




 VoxelNet是一种基于体素的深度学习方法,用于3D对象检测。它首先将点云数据体素化,然后通过点的特征增强和体素内的最大池化操作提取特征,形成体素的局部聚合特征,用于表征3D物体的表面形状信息。
VoxelNet是一种基于体素的深度学习方法,用于3D对象检测。它首先将点云数据体素化,然后通过点的特征增强和体素内的最大池化操作提取特征,形成体素的局部聚合特征,用于表征3D物体的表面形状信息。
VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
第二篇要说的论文是基于体素的VoxelNet,仅记录体素特征编码。
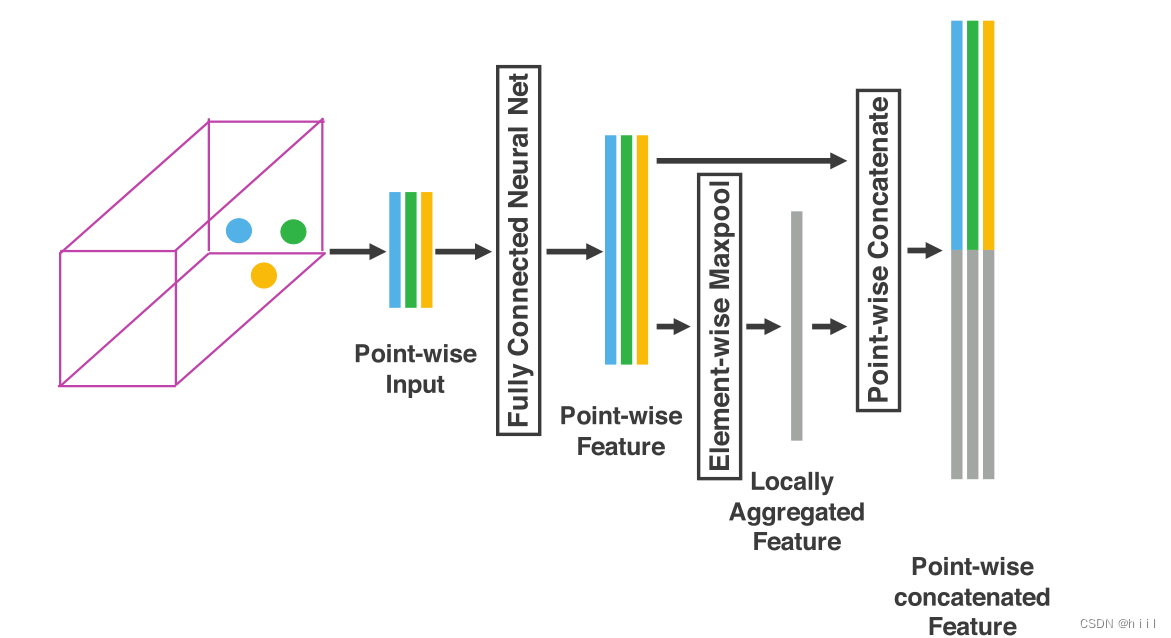
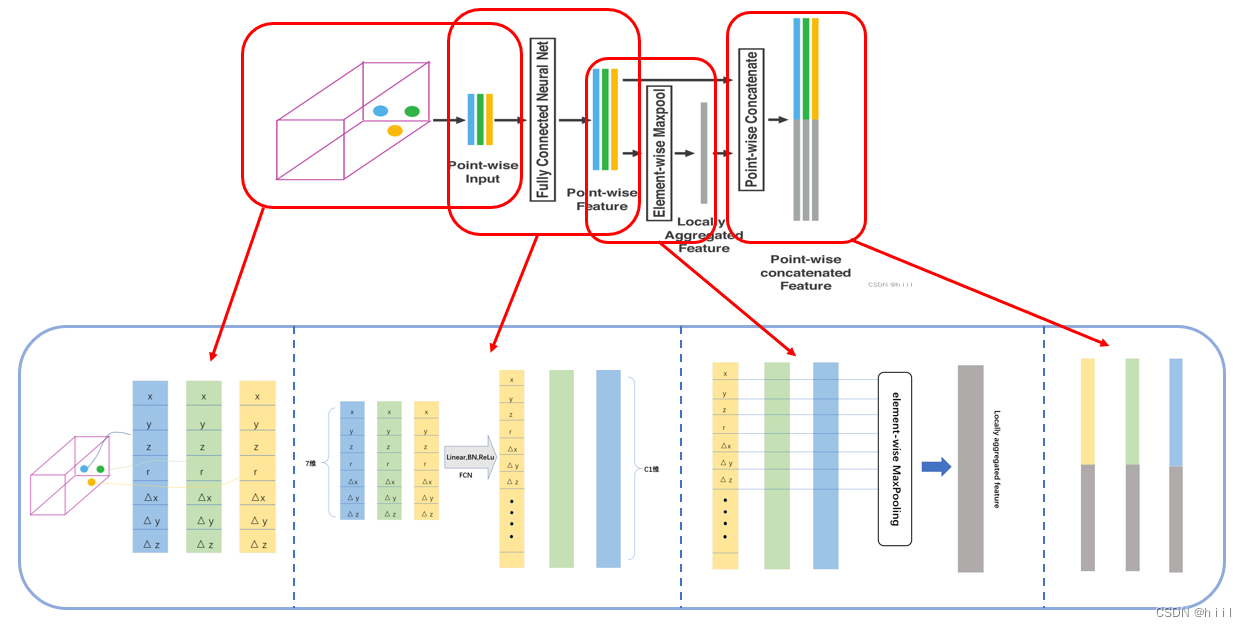
