







前言:这系列笔记,距离上一次更新间隔三个多月了,有点久了。生活艰难,没办法。这节课,主要是介绍动态物体跟踪方面知识;个人能力不足,有些地方可能理解有误,希望大神莫笑+赐教。有小伙伴觉得我写的还可以,有所获的话,麻烦一键三连哈。
概要
1、跟踪算法简介
2、单目标跟踪算法
3、多目标跟踪算法
4、实战,基于二分图匹配的多目标跟踪算法
1、跟踪算法简介
1.1Tracking跟踪
1)定义:在连续帧中【可理解为一段视频】,根据物体信息关联(确定)同一物体
1-1)运动模型(motion model):根据历史的位置和速度(大小和方向)建立模型,预测当前帧中物体的大致位置
1-2)外观(appearance model):根据历史外观(颜色、尺寸、2d/3d框、轮廓等)建立特征模型,在预测位置附近进行搜索,得到更准确的位置信息。如果物体的样貌基本没有变化,可以使用模板【模板,如在前一帧取物体一块区域A跟当前帧(物体样貌区域)作比较(基本没有变化),区域A可视为模板】。
但是,现实中物体往往很复杂,所以,一般使用一个在线学习的分类器(用“物体框”“背景框”进行二分类训练)。
难点:离线训练可以收集很多样本,在线学习样本非常有限,如何解决这个问题呢?
2)online:根据物体的历史信息(位置、颜色、形状等)找到当前帧中的位置(单目标跟踪的常见模式)
3)offline:根据每一帧中每个物体的信息在整个时间序列上关联得到的轨迹(多目标追踪/统筹考虑)【统筹考虑,指的是前面一帧信息,在后面也是可以使用的,而在线online就不行了】
1.2 跟踪独特之处(相比检测,存在意义)
1)跟踪保持ID一致
2)跟踪辅助检测:检测失败时(例如检测时被其他物体遮挡/有些物体可能无法被检测器检测【训练集上不存在该物体信息,就无法检测了】),有些追踪可以处理
3)跟踪比检测更快:检测没有利用历史信息,每一次都是从0开始。而跟踪可以提前知道跟踪物体的“历史”信息,基于这些信息可以大致预测下一帧的位置,在附近做小幅搜索匹配得到最终预测框
4)但是也不能只有跟踪而不用检测:
4-1)检测辅助跟踪:跟踪可能会跟丢(若碰到遮挡、运动模型模糊等情况)
4-2)检测纠正跟踪的累计误差:一般间隔执行检测,检测中执行跟踪,每隔一段时间用检测来重新纠正跟踪
5)总结:检测使用大规模样本数据训练出来的,它对某一类别理解更深刻,跟踪对某一个具体物体理解更深刻
1.3跟踪算法的难点
1)姿态形状变化,如人的坐、站、走路等等
2)尺度变化
3)背景遮挡
4)光线亮度变化
5)等等
2、单目标跟踪算法
2.1简介
2.1.1 单目标跟踪
流程:
1)第一帧【手动输入或者检测器自动生成】输入初始框–>后续帧输出该物体的位置
2)单个目标
3)online:实时
2.1.2 典型单目标跟踪算法种类
1)产生式模型:
经典目标跟踪方法(2010年之前):Meanshift、Paricle Filter、Kalman Filter、基于特征点光流跟踪(无法处理和适应复杂的跟踪变化,鲁棒性和准确度都被前沿的算法所超越)
2)鉴别式模型:
检测与跟踪算法结合的方法:BOOSTING、MIL、MEDIANFLOW、TLD(2010年之后)
3)基于相关滤波的跟踪算法【也属于鉴别式模型里面的,但是这个很优秀,并且形成体系很大,所以单独列出来说;也是本课重点】:
MOSSE KCF(2012)
4)基于深度学习的追踪方法【学术界做的多,但是工业界不多,所以本节课不会怎么涉及】:
GOTURN….
