






1. 注意力机制的背景和动机
1.1 为什么需要注意力机制?
-
传统模型的局限性:RNN、CNN 等模型在处理长序列或全局依赖时,信息可能被稀释或遗忘(尤其在RNN中出现梯度消失问题)。
-
信息选择问题:在自然语言处理(NLP)等任务中,不是所有输入信息对当前任务同等重要,注意力机制可以有选择性地聚焦在关键部分。
-
人类认知启发:人类在感知和理解信息时,也往往通过“注意”某些关键区域来提高效率(例如看图时只关注目标区域)。
1.2 注意力机制的起源与发展里程碑
-
2014年 Bahdanau Attention:首次在机器翻译中提出,引入对齐机制,用于替代传统编码器-解码器结构中固定长度向量的瓶颈。
-
2015年 Luong Attention:提出了更高效的注意力计算方式。
-
2017年 Transformer 架构:由 Vaswani 等人提出,将注意力机制提升为核心架构(Self-Attention + Multi-Head Attention),彻底抛弃了RNN。
-
后续发展:各种注意力变体(Sparse, Adaptive, Dynamic 等)不断涌现,用于提升效率和效果,跨模态、多模态任务广泛使用。
2. 注意力机制的基本原理
2.1 什么是注意力机制?
注意力机制是一种加权汇聚(weighted aggregation)机制,通过计算输入信息之间的相关性,动态地分配不同的信息权重,以聚焦于更有用的部分。
2.2 数学表达与基本公式
以最经典的 Scaled Dot-Product Attention 为例:
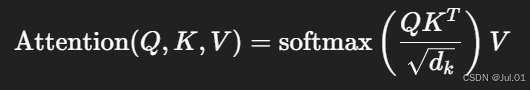
-
Q(Query)、K(Key)、V(Value)分别是查询、键、值的矩阵;
-
d_k 是 Key 向量的维度;
-
softmax 用于将相似度转化为概率分布;
-
结果是加权后的 Value 向量。
2.3 机器翻译中的 Attention 示例
在翻译任务中,解码器在生成每个词时,对输入句子的每个词分配一个注意力权重,表示该输入词对当前输出词的影响。
例如:
输入: "I love machine learning" 输出: "J'aime l'apprentissage automatique"
生成 "J'aime" 时,模型可能更关注 "I" 和 "love";生成 "automatique" 时,注意力更多集中在 "machine learning"。
2.4 如何计算注意力权重?
-
计算方式依赖于 Query 和 Key 的相似性:
-
Dot-Product:QK^T
-
Additive Attention(Bahdanau):通过一个前馈网络对 Q 和 K 进行组合打分
-
-
应用 softmax 归一化,得到注意力分布。
3. 注意力机制的主要类型
3.1 键值对注意力机制(Key-Value Attention)
基础结构,Query 与 Key 比较得出权重,对 Value 加权求和,常用于 Encoder-Decoder 架构。
3.2 自注意力(Self-Attention)
输入的每个位置都作为 Query、Key、Value,计算序列内部的相互依赖关系。Transformer 的核心。
3.3 多头注意力(Multi-Head Attention)
并行使用多个不同参数的注意力头,每个头从不同的表示子空间中学习信息,最后拼接输出:
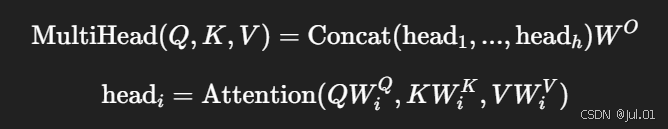
3.4 Soft Attention 与 Hard Attention
-
Soft Attention:权重是连续可微的(如 softmax 输出),可端到端训练;
-
Hard Attention:进行离散选择,需用强化学习等非梯度方法优化,效率高但训练复杂。
3.5 全局注意力(Global Attention)与局部注意力(Local Attention)
-
全局:对所有输入进行注意力计算;
-
局部:只对相邻或特定窗口范围的输入进行注意力(减少计算开销)。
4. 注意力机制的优化与变体
4.1 稀疏注意力(Sparse Attention)
-
将不重要的注意力权重设为零,降低计算复杂度;
-
如 Longformer、BigBird 使用窗口稀疏或全局+局部机制。
4.2 自适应注意力(Adaptive Attention)
-
动态调整注意力权重的分布范围(如Adaptive Span,动态决定注意力范围);
-
减少不必要的计算,提升效率。
4.3 动态注意力机制(Dynamic Attention)
-
根据输入的内容或上下文动态决定注意力结构或参数;
-
如 DynamicConv、Dynamic Routing(用于 Capsule Network)。
4.4 跨模态注意力机制(Cross-Modal Attention)
-
不同模态之间建立注意机制(如图像和文本之间);
-
应用于图文匹配(如 CLIP)、视频问答、多模态翻译等。
5. 注意力机制的可解释性与可视化技术
5.1 注意力权重的可视化(权重热图)
-
权重热图(Heatmap):展示输入与输出之间的注意力强弱;
-
应用于分析模型关注了哪些词、哪些区域;
-
如BERT可视化分析可看出其对句法结构的学习能力。
-
5.2 应用工具
-
BertViz:可视化 Transformer 模型注意力头的工具;
-
Captum(PyTorch)/Integrated Gradients:用于可解释性分析;
-
Grad-CAM(图像模型):结合注意力可视化特征图。

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