经过体素化、分组、随机采样处理之后。一帧点云数据被划分成了多个包含若干点云的体素。下面让我们走进一个体素中去。对体素进行特征编码和表示就是这片论文的核心。流程如上图所示。
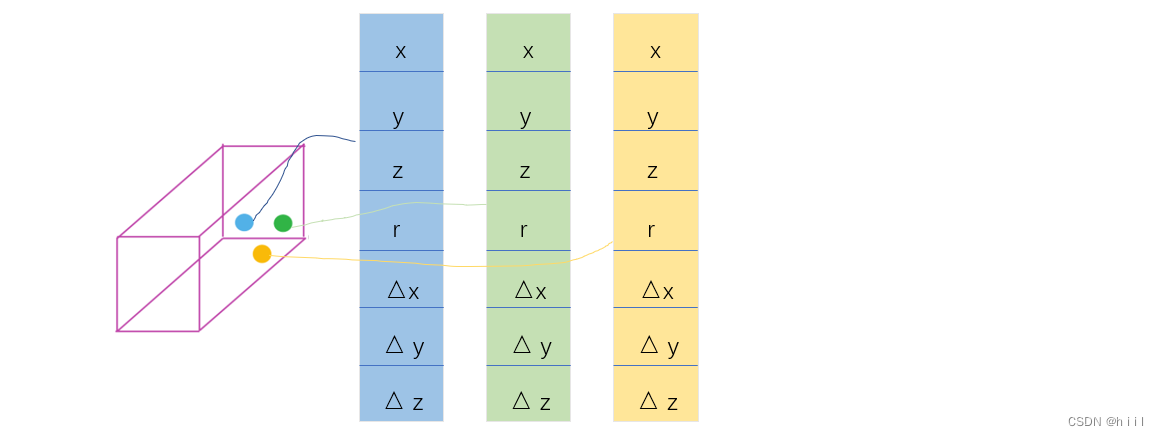
设非空体素V中有t个点,每个点有四维特征x、y、z、r,其中xyz是空间坐标,r是反射率。那么整个体素可以表示为集合。这是每个点各自的特征,接下来要做一些特征增强,即用这些特征来获取体素的特征以及表征各个点与体素的关系的特征。可以先运算体素的质心
,然后计算每个点相对这个质心的偏移量
,把这几个特征加在点特征的后面,这样每个点的特征不仅包含自身的信息,也包含了局部的信息,这也是一种特征增强的方法。现在就得到了某体素中一个点的完整表述。也就是上图中的input:
详细示意图如下所示:
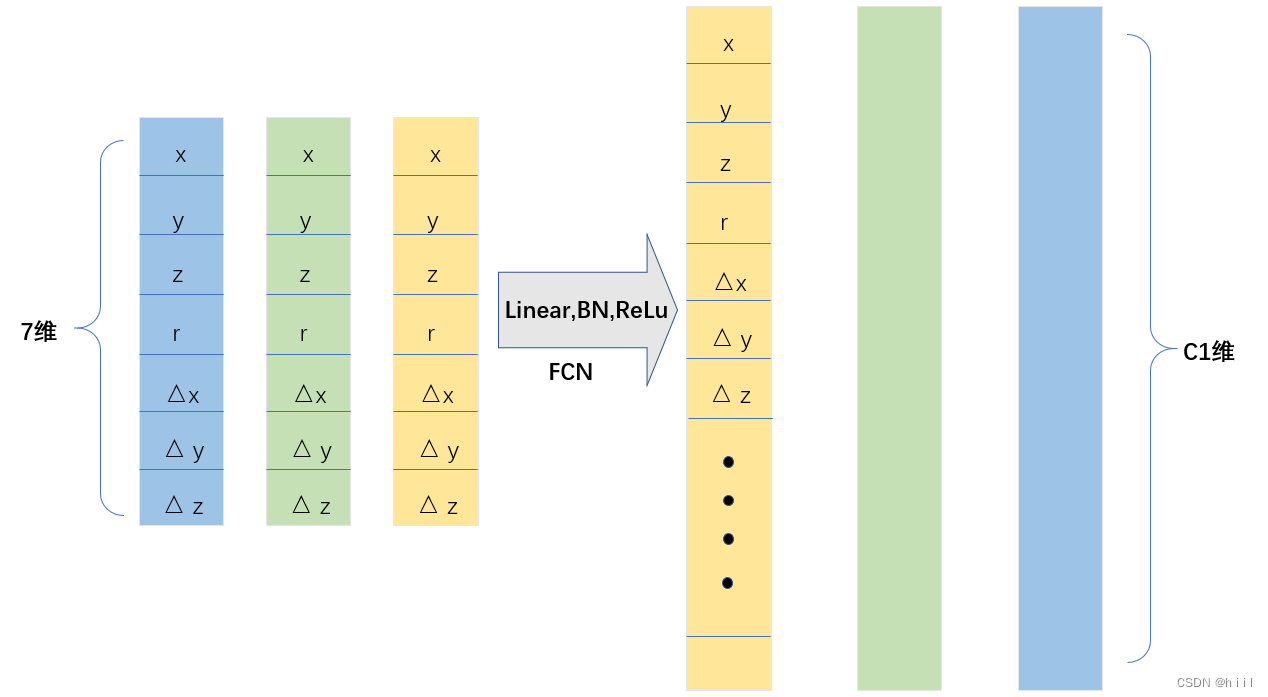