2.1.3 数据集
VOT、OTB【这两个属于很常用的】、…
2.2 产生式模型
2.2.1 Meanshift/光流
1)Meanshift:
1-1)对目标建模(比如利用目标的颜色分布来描述目标,计算目标在下一帧图像上的概率分布)
1-2)目标的搜索一直沿着概率梯度上升的方向,迭代收敛到概率密度分布的局部峰值上【下一帧中找到该目标的原理】
1-3)适用于目标的色彩模型和背景差异比较大的情形,计算速度快
2)基于特征点的光流算法:
2-1)对目标进行建模:在目标上提取一些特征点(用特征点的集合来表征目标)
2-2)下一帧计算这些特征点的光流匹配点,统计得到目标的位置(稀疏光流法)
2-3)在跟踪的过程中,不断补充新得特征点,删除置信度不佳的特征点,以适应目标在运动中的形状变化
3)Kalman Filter
(卡尔曼滤波,重点。应用不仅在跟踪、定位【体现在状态估计】,也在传感器数据融合,都是应用很重要)
例子介绍:

3-1)小车的基本描述:
----小车在t时刻的状态:pt位置 vt速度
----小车在t时刻的控制量:司机踩油门或者刹车给车一个加速度ut(如果司机既没有踩油门也没有踩刹车,那么ut就是等于0.此时车就会做匀速直线运动)
3-2)运动状态方程:
----根据上一时刻t-1,小车的状态预测当前时刻t小车的状态
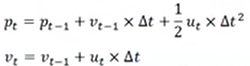
----公式中输出变量是输入变量的线性组合,线性关系可以用一个矩阵表示
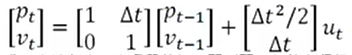
----进一步抽象出几个通用的概念更一般的方程描述:
--------状态转移矩阵A(表示我们如何从上一个状态来推测当前状态)
--------控制矩阵B(表示控制量u如何作用于当前状态)
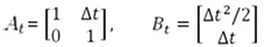
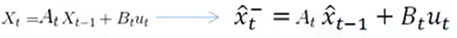
----X顶上的hat【右侧公式】表示其是估计值(而非真实值);【右侧公式】等式左端部分的右上标“-”,表示该状态推测而来的,后面,还将对其进行修正以得到最优估计,才可以将“-”去掉。【左侧公式,表示上一状态获取当前状态关系式,右侧是左侧的详细写法】
----可以描述所有线性关系的状态转移(X可以是维度等其他任何状态)
3-3)kalman filter(预测)
3-3-1)协方差
–对真实值进行估计,需要考虑噪声,通常假设噪声服均值为0的高斯分布 ,拓展到高维就是协方差 .
高斯分布:
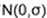
协方差:
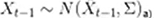
----系统中每一个时刻的不确定性都是通过协方差矩阵∑来给出的,这种不确定性在每个时刻间也会进行传递,也就是说不仅当前物体的状态(例如位置或者速度)会进行传递,而且物体状态的不确定性也是会(在每个时刻间)进行传递的
----另外,预测模型本身也并不是绝对准确,需要引入一个
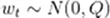
表示预测模型本身的噪声(也就是噪声在传递过程中的不确定性)
----根据概率论知识【上面的所陈述的,可以获取得到下面的协方差变换】:
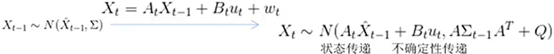
3-4)kalman filter(更新)
3-4-1)观测方程:
----真实状态我们其实是无法得知的,只是通过观测值进行估计,假设路边布置了速度显示器实时显示车辆的速度
----举个例子:t时刻小车的观测值为Zt,小车的真实状态到其观测状态还有一个变换关系h(*),这里假设它还是一个线性函数。同时考虑观测噪声为V_t,则有:
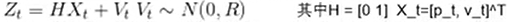
–注意:状态是二维量,观测是标量。 说明状态和观测的维度可以不同
–运动方程给出了一个估计值X_predict,观测方程也可以得到一个状态评估X_observation。是否把这两种估计融合一下,得到一个比他们俩都准确的估计呢?
