






前言
上一个文章我们大概讲述了deepsort的源码和原理,接下来我们来研究botsort和strongsort的内容。
什么是MOT?
多目标跟踪(Multiple Object Tracking)
MOT 获取单个连续视频并以特定帧速率 (fps) 将其拆分为离散帧以输出。
-
检测每帧中存在哪些对象
-
标注对象在每一帧中的位置
-
关联不同帧中的对象是属于同一个对象还是属于不同对象
一.BoT-SORT
论文地址:
https://arxiv.org/pdf/2206.14651.pdf
论文秉承着一贯风格以 Tracking-by-detection 作为MOT任务,使用最先进的检测器YOLOX作为检测任务,在ByteTrack的基础上更新很多作者自己的想法。
什么是 ByteTrack
ByteTrack算法是一种基于目标检测的追踪算法,和其他非ReID的算法一样,仅仅使用目标追踪所得到的bbox进行追踪。追踪算法使用了卡尔曼滤波预测边界框,然后使用匈牙利算法进行目标和轨迹间的匹配。
ByteTrack算法的最大创新点就是对低分框的使用,作者认为低分框可能是对物体遮挡时产生的框,直接对低分框抛弃会影响性能,所以作者使用低分框对追踪算法进行了二次匹配,有效优化了追踪过程中因为遮挡造成换id的问题。
特点:
1)没有使用ReID特征计算外观相似度
2)非深度方法,不需要训练
3)利用高分框和低分框之间的区别和匹配,有效解决遮挡问题
1.修改卡尔曼滤波(KF)中的状态向量及其他矩阵参数。
起初SORT中KF状态向量为7元组组成: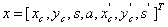 ,其中x,y为中心值,s为边界框比例(面积),a为边界框的纵横比(w/h)。
,其中x,y为中心值,s为边界框比例(面积),a为边界框的纵横比(w/h)。
注:目标检测边界框比例通常指的是边界框的面积与图像总面积之间的比例关系。在目标检测任务中,边界框的面积可以用来衡量目标物体在图像中所占的相对大小。边界框比例可以帮助我们理解目标物体的尺度特征。例如,一个较大的目标物体可能会有较大的边界框面积,而一个较小的目标物体则会有较小的边界框面积。通过边界框比例,我们可以推断目标物体的尺度大小,从而更好地进行目标检测和识别。
而DeepSort中KF状态向量改为8元组: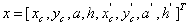 ,a依然为边界框的纵横比,只是将第四维改成的边界框的高度h预测。