然后使用PointNet中提到的维度扩升的方法,通过FCN(linear,bn,relu)把维度从7升到了C1。
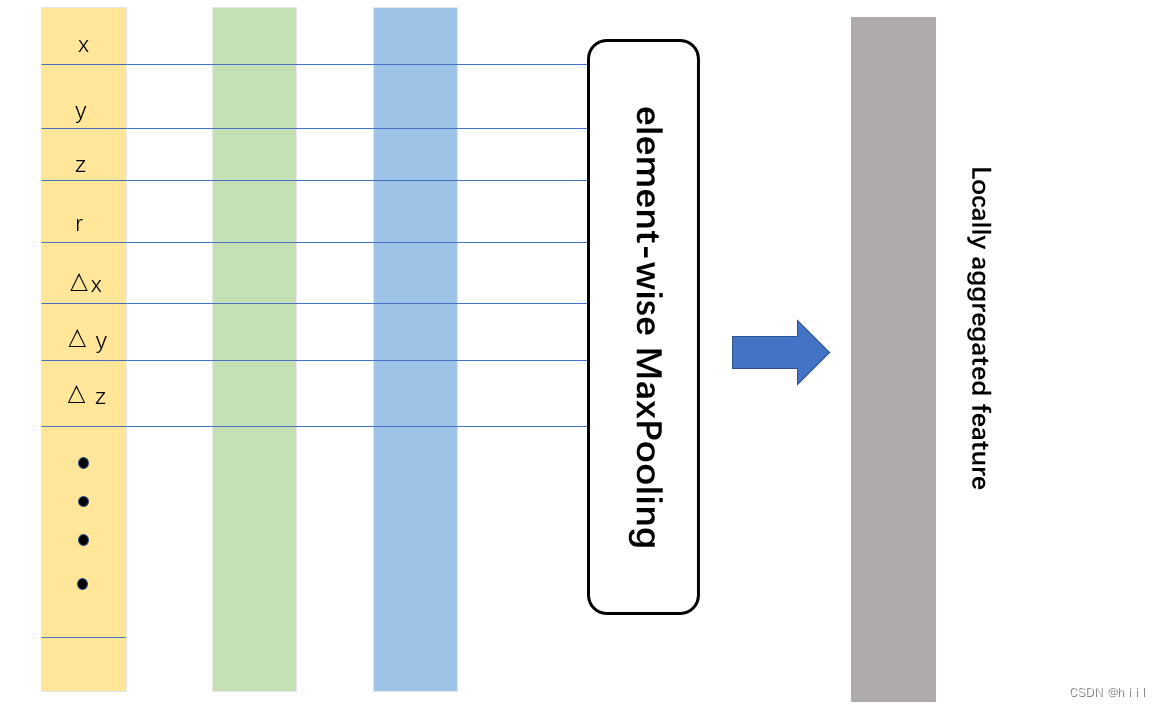
然后对一个体素中的所有点,在相同维度上用最大池化得到的一组特征就是可以用来表征该voxel的特征了,比如该体素的表面形状信息等。相当于在一个voxel中用了一次PointNet,把提取出的特征作为该voxel的局部特征locally aggregated feature(LAF)。
最后把体素的特征加在体素中点的特征后面,共同组成特征。
可以总结为:
以上是自己的一点理解,如果有不对的地方,欢迎交流!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