–【回复上面的疑惑,融合两个估计值】卡尔曼滤波思想:Xupdate=Xpredict+g(Xabscrvation-Xpredict),0<=g<=1,g是根据两者的方差计算的g=E_predict/(E_predict+E_observation)。当X_predict方差为0时–> g=0【前面公式可以计算出的】 --> 完全相信X_predict;当X_observation方差为0时,g=1时完全相信X_observation
----卡尔曼滤波更新状态:
----Z_t-Hx_t是实际观测值与
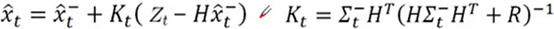
X有hat的截图公式,就是匹对卡尔曼思想的公式,每个参数有对应的部分,后面的解析也就是针对此截图公式进行解析的。
----K称为卡尔曼系数/卡尔曼增益,它有两个作用:
------将残差从观测域映射到状态域
------承担g的作用:在两种状态估计之间根据两者方差折中
----卡尔曼滤波更新不确定性:
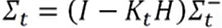
3-5)kalman filter(预测&更新)
总结:
预测:根据前一个状态来估计当前状态
更新:根据观测信息对预测信息进行修正,以达到最优估计
常被用于描述目标的运动模型,它不对目标的特征建模,而是对目标的运动模型进行建模,常用估计目标在下一帧的位置

【个人感觉,卡尔曼滤波,就是在观测值和预测值之间,如何选取权重计算,为的是取得融合后的信息最佳。】
3-6)实战:kalman filter
(opencv里面集成了kalman filter)

截图中,红色表示的是式子中参数对应量
代码来源:https://github.com/andylei77/kalman_particle_demo/blob/master/circle_tracker.cpp
- Paricle Filter(粒子滤波)
打比喻方式理解这个算法思想:
----放一群警犬取搜寻犯人
Step1:让狗熟悉犯人的气味:对目标建模(例如颜色直方图)得到目标特征表达
Step2:均匀分布几只狗的初始位置(开始时不知道犯人的大概位置),让他们通过附近的气味判断是否有犯人的足迹: 按照均匀分布撒下一些“粒子”,提取“粒子”附近的特征,通过某种相似性度量,确定“粒子”与目标的匹配程度
Step3:有些狗发现了犯人的足迹,有些没有发现。那就把没有发现足迹的那些狗放置到发现足迹的位置附近,继续进行搜索。按照高斯分布在可疑点附近撒下更多粒子,提取特征,判断与目标的匹配度。确保更大概率跟踪上目标。
Step4:重复step3
2.3 鉴别式模型
2.3.1 基本形式
1)运动模型:一般在上一帧位置附近生成几个候选框
2)外观模型:利用分类器计算候选框得分(“物体”或者“背景”),判断候选框是否是预测位置
3)跟检测的思路几乎一样(候选框+分类)
4)鉴别式跟踪方法更适应跟踪过程中的复杂变化,利用检测来做跟踪(Tracking by detection)逐渐成为主流
2.3.2 一些算法的基本介绍(非重点)
运动模型:一般在上一帧位置附近生成几个候选框
1)BOOSTING:
----运动模型同一般(就是上面介绍那种)
----外观模型:online版本的AdaBoost,正样本:初始框 ;负样本:正样本之外的许多图片块
----原理:在新图像中“之前框位置”附近的每一个位置计算分类得分。取分最高的作为新的位置。新位置框再次作为新样本训练分类器(每一帧都如此)
----特点:算法比较老,效果一般,跟踪失败不可知
2)MIL:
----运动模型同一般
----外观模型:改进正样本框:
物体框+框周围的小区域生成的框
大多数正样本框内物体不居中(包括新位置框),正负样本包(“bags”)只需要正样本包里有一个居中的正样本即可
----原理:在新图像中“之前框位置”附近的每一个位置计算分类得分。取得分最高的作为新位置。新位置+周围生成的框再次作为正样本训练分类器(每一帧都如此)
----特点:效果很好,部分遮挡的情况下表现也不错,相比BOOSTING偏移没有那么大,跟踪失败不可知,全遮挡不行
3)MEDIANFLOW:
----原理:前后向都进行跟踪,最小化两段轨迹的误差
----特点:可靠的反馈跟踪丢失,可靠的轨迹,适用于小幅运动运动无遮挡场景,大幅运动容易跟踪失败
4)TLD:
----原理:
------跟踪器:帧间跟踪物体,用经典的方法跟踪目标,论文中采用基于光流的特征点统计方法确定目标在下一帧的跟踪位置
------检测器:检测所有出现过的物体,并与跟踪结果综合得到最终的输出结果
------学习器:评估检测器的错误并更新检测器防止再次出现类似错误。确定目标的最佳位置后,学习模块(Learning)负责对跟踪器和检测器进行修正(在目标的周围选取更多的正负样本,在线更新检测器的模型)
