







文章目录
DeSTSeg: Segmentation Guided Denoising Student-Teacher for Anomaly Detection
摘要
视觉异常检测是计算机视觉中的一个重要问题,通常被定义为一类分类和分割任务。学生-教师(S-T)框架已被证明在解决这一挑战方面是有效的。然而,先前基于S-T的工作仅在经验上对正态数据和融合的多级信息应用了约束。
本文方法
- 提出了一种称为DeSTSeg的改进模型
- 将预先训练的教师网络、去噪的学生编码器-解码器和分割网络集成到一个框架中
- 为了加强对异常数据的约束,我们引入了一种去噪程序,使学生网络能够学习更稳健的表示
- 从综合损坏的正常图像中,训练学生网络在没有损坏的情况下匹配相同图像的教师网络特征
- 为了自适应地融合多级S-T特征,从合成异常掩码中训练了一个具有丰富监督的分割网络
本文方法

DeSTSeg概述。在训练期间生成并使用合成的异常图像。
(a)中,训练具有合成输入的学生网络,以从干净的图像生成与教师网络类似的特征表示。
(b)中,学生和教师网络的归一化输出的元素乘积被连接起来,并用于训练分割网络。分割输出是预测的异常得分图。
将合成异常引入到正常训练图像中,并分两步对模型进行训练。在第一步中,模拟的异常图像被用作学生网络的输入,而原始的干净图像被用作教师网络的输入。教师网络的权重是固定的,但用于去噪的学生网络是可训练的。在第二步中,学生模型也被固定。学生网络和教师网络都以合成的异常图像作为输入,以优化分割网络中的参数来定位异常区域。为了推断,以端到端模式生成像素级异常图,并且可以通过后处理来计算相应的图像级异常分数。
Synthetic Anomaly Generation
生成随机二维珀林噪声,并通过预设阈值进行二值化以获得异常掩模M。通过用无异常图像In和来自外部数据源a的任意图像的线性组合替换掩模区域来生成异常图像Ia,不透明度系数β在[0.15,1]之间随机选择。

Denoising Student-Teacher Network
在以前的多层次知识提取方法中,学生网络(正常图像)的输入与教师网络的输入相同,学生网络的架构也是如此。然而,我们提出的去噪学生网络和教师网络以成对的异常和正常图像作为输入,去噪学生网具有不同的编码器-编码器架构。
教师网络是在大型数据集上预先训练的,因此它可以在正常和异常区域生成判别特征表示。
学生网络不应复制教师网络的架构。考虑到重建早期层的特征的过程,众所周知,CNN的较低层捕获局部信息,如纹理和颜色。相反,CNN的上层表示全局语义信息。回想一下,我们的去噪学生网络应该从教师网络中重建相应正常图像的特征,这样的任务依赖于图像的全局语义信息,仅用几个较低的层是无法完美完成的。
教师网络是ImageNet预训练的ResNet18[14],其中移除了最终块(即conv5x)。从剩余的三个块,即分别表示为T1、T2和T3的conv2x、conv3x和conv4x中提取输出特征图。
去噪学生网络,编码器是随机初始化的ResNet18,具有所有块,分别命名为S1E、S2E、S3E和S4E。解码器是具有四个残差块(分别命名为S4D、S3D、S2D和S1D)的反向ResNet18(通过用双线性上采样代替所有下采样)。
损失函数:
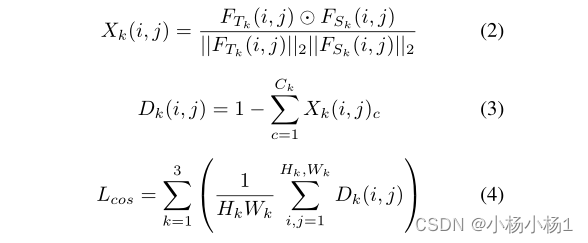
分割网络
分割网络包含两个残差块和一个Atrous Spatial Pyramid Pooling(ASPP)模块。不存在上采样或下采样;因此输出大小等于X1的大小。尽管这可能在一定程度上导致分辨率损失,但它降低了训练和推理的内存成本,这在实践中至关重要。
损失函数:

推理
在推理阶段,测试图像被输入教师和学生网络。分割预测最终被上采样到输入大小,并作为异常得分图。预计输入图像中的异常像素在输出中将具有更大的值。为了计算图像级异常分数,我们使用异常分数图中顶部T值的平均值,其中T是调整超参数。
实验结果




消融实验


















 699
699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