,a依然为边界框的纵横比,只是将第四维改成的边界框的高度h预测。
注:目标检测边界框的纵横比是指边界框的宽度与高度之间的比例关系。在目标检测任务中,边界框用于标识和定位图像中的目标物体。纵横比可以帮助我们理解目标的形状特征。例如,一个正方形的边界框纵横比为1:1,表示宽度和高度相等;而一个长方形的边界框纵横比可能为2:1,表示宽度是高度的两倍。通过纵横比,我们可以推断目标物体的形状特征,从而更好地进行目标检测和识别。
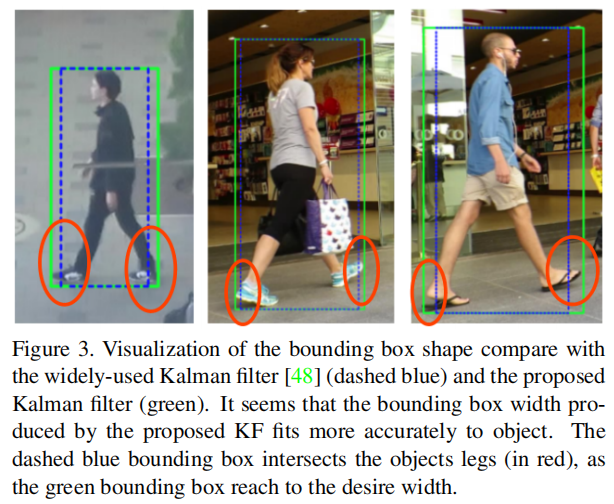
论文中修改KF状态向量为如下形式: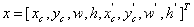 ,将宽高比改成了预测宽度w,是因为作者发现在真实预测的过程中预测框总是不将行人完全包括进去,而正确的预测宽高能更好的匹配行人框,对跟踪匹配中的IOU也有很大的改善。
,将宽高比改成了预测宽度w,是因为作者发现在真实预测的过程中预测框总是不将行人完全包括进去,而正确的预测宽高能更好的匹配行人框,对跟踪匹配中的IOU也有很大的改善。
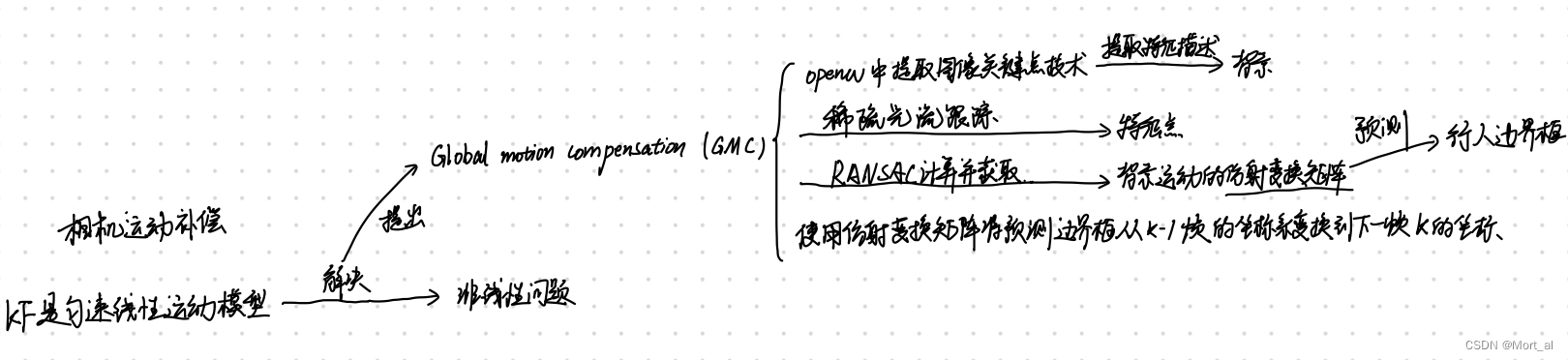
2.相机运动补偿Camera Motion Compensation (CMC)
由于KF是匀速线性运动模型,对于跟踪非线性来说会产生不适配的问题,作者使用OpenCV的全局运动估计 (GMC) 技术来表示背景运动。首先提取图像关键点,然后利用稀疏光流进行基于平移的局部异常点抑制的特征跟踪。这里先使用RANSAC计算出仿射变换矩阵 。然后使用仿射变换矩阵将预测边界框从k-1帧的坐标系变换到下一帧k的坐标。
仿射变换矩阵的平移部分只影响边界框的中心位置,而另一部分影响所有的状态向量和噪声矩阵。
使用FastReID库中ResNest50作为backbone,BoT(SBS)作为基线训练reid网络,网络训练使用默认的参数,从FastReID项目中可以找到,使用的分辨率为128x384的输入分辨率,损失函数使用了经典的TripletLoss,总共迭代60个epoch训练出强有力的ReID网络提取特征。并且采用指数移动平均(EMA)来更新第k帧中第i个预测框的轨迹状态,在拥挤以及遮挡的场景中检测得分低的表示特征不可靠,并不会用来做特征匹配。
并且有提出使用IOU+ReID融合机制的策略来进行匹配。
其余关于botsort的内容大家可以看这篇文章参考文章。
二.strongsort