----特点:适用于尺度变化较大的物体,运动物体,多帧被挡柱,遮挡较多(例如被另外一个物元完全挡住),过多错误的正样本导致它几乎不可用(容易跟踪非目标物体)
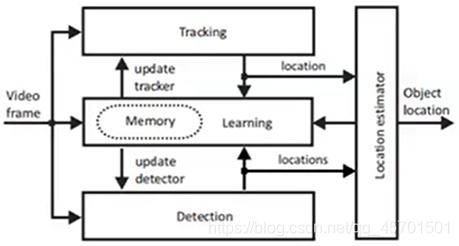
图中tracking为跟踪器;detection为检测器;learning为学习器;融合输出结果也可以返回来给学习器学习的,当然,也可以给跟踪器以及检测器更新的。
5)实战:上述几种常见集成在Opencv里面的tracking算法:
–opencv API
–code: https://github.com/andylei77/learnopencv/tree/master/tracking
2.4 基于相关滤波的跟踪算法
2.4.1基础知识
1)2012年P.Martins提出的CSK方法,从数学上完美解决密集采样与分类器的学习问题
----密集采样的过程可以通过循环矩阵来实现
----分类器的学习过程可以用快速傅里叶变换转化为频域内的计算,不受SVM或Boost等学习方法的限制。无论是用线性分类还是核分类,整个学习过程十分高效
2)优点:实时性
3)缺点:目标的快速移动,形状变化大导致更多背景被学习进来等都会对CF系列方法造成影响
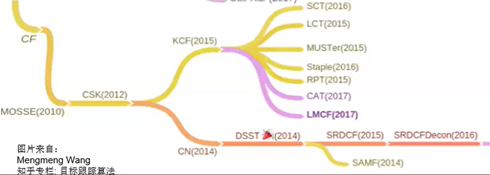

2.4.2 典型代表
2.4.2.1 MOSSE
1)MOSSE(Minimun Output Sum of Squared Error)
----外观模型:adaptive correlation for object tracking which produces stable correlation filters(引入CF:一种可学习的相似性度量)
2)特点:
–关照、尺度、姿态、非刚性变形,鲁棒性表现很好
–可以检测遮挡(peak-to-sidelobe radio)暂停并恢复跟踪
–高帧率(450fps)
–容易实现,但是精度和复杂度的跟踪算法不多【跟普通的相比,精度和复杂度效果差不多意思,个人理解】
–效果不如基于深度学习的方法
2.4.2.1 KCF
1)KCF(Kernlized Correlation Filters)
----外观模型:利用多个正样本间的重叠关系【循环矩阵采样】同时提升跟踪的速度和精度:
------新位置及其周围产生的正样本可以通过循环矩阵快速生成
------循环矩阵傅里叶对角化性质大大简化计算加速分类器的学习过程
------基于HOG特征的分类器,(DeepSRDCF:深度学习提取的特征+KCF的方法)
2)特点:精度速度都比MIL高,反馈跟踪失败比BOOSTING 和MIL好,无法解决全遮挡情况

该图表示的是,使用循环矩【矩阵不一样,得到的图片不一样,如图中骑车人在图片中位置变化】阵采样的效果对比
2.5(单目标)基于深度学习的跟踪算法
2.5.1 GOTURN
1)其是一种基于深度学习的端到端方法
2)原理:卷积神经网络
3)特点:对视角变化、光照变化、形状变化的鲁棒性都挺好。不过,无法有效处理遮挡情况
4)参考:https://www.learnopencv.com/goturn-deep-learning-based-object-tracking/
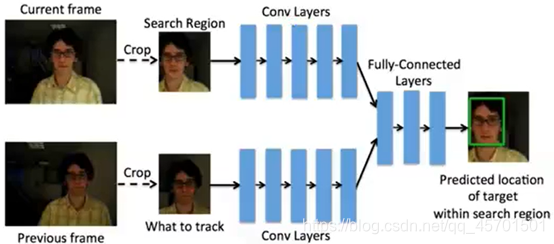
当前和前一帧,各个抠出一个区域框来,输入网络里面,直接输出一个预测框,不需要进行其他任何处理。

图中,深度学习是CNN往左走;CSK往右走属于相关滤波的
3、多目标跟踪算法
3.1 简介
1)单目标–>多目标 :既有单目标的难点又增加了多目标自身的难点
2)分类方法:
–按照轨迹形成的时间顺序:
----在线:逐帧,类似人眼跟踪目标,获得每帧图像的检测结果,把检测结果和已有的跟踪轨迹进行关联
----离线:跟踪算法运行是在视频已经获取结果,所有检测结果都已经提前获取。离线多目标跟踪算法把检测结果集合作为观察,把轨迹看作检测集合的一种划分,因此跟踪问题转化为子集优化的过程
–按照算法机制:预测校正/关联方式【比如每一帧都有检测结果了,只需要把结果和图片关联起来】
–按照算法的数学表示:概率统计最大化/确定性推导
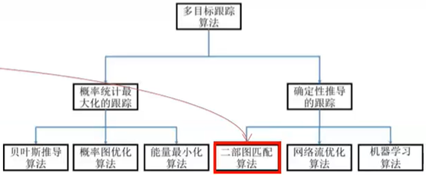
【红箭头另一头是上一行的“确定性推导”】
参考文献:
–视觉多目标跟踪算法综述(上)
–多目标跟踪综述
–深度多目标跟踪算法综述
3.2 Huangarian Algorithm(匈牙利算法)
1)二分图匹配是很常见的算法问题,一般用匈牙利算法解决二分图最大匹配问题
2)什么是二分图?
