap = 2.5, ann_pos = 27, decreasing = TRUE) +
scale_fill_npg(name = NULL) +
labs(x = NULL, y = "Richness")
fit2 <- clme(Shannon ~ group + abx_use, data = df_alpha, constraints = cons, seed = 123)
summ_fit2 <- summary(fit2)
fig2_decrease_species <- plot_clme(
summ_fit2,
group = c("G1", "G2", "G3", "G4"),
y_min = 0, y_max = 1.6,
p_gap = 0.15, ann_pos = 1.5, decreasing = TRUE) +
scale_fill_npg(name = NULL) +
labs(x = NULL, y = "Shannon Index")
cowplot::plot_grid(
fig1_decrease_species, fig2_decrease_species,
align = "h", ncol = 2,
labels = c("Observed", "Shannon"))
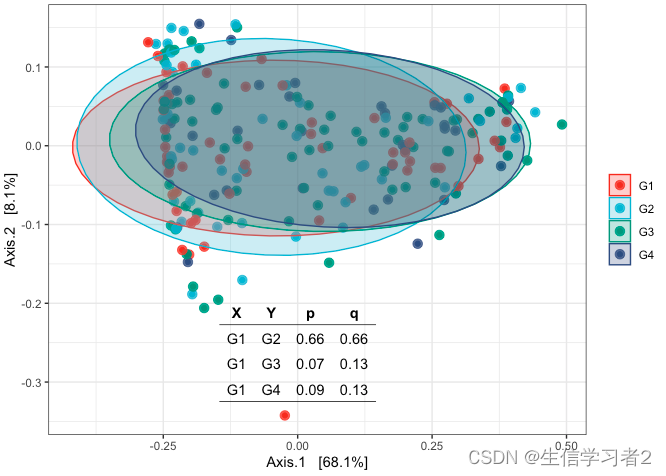
Beta diversity
-
P-values are obtained by PERMANOVA
-
Dissimilarity measure: Bray-Curtis
species_rarefied <- subset_samples(species_rarefied, group1 != "missing")
dis <- phyloseq::distance(species_rarefied, method = "bray")
mds <- ordinate(species_rarefied, "MDS", distance = dis)
# PCoA plot
fig_beta_species <- plot_ordination(species_rarefied,
mds, color = "group1") +
geom_point(size = 3, alpha = 0.8) +
stat_ellipse(geom = "polygon", type = "t", level = 0.8,
aes(fill = group1), alpha = 0.25) +
scale_color_npg(name = NULL, labels = c("G1", "G2", "G3", "G4")) +
scale_fill_npg(name = NULL, labels = c("G1", "G2", "G3", "G4")) +
theme_bw()
# P-values
groups <- meta(species_rarefied)$group1
set.seed(123)
stat_test <- pairwise.perm.manova(resp = dis, fact = groups, nperm = 999, p.method = "none")
df_p <- data.frame(X = rep("G1", 3),
Y = c("G2", "G3", "G4"),
p = round(stat_test$p.value[, "g1"], 2),
q = round(p.adjust(stat_test$p.value[, "g1"], method = "BH"), 2))
tab_beta_species <- ggtexttable(df_p, rows = NULL, theme = ttheme("light"))
fig_beta_species_comb <- fig_beta_species +
annotation_custom(ggplotGrob(tab_beta_species),
xmin = -0.25, ymin = -0.7, xmax = 0.25)
fig_beta_species_comb
Secondary grouping
Secondary group: 按照频率分组2
-
G1: # receptive anal intercourse = 0
-
G2: # receptive anal intercourse = 1
-
G3: # receptive anal intercourse = 2 - 3
-
G4: # receptive anal intercourse = 4 - 8
-
G5: # receptive anal intercourse = 9 +
Alpha diversities
-
Observed species: richness measure, which returns observed richness.
-
Shannon index: diversity measure, which takes into account richness, divergence and evenness.