论文地址:https://arxiv.org/abs/2202.13514
代码地址 :https://github.com/dyhBUPT/StrongSORT
tracking-by-detection检测跟踪
joint-detection-association联合检测关联范式
下面我将通过读论文的形式对strongsort过一遍
1.论文摘要
现有的多目标跟踪 (MOT) 方法可以大致分为检测跟踪和联合检测关联范式。尽管后者引起了更多的关注,并显示出相对于前者的可比性能,但我们声称,就跟踪精度而言,跟踪检测范式仍然是最佳解决方案。在本文中,我们重新审视了经典的跟踪器DeepSORT,并从各个方面对其进行了升级,即检测,嵌入和关联。生成的跟踪器称为StrongSORT,在MOT17和MOT20上实现了新的HOTA和IDF1。我们还提出了两种轻量级和即插即用算法,以进一步完善跟踪结果。首先,提出了一种无外观链接模型 (AFLink),将短轨迹关联到完整的轨迹中。据我们所知,这是第一个没有外观信息的全局链接模型。其次,我们提出了高斯平滑插值 (GSI) 来补偿缺失的检测。GSI不再像线性插值那样忽略运动信息,而是基于高斯过程回归算法,并且可以实现更精确的定位。此外,AFLink和GSI可以以可忽略的额外计算成本 (在MOT17上分别为591.9和140.9Hz) 插入到各种跟踪器中。通过将StrongSORT与两种算法集成在一起,最终地跟踪器StrongSORT在HOTA和IDF1指标方面在MOT17和MOT20上排名第一,并以1.3-2.2的优势超过第二名。代码将很快发布。
进一步理解
多目标跟踪(MOT)在视频理解中起着至关重要的作用。它旨在逐帧检测和跟踪所有特定类别的对象。在过去的几年里,tracking-by-detection范式[3,4,36,62,69]主导了多目标跟踪的任务。它 对每一帧进行检测并且将MOT转换为一个数据关联任务。受益于高性能的目标检测模型,tracking-by-detection方法由于它们出色的表现而受到青睐。然而,SDE系列(tracking-by-detection)算法需要多个计算昂贵的组件:比如一个检测器和一个embedding模型。而特征共享系列算法[1,60,74]通过联合检测和嵌入模型训练,获得了更好的跟踪性能。
