







RLHF 是 Reinforcement Learning with Human Feedback(带有人类反馈的强化学习)的缩写。它是一种结合了强化学习(RL)和人类反馈的训练方法,广泛应用于人工智能(AI)系统的训练,尤其是在训练大型语言模型(如 GPT 系列、ChatGPT)时取得了显著成功。
一. RLHF 的基本概念
强化学习(Reinforcement Learning,RL)是机器学习中的一个重要分支,其中智能体(Agent)通过与环境的交互来学习策略,使得其行为能够最大化某种奖励(reward)。然而,传统的强化学习通常需要环境能够给出明确的奖励信号,这在某些情况下是非常困难的,特别是在复杂的任务中。
RLHF 则通过结合人类的反馈来解决这个问题。具体来说,RLHF 允许机器学习算法从人类反馈中获取信息,而不需要明确的奖励信号。这样,模型可以通过人类提供的指导来学习如何执行任务。
二. RLHF 的工作流程
论文中给出的核心思想示意图
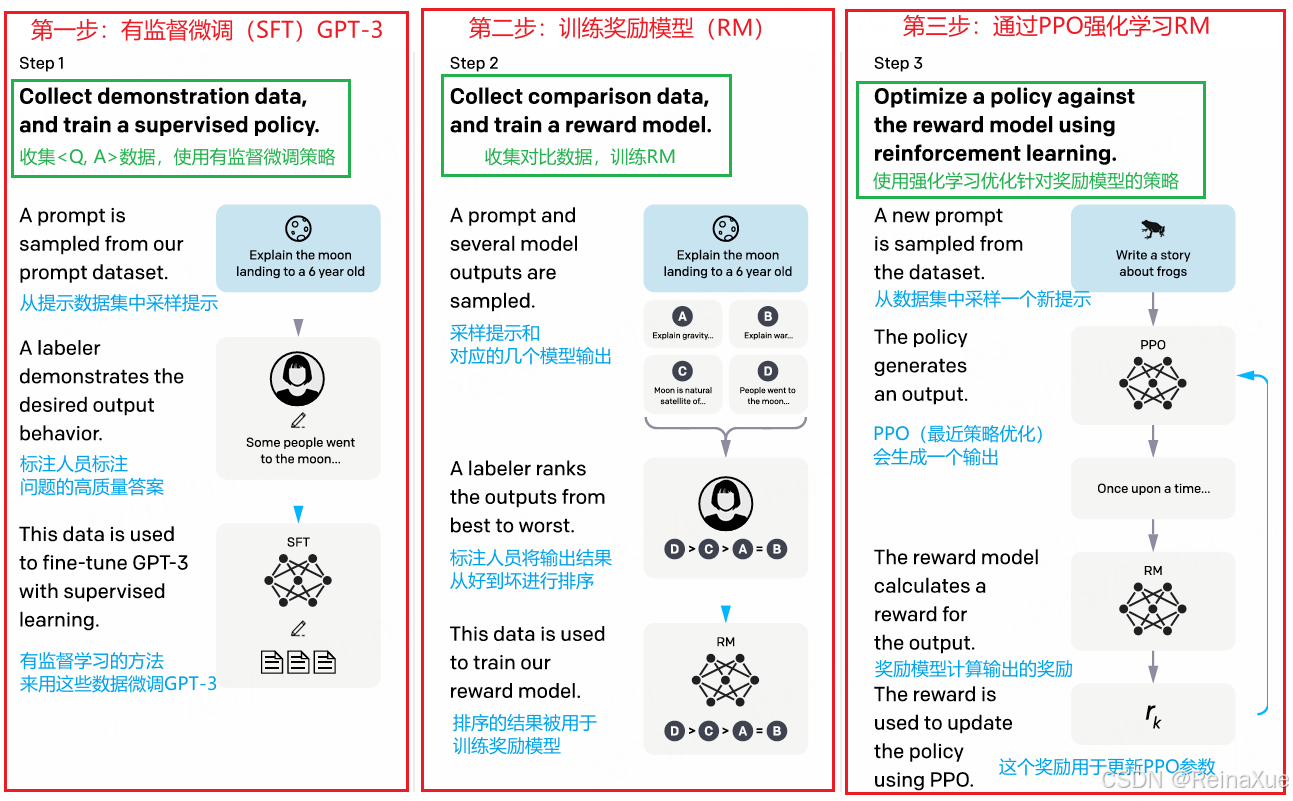
RLHF 的工作通常可以分为以下几个阶段:
阶段 1: 预训练
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 626
626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