-
P-value is obtained by linear regressions adjusting for abx usage.
d_alpha <- microbiome::alpha(species_rarefied, index = c("observed", "diversity_shannon"))
df_alpha <- data.frame(sampleid = meta(species_rarefied)$sampleid,
subjid = meta(species_rarefied)$subjid,
group = meta(species_rarefied)$group2,
abx_use = meta(species_rarefied)$abx_use,
Observed = d_alpha$observed,
Shannon = d_alpha$diversity_shannon,
check.names = FALSE) %>%
dplyr::filter(group != "missing")
df_alpha$group <- recode(df_alpha$group,
`g1` = "G1", `g2` = "G2",
`g3` = "G3", `g4` = "G4", `g5` = "G5")
df_fig <- df_alpha %>%
tidyr::gather(key = "measure", value = "value", Observed:Shannon)
df_fig$measure <- factor(df_fig$measure,
levels = c("Observed", "Shannon"))
df_fig$group <- factor(df_fig$group, levels = c("G1", "G2", "G3", "G4", "G5"))
stat_test1 <- df_fig %>%
dplyr::filter(measure == "Observed") %>%
lm(formula = value ~ group + abx_use)
stat_test2 <- df_fig %>%
dplyr::filter(measure == "Shannon") %>%
lm(formula = value ~ group + abx_use)
- Observed species
summ(stat_test1)
MODEL INFO:
Observations: 216
Dependent Variable: value
Type: OLS linear regression
MODEL FIT:
F(5,210) = 1.38, p = 0.23
R² = 0.03
Adj. R² = 0.01
Standard errors: OLS
------------------------------------------------
Est. S.E. t val. p
----------------- ------- ------ -------- ------
(Intercept) 22.41 0.61 36.67 0.00
groupG2 0.26 0.82 0.31 0.76
groupG3 -0.47 0.84 -0.56 0.58
groupG4 -0.22 0.92 -0.24 0.81
groupG5 -0.83 1.09 -0.77 0.44
abx_useyes -1.24 0.60 -2.09 0.04
------------------------------------------------
- Shannon index
summ(stat_test2)
MODEL INFO:
Observations: 216
Dependent Variable: value
Type: OLS linear regression
MODEL FIT:
F(5,210) = 0.73, p = 0.60
R² = 0.02
Adj. R² = -0.01
Standard errors: OLS
------------------------------------------------
Est. S.E. t val. p
----------------- ------- ------ -------- ------
(Intercept) 1.22 0.03 37.72 0.00
groupG2 0.03 0.04 0.71 0.48
groupG3 0.01 0.04 0.20 0.84
groupG4 -0.04 0.05 -0.89 0.38
groupG5 -0.05 0.06 -0.95 0.34
abx_useyes 0.02 0.03 0.72 0.47
------------------------------------------------
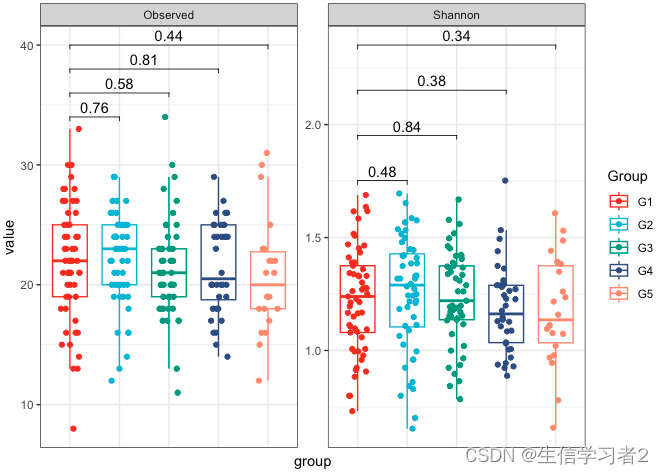
- Box plot
df_stat <- data.frame(p = round(summary(stat_test1)$coef[2:5, "Pr(>|t|)"], 2)) %>%