联合检测器的成功促进了研究人员设计各种组件统一的跟踪网络框架,如运动,检测,嵌入和关联等[30, 32, 38, 57, 59, 65, 68]。然而,作者认为这些联合框架中存在两个问题:(1)不同组件之间的竞争和(2)用于联合训练这些组件的数据有限。尽管已经有一些方法被提出来解决上述两个问题,这些问题的存在还是降低了跟踪准确率的下限。相反,SDE系列的跟踪器似乎被低估了。
本文作者回顾了经典的独立跟踪器deepsort[62],它是最早将深度学习模型用于多目标跟踪任务的方法之一。作者任务DeepSORT不如当前最先进的方法是因为它的技术过世了,而不是它的跟踪范式。作者通过在多个方面为DeepSORT配备先进的组件,产生了StrongSORT,该模型在MO17和MOT20上能达到新的SOTA。
作者还提出了两个轻量级的即插即用的与模型、外观无关的算法来完善跟踪结果。第一,为了更好地利用全局信息,一些方法[12,39,55,56,67]提出通过使用一个全局连接模型将短轨迹和轨迹相关联。它们通常生成准确的但是不完成的轨迹段并且使用全局信息通过离线的方式关联它们。尽管这些方法很好地提升了跟踪表现,但是他们都依赖于一个计算密集型的模型,特别是外观嵌入。相反,我们提出了一种与外观无关的连接模型AFLink,它只利用时空信息来预测两个轨迹段是否属于同一个ID。第二,线性插值法被广泛应用于弥补漏检情况。然而,它忽略了运动信息,这限制了插值位置的准确率。为了解决这个问题,我们提出了高斯平滑插值算法GSI,通过使用高斯过程回归算法增强插值效果。
扩展实验证明这两种方法对StrongSORT以及其他最先进检测器的可观的提升,比如CenterTrack,TransTrack和FairMot。特别地是,通过将AFLink和GSI应用于StrongSORT,产生了StrongSORT++。
2.引言
多目标跟踪在视频理解中起着至关重要的作用。它的目标是逐帧检测和跟踪所有特定类别的对象。在过去的几年里,通过检测进行跟踪的范例主导了MOT任务。它执行每帧检测,并将MOT问题描述为数据关联任务。得益于高性能的目标检测模型,基于检测的跟踪方法因其出色的性能而受到青睐。然而,这些方法通常需要多个计算组件,比如一个嵌入模型和一个检测器。为了解决这个问题,最近的几种方法将检测器和嵌入模型集成到一个统一的框架中。此外,与单独的检测和嵌入训练相比,联合检测和嵌入训练似乎产生了更好的结果。因此,这些方法(联合跟踪器)与检测跟踪方法(单独跟踪器)相比,可获得相当甚至更好地跟踪精度。
联合跟踪器的成功促使研究人员为各种组件(例如,检测、运动、嵌入和关联模型)设计统一的跟踪框架 。然而,我们认为在这些联合框架中存在两个问题:
(1) 不同组件之间的竞争