----二分图,又称作二部图,是图论中一种特殊的模型。设G=(V,E)是一个无向图【V表示顶点集;E,表示边】,如何使得顶点集V可分割为两个互不相交的子集(A,B),并且图中的每条边E(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图
3)什么是匹配?
–把下图想象成3位工人和4种工作,连线代表工人愿意从事某项工作,但最终一个工人只能做一种工作,最终的匹对结果连线就是一个匹配。匹配可以是空。对应到跟踪任务中就是运动轨迹与当前帧内物体的匹配
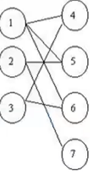
如图3个轨迹在左侧,然后现在有4个物体在右侧,将轨迹跟物体关联起来,就是匹配。
4)什么是最大匹配?
–在愿意从事工作的基础上,能够最多配成几队
参考:趣写算法系列之—匈牙利算法(https://blog.csdn.net/dark_scope/article/details/8880547)
“腾”:有机会上,没机会创造机会也要上。
Code:https://github.com/andylei77/HungarianAlgorithm/blob/master/hungarian_algorithm.py
匈牙利算法精髓:递归时,先到先得,后面有不满足的,能让则让,还有不满足的,将就一下跟剩下的匹配。
4、实战,基于二分图匹配的多目标跟踪算法
Code:https://github.com/andylei77/object-detector/blob/ROS/object_detection_tutorial.py
(appllo跟踪算法的实现)案例效果,给每一帧图片中的物体动态画框,并可以动态跟踪画框。
简单理解(个人认为):
1)首先,给各帧图片的物体画框,给id操作,这是一个部分A;然后,根据相关算法(具体不清楚)得到很多轨迹,命名位部分B。里面匈牙利算法,将A中的物体跟B中的轨迹关联起来。其中,本案例的核心点在于,匈牙利算法的匹配功能。
匈牙利算法实现轨迹和物体匹配时,使用了打分机制,打分机制有:
----Cs2d:根据形状打分(结合中心点和框尺度。相对于前一帧,中心点偏移不大,框大小变化不大,那么,得分就比较高)
----Dlf: 利用深度学习特性进行打分
----Kcf: 前一帧和后一帧各自框,都利用kcf学习到各自特征,利用相关滤波打分
老师的答疑环节给的一些看法:
1)无人车采用的是多目标跟踪算法;
2)能够理解代码已经很牛了
3)二分图考虑的滑窗很小,而且只是考虑当前帧和前一帧情况,也属于比较适合无人驾驶情景使用的(计算资源不需要很大)
4)滤波方法属于比较经济实用的,无人机领域就很常用;
5)基于二分图的跟踪算法,相比较深度学习来说,比较轻量级,计算量比较小
个人小结:本节课介绍了跟踪算法知识。从单目标跟踪走起,介绍基本知识,然后根据几大类型进行做常见算法介绍,不过这次少了很多文献这些,挺好的。然后,特点介绍了kalman filter。哈哈哈,一开始我以为这是一种滤波器,去降噪的,原来是一种信息融合的思想,其特别适用于状态估计。跟踪算法里面,特别重点介绍了二分图以及轨迹与物体匹配时所使用的匈牙利算法。跟踪算法,就是在前后帧中,划分框,然后判断出是否时同一个物体,然后就轨迹和物体匹配问题。其实,很复杂这里面,很迷现在。总之,本课重点是,kalman filter、匹配使用的匈牙利算法,以及基于二分图匹配的多目标跟踪算法。看见老师,随手拿案例里面的函数出来,解析其内部的含义,太强大了。希望自己有一天也能有这么强大。
#####################
不积硅步,无以至千里
好记性不如烂笔头
图片版权归原作者所有
感恩授课老师的付出
觉得看了有收获的话,麻烦大大们点赞哈

















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