mutate(x = "group", y = "value", measure = "Observed",
group1 = "G1", group2 = c("G2", "G3", "G4", "G5"),
y.position = max(stat_test1$model$value) + seq(0, 6, 2)) %>%
bind_rows(
data.frame(p = round(summary(stat_test2)$coef[2:5, "Pr(>|t|)"], 2)) %>%
mutate(x = "group", y = "value", measure = "Shannon",
group1 = "G1", group2 = c("G2", "G3", "G4", "G5"),
y.position = max(stat_test2$model$value) + seq(0, 0.6, 0.2))
)
p <- df_fig %>%
ggboxplot(x = "group", y = "value", color = "group",
add = "jitter",
xlab = FALSE, ylab = FALSE, title = FALSE) +
stat_pvalue_manual(df_stat, label = "p", tip.length = 0.01) +
scale_color_npg(name = "Group") +
facet_wrap(.~measure, scale = "free", nrow = 1) +
theme_bw() +
theme(axis.ticks.x = element_blank(),
axis.text.x = element_blank(),
plot.title = element_text(hjust = 0.5))
p
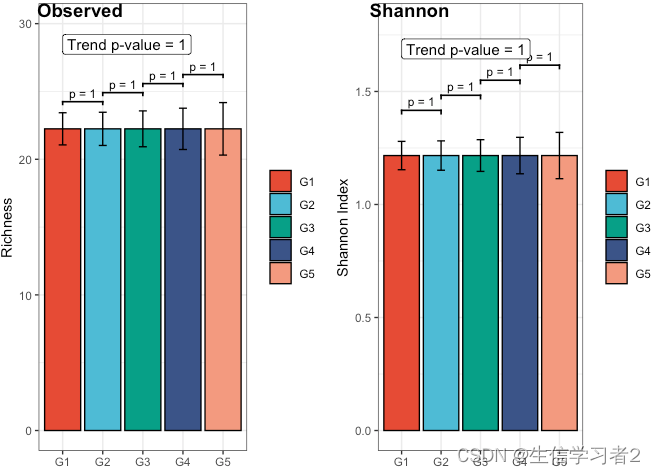
- Monotonically increasing trend test
df_alpha$group <- factor(df_alpha$group, levels = c("G1", "G2", "G3", "G4", "G5"), ordered = TRUE)
cons <- list(order = "simple", decreasing = FALSE, node = 1)
fit1 <- clme(Observed ~ group + abx_use, data = df_alpha, constraints = cons, seed = 123)
summ_fit1 <- summary(fit1)
fig1_increase_species_secondary <- plot_clme(
summ_fit1,
group = c("G1", "G2", "G3", "G4", "G5"),
y_min = 0, y_max = 30,
p_gap = 2, ann_pos = 27) +
scale_fill_npg(name = NULL) +
labs(x = NULL, y = "Richness")
fit2 <- clme(Shannon ~ group + abx_use, data = df_alpha, constraints = cons, seed = 123)
summ_fit2 <- summary(fit2)
fig2_increase_species_secondary <- plot_clme(
summ_fit2,
group = c("G1", "G2", "G3", "G4", "G5"),
y_min = 0, y_max = 1.8,
p_gap = 0.2, ann_pos = 1.6) +
scale_fill_npg(name = NULL) +
labs(x = NULL, y = "Shannon Index")
fig2_increase_species_secondary
cowplot::plot_grid(
fig1_increase_species_secondary, fig2_increase_species_secondary,
align = "h", ncol = 2,
labels = c("Observed", "Shannon"))
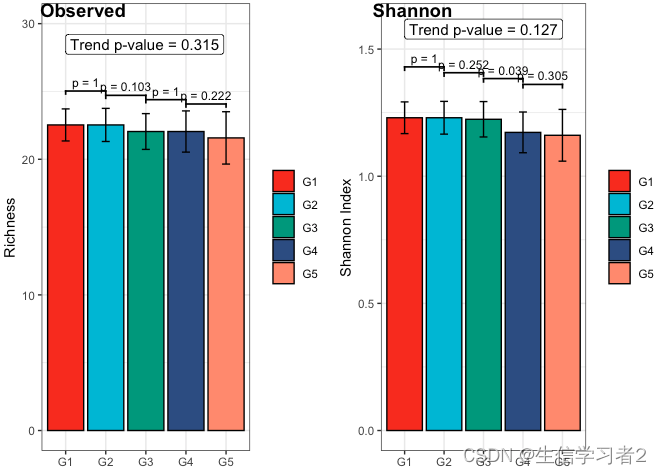
- Monotonically decreasing trend test
cons <- list(order = "simple", decreasing = TRUE, node = 1)
fit1 <- clme(Observed ~ group + abx_use, data = df_alpha, constraints = cons, seed = 123)
summ_fit1 <- summary(fit1)
fig1_decrease_species_secondary <- plot_clme(
summ_fit1,
group = c("G1", "G2", "G3", "G4", "G5"),