(2) 用于联合训练这些组件的有限数据。
虽然已经提出了多种策略来解决这些问题,但这些问题仍然降低了跟踪精度的上限。相反,单独地追踪器的潜力似乎被低估了。
在本文中,我们重新审视了经典的单独跟踪器DeepSORT,这是最早将深度学习模型应用于MOT任务的方法之一。据称,与最先进的方法相比,DeepSORT的表现不佳是因为它过时的技术,而不是它的跟踪范式。我们表明,通过简单地为DeepSORT配备各方面的高级组件,从而产生了StrongSORT,它可以在流行的基准MOT17和MOT20上实现新的SOTA。
我们还提出了两种轻量级、即插即用、独立于模型、无外观的跟踪算法。首先,为了更好地利用全局信息,有几种方法提出使用全局链路模型将短轨迹关联到轨迹 。它们通常生成准确但不完整的轨迹,并以正常的方式将它们与全局信息关联起来。虽然这些方法显著提高了跟踪性能,但它们都依赖于计算密集型模型,尤其是外观嵌入。相比之下,我们提出了一种仅利用时空信息来预测两个输入轨迹是否属于同一ID的无外观链接模型(AFLink)。
其次,线性插值被广泛用于补偿缺失检测 。但是,它忽略了运动信息,这限制了插值位置的准确性。为了解决这个问题,我们提出了高斯平滑插值算法 (GSI),该算法通过使用高斯过程回归算法来增强插值 。
3.相关知识
SDE和JDE
SDE(Single-stage Detector with Embeddings)和JDE(Joint Detection and Embedding)是两种用于多目标跟踪(Multiple Object Tracking,简称MOT)的方法。这两种方法都试图在一个单一的模型中同时解决目标检测和目标关联问题。
1)JDE(Joint Detection and Embedding):JDE方法也是一种将目标检测和目标关联整合到一个单一网络中的方法。与SDE方法不同,JDE方法在网络设计上更加注重目标关联的学习。JDE方法通常采用多任务学习(Multi-task Learning)的策略,同时学习目标检测、目标关联和其他相关任务(如目标分类、目标分割等)的特征。但是,我们声称联合跟踪器面临两个主要问题: 不同组件之间的竞争以及用于联合训练组件的有限数据。这两个问题限制了跟踪精度的上限。
2) SDE(Single-stage Detector with Embeddings):SDE方法将目标检测和目标关联的特征学习整合到一个单一的网络中。这种方法通常采用类似于Faster R-CNN或YOLO的单阶段目标检测网络,并在网络中添加额外的分支来学习目标关联的特征。这些特征可以是外观特征、运动特征或其他有助于区分不同目标的信息。SDE方法的优点是计算效率高,但可能在处理复杂场景和目标遮挡时遇到困难。
