







GPT-4 Technical Report
摘要
- 一个多模态的模型
- 接受图像和文本输入并产生文本输出
- 同样基于transformer预训练
官网链接
引言
- 生成更加多样化
- 可以接受图片和文字作为输入
- 生成更长的文本
虽然在许多现实世界场景中的能力不如人类,但在各种专业和学术基准上表现出人类水平的表现
能力
视觉输入

可操纵性
与具有固定冗长、语气和风格的经典 ChatGPT 个性不同,开发人员(以及很快的 ChatGPT 用户)现在可以通过在“系统”消息中描述这些方向来规定他们的 AI 的风格和任务。用户在一定范围内显着定制他们的用户体验。

限制
尽管功能强大,但 GPT-4 与早期的 GPT 模型具有相似的局限性。最重要的是,它仍然不完全可靠(它“幻觉”事实并出现推理错误)。在使用语言模型输出时应格外小心,特别是在高风险上下文中,使用符合特定用例需求的确切协议(例如人工审查、附加上下文的基础或完全避免高风险使用) .
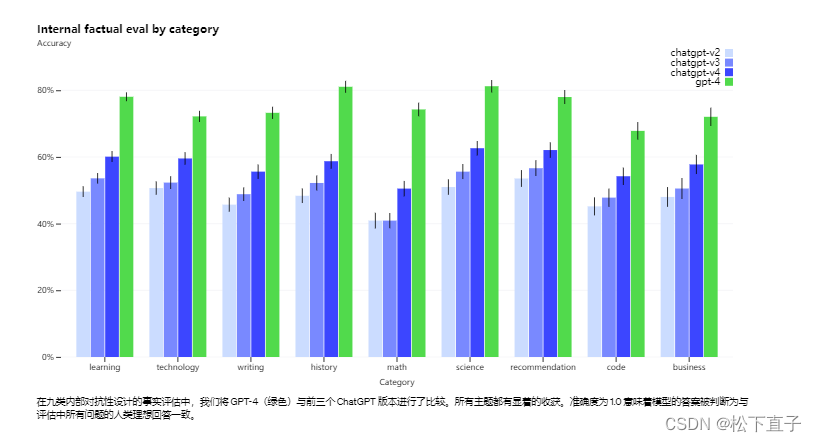
虽然仍然是一个真正的问题,但 GPT-4 相对于以前的模型(它们本身在每次迭代中都在改进)显着减少了幻觉。在我们的内部对抗性真实性评估中,GPT-4 的得分比我们最新的 GPT-3.5 高 40%:
风险和缓解措施
一直在对 GPT-4 进行迭代,以使其从训练开始就更安全、更一致,工作包括预训练数据的选择和过滤、评估和专家参与、模型安全改进以及监控和执行。
GPT-4 会带来与之前模型类似的风险,例如生成有害建议、错误代码或不准确信息。但是,GPT-4 的附加功能会带来新的风险面。为了了解这些风险的程度,我们聘请了 50 多位来自 AI 对齐风险、网络安全、生物风险、信任和安全以及国际安全等领域的专家来对模型进行对抗性测试。他们的发现特别使我们能够在需要专业知识进行评估的高风险领域测试模型行为。这些专家的反馈和数据用于我们对模型的缓解和改进;例如,我们收集了额外的数据来提高 GPT-4 拒绝有关如何合成危险化学品的请求的能力。
GPT-4 在 RLHF 训练期间加入了一个额外的安全奖励信号,通过训练模型拒绝对此类内容的请求来减少有害输出(如我们的使用指南所定义)。奖励由 GPT-4 零样本分类器提供,该分类器根据安全相关提示判断安全边界和完成方式。为了防止模型拒绝有效请求,我们从各种来源(例如,标记的生产数据、人类红队、模型生成的提示)收集了多样化的数据集,并在两者上应用安全奖励信号(具有正值或负值)允许和不允许的类别。
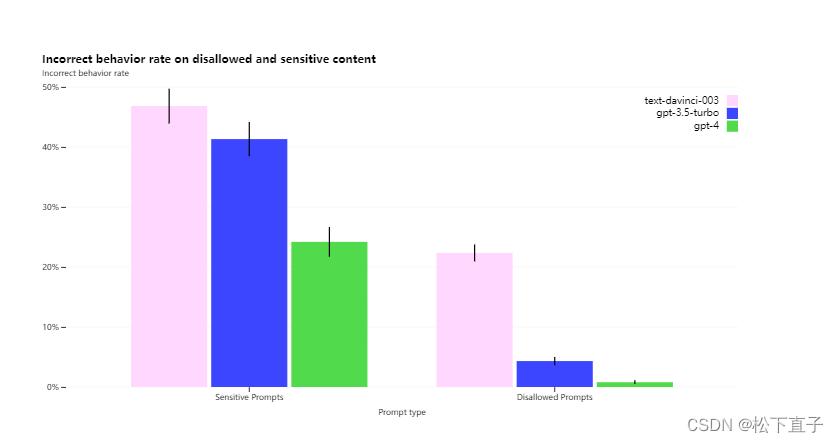
与 GPT-3.5 相比,我们的缓解措施显着改善了 GPT-4 的许多安全特性。与 GPT-3.5 相比,我们已将模型响应不允许内容请求的倾向降低了 82%,并且 GPT-4 根据我们的政策响应敏感请求(例如,医疗建议和自我伤害)的频率提高了 29% .
















 8901
8901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











