







论文:Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
⭐⭐⭐
Google Research, ICLR 2023
论文速读
Chain-of-Thought(CoT) prompting 的方法通过结合 few-show prompt 的思路,让 LLM 能够挑战更具复杂性的问题。但是 CoT 的方法存在一个关键限制:它在需要泛化性来解决比 demonstration examples 更困难的问题的 task 上,通常表现不佳。
为了克服这个缺点,本论文提出了 least-to-most prompting 的方法,它先让 LLM 将原来的问题分解为多个需要预先解决的 sub-questions,然后依次按顺序让 LLM 去解决这些 sub-questions,在解决每个 sub-question 的时候,LLM 可以看到之前的每个 sub-question 以及回复。如下图:
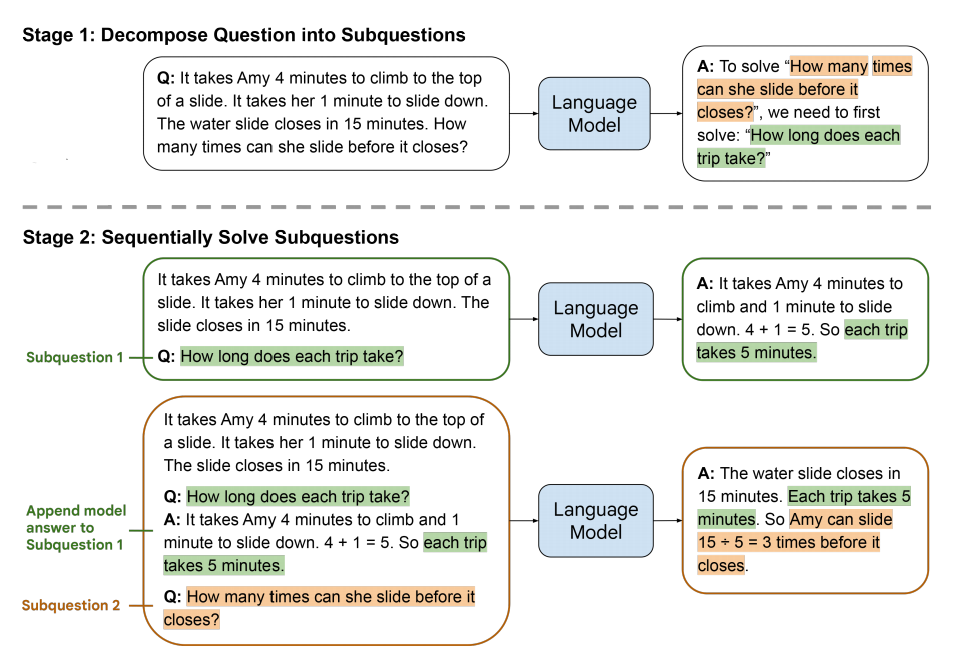
可以看到,它包含两个 stage,每个 stage 都是通过 few-shot prompt 来实现的,并且整个过程没有任何 model 被训练:
- Decomposition:这个阶段的 prompt 包含固定的几个用于演示 decomposition 的 few-shot exemplars,然后跟着需要被 decomposed 的 question
- Subproblem solving:这个阶段的 prompt 包含三个部分:
- 固定的几个用于演示 subproblem 如何被解决的 few-shot exemplars
- 先前已经被 LLM 回答了的 subquestions 以及对应的生成的回答
- 接下来需要被回答的 question
最终,原先的 user question 作为最后一个 subquestion 被 LLM 解决。
实验
论文做了 symbolic manipulation、compositional generalization 和 math reasoning tasks 三个实验,并主要与 CoT 进行了对比。
总的来说,本文提出的 Least-to-Most Prompting 相比于 CoT 的优势主要在于:
- 在长度泛化方面更好。面对比 few-shot exemplars 更长的问题,比 CoT 解决地更好
- 在困难泛化方面更好。面对比 few-shot exemplars 更困难的问题,也比 CoT 解决地更好
总结与分析
论文指出,该方法的 decomposition prompt 不能很好地跨域泛化,在一个 domain 上 decomposition 的示例无法有效地用在另一个 domain(task)上。
总的来说,本工作提出了 least-to-most prompting 的方法,通过自顶向下的问题分解和自底向上的子问题解决实现了最终的解决问题。在该方法中,prompt 由以前的单向与 LLM 交流变成了双向的互动。通过双向交互来指导 LLM 仍然值得探索。
pt 由以前的单向与 LLM 交流变成了双向的互动。通过双向交互来指导 LLM 仍然值得探索。















 891
891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