MOT中的全局连接
在多目标跟踪(Multiple Object Tracking,简称MOT)任务中,全局连接(Global Association)是一种将目标在不同帧之间进行关联的方法。全局连接的目的是在整个视频序列中找到一种最佳的目标关联方式,从而获得稳定且准确的目标跟踪结果。
全局连接方法通常基于优化算法,例如最大权匹配(Maximum Weighted Matching)或最小成本流(Minimum Cost Flow)。这些算法考虑了目标之间的外观特征、运动特征和时空约束等信息,以在整个视频序列中找到最佳的目标关联方式。
与局部连接(Local Association)方法相比,全局连接方法可以更好地处理目标间的遮挡、交叉和长时间消失等问题。然而,全局连接方法的计算复杂度较高,可能需要较长的计算时间。因此,在实际应用中,根据具体需求和场景选择合适的目标关联方法是很重要的。
MOT中的插值
在多目标跟踪(Multiple Object Tracking,简称MOT)任务中,插值(Interpolation)是一种处理目标临时遮挡或检测失败的方法。插值的目的是在目标在连续帧之间的缺失区间内估计其状态,从而获得更稳定的跟踪结果。
插值方法通常基于运动模型或外观特征。以下是一些常用的插值方法:
-
线性插值(Linear Interpolation):基于目标的运动特征,使用线性函数来估计目标在缺失区间内的位置。这种方法简单且易于实现,但可能无法处理复杂的运动模式。
-
卡尔曼滤波(Kalman Filter):基于目标的运动状态(位置、速度等),使用卡尔曼滤波器来预测目标在缺失区间内的状态。卡尔曼滤波是一种更为复杂且鲁棒性较好的插值方法。
-
外观特征插值:基于目标的外观特征(如颜色、纹理等),使用相似性度量(如欧氏距离、余弦相似度等)来估计目标在缺失区间内的状态。这种方法可以处理目标形变和外观变化的情况。
插值方法可以帮助MOT系统在目标遮挡或检测失败的情况下保持稳定的跟踪结果。然而,插值方法的准确性受到运动模型和外观特征的影响。在实际应用中,选择合适的插值方法以及合适的运动模型和外观特征对于提高MOT系统的性能至关重要。
于是我们设计的两个插件AFLink和GSI。
AFLink