y_min = 0, y_max = 30,
p_gap = 2.5, ann_pos = 27, decreasing = TRUE) +
scale_fill_npg(name = NULL) +
labs(x = NULL, y = "Richness")
fit2 <- clme(Shannon ~ group + abx_use, data = df_alpha, constraints = cons, seed = 123)
summ_fit2 <- summary(fit2)
fig2_decrease_species_secondary <- plot_clme(
summ_fit2,
group = c("G1", "G2", "G3", "G4", "G5"),
y_min = 0, y_max = 1.6,
p_gap = 0.2, ann_pos = 1.5, decreasing = TRUE) +
scale_fill_npg(name = NULL) +
labs(x = NULL, y = "Shannon Index")
cowplot::plot_grid(
fig1_decrease_species_secondary, fig2_decrease_species_secondary,
align = "h", ncol = 2,
labels = c("Observed", "Shannon"))
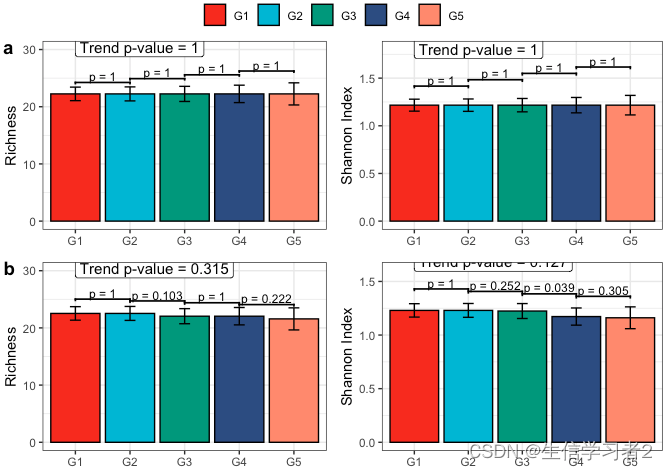
- 合并所有图
fig <- ggarrange(
fig1_increase_species_secondary, fig2_increase_species_secondary,
fig1_decrease_species_secondary, fig2_decrease_species_secondary,
nrow = 2, ncol = 2, common.legend = TRUE,
labels = c("a", "", "b", ""))
fig
Beta diversity {.tabset}
-
P-values are obtained by PERMANOVA
-
Dissimilarity measure: Bray-Curtis
species_rarefied <- subset_samples(species_rarefied, group2 != "missing")
dis <- phyloseq::distance(species_rarefied, method = "bray")
mds <- ordinate(species_rarefied, "MDS", distance = dis)
# PCoA plot
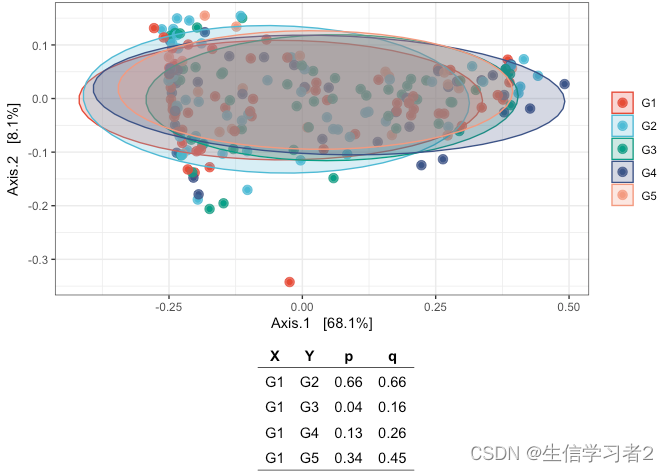
fig_beta_species_secondary <- plot_ordination(
species_rarefied,
mds, color = "group2") +
geom_point(size = 3, alpha = 0.8) +
stat_ellipse(geom = "polygon", type = "t", level = 0.8,
aes(fill = group2), alpha = 0.25) +
scale_color_npg(name = NULL, labels = c("G1", "G2", "G3", "G4", "G5")) +
scale_fill_npg(name = NULL, labels = c("G1", "G2", "G3", "G4", "G5")) +
theme_bw()
# P-values
groups <- meta(species_rarefied)$group2
set.seed(123)
stat_test <- pairwise.perm.manova(resp = dis, fact = groups, nperm = 999, p.method = "none")
df_p <- data.frame(X = rep("G1", 4),
Y = c("G2", "G3", "G4", "G5"),
p = round(stat_test$p.value[, "g1"], 2),
q = round(p.adjust(stat_test$p.value[, "g1"], method = "BH"), 2))
tab_beta_species_secondary <- ggtexttable(df_p, rows = NULL, theme = ttheme("light"))
p <- ggarrange(
fig_beta_species_secondary, tab_beta_species_secondary,
ncol = 1, nrow = 2, heights = c(1, 0.4))
p
















 1900
1900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