轨迹的全局关联用于多个算法中,以追求高度准确的关联。但是,它们通常依赖于计算上昂贵的组件和许多超参数来进行微调。例如,GIAOTracker [12] 中的链接算法利用改进的ResNet50-TP [16] 来提取轨迹3D特征并执行与额外的空间和时间距离的关联。这意味着要对6个超参数 (3个阈值和3个权重因子) 进行微调,这会导致额外的调谐实验和较差的鲁棒性。此外,我们发现过度依赖外观特征容易受到噪音的影响。为此,我们设计了一个无外观模型AFLink,仅依靠时空信息来预测两个轨道之间的连通性。
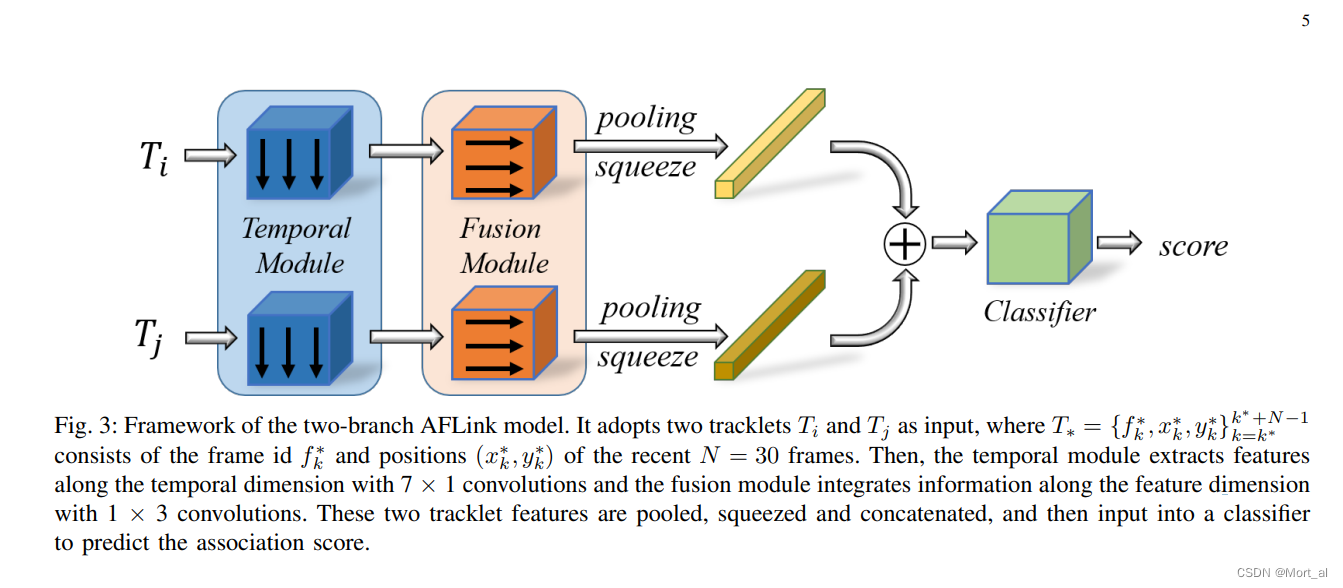
下图显示了 AFLink 模型的两分支框架。 它采用两个轨迹 和
作为输入,一个时间模块用于通过沿时间维度与 7×1 核进行卷积来提取特征。 然后,融合模块执行 1×3 卷积以整合来自不同特征维度的信息。 将生成的两个特征图分别池化并压缩为特征向量,然后进行连接,其中包含丰富的时空信息。 最后,MLP 用于预测关联的置信度分数。 注意两个分支的时间模块和融合模块没有绑定。
AFLink 模型由两个轨道的时空信息作为输入,然后预测他们的连通性。
GSI
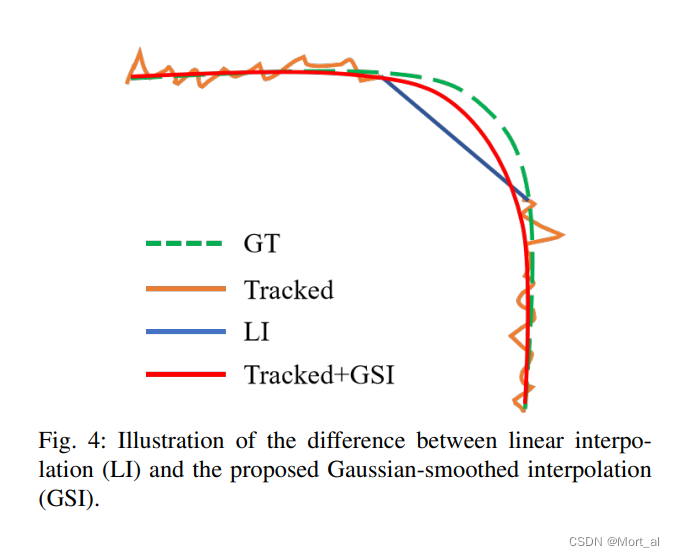
插值被广泛用于填补由于缺失检测而导致的轨迹空白。线性插值因其简单性而广受欢迎。然而,它的准确性是有限的,因为它不使用运动信息。尽管已经提出了几种策略来解决这个问题,但它们通常会引入额外的耗时模块,例如单目标跟踪器、卡尔曼滤波器、ECC。不同的是,我们提出了一种轻量级插值算法,该算法采用高斯过程回归来模拟非线性运动。
下图 举例说明了 GSI 和线性插值 (LI) 之间的差异。 原始跟踪结果(橙色)通常包括噪声抖动,LI线性插值(蓝色)忽略运动信息。 我们的 GSI(红色)通过使用自适应平滑因子平滑整个轨迹同时解决了这两个问题。
strongsort是作者在deepsort的基础上改进出来的,具体的改进方式可以看博客strongsort的读书笔记,我在这里因为研究的还不是很透彻就不详述了。

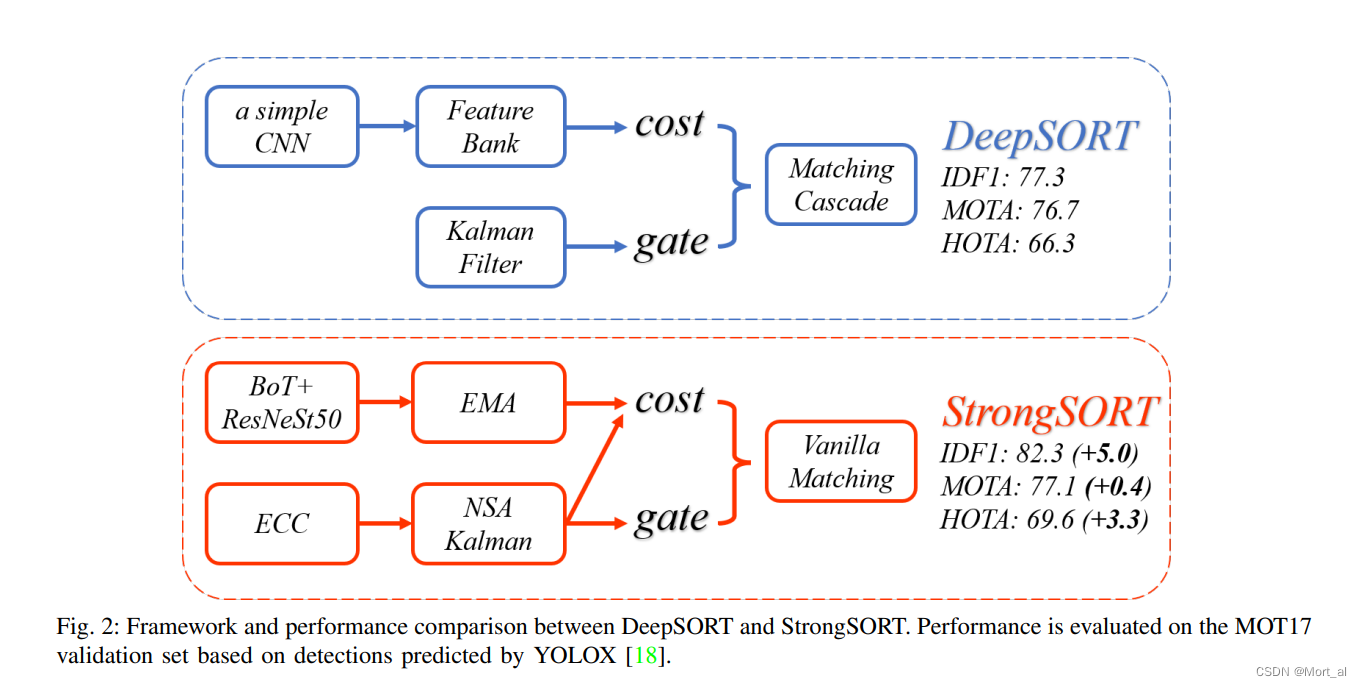
下面是论文中作者将deepsort和strongsort对比得出的图片。
谢谢收看!!代码后续补充。

















 2707
2707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









