






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
文献来源:

摘要:
移动边缘计算(MEC)利用网络边缘的计算能力来执行各种物联网应用中的计算密集型任务。同时,无人机(UAV)具有灵活扩大覆盖范围和增强网络性能的巨大潜力。因此,利用无人机为大量物联网设备提供边缘计算服务已成为一种有前景的范式。本文研究了无人机辅助边缘计算网络的路径规划问题,其中一架无人机部署了边缘服务器,用于执行从多个设备卸载的计算任务。我们考虑设备的移动性,采用了高斯马尔可夫随机移动模型。考虑到无人机动态飞行和执行任务消耗的能量,我们制定了一个旨在最大化设备卸载的数据比特量同时最小化无人机能量消耗的路径规划问题。为了处理复杂环境的动态变化,我们应用深度强化学习(DRL)方法,基于双深度Q学习网络(DDQN)开发了一种在线路径规划算法。广泛的仿真结果验证了所提出的基于DRL的路径规划算法在收敛速度和系统奖励方面的有效性。
移动边缘计算(MEC)使得网络边缘的计算能力能够灵活快速地部署创新的应用和服务,为大量物联网设备[1]。有了MEC的部署,设备可以将计算密集型任务转移到附近强大的边缘服务器,以减少延迟和节省能量[1],[2]。与固定的边缘服务器不同,最近的一些工作致力于移动边缘服务器的研究,它可以在恶劣环境中提供更灵活、更经济和更高效的计算服务。最近的一些文献提出使用无人机来改善地面物联网设备的连接性[3]。无人机辅助无线通信在灵活部署、完全可控的移动性和增强网络性能方面具有优势,因此引起了越来越多的研究兴趣。因此,无人机辅助边缘计算网络是一个自然的选择和有前景的范式,在其中如何优化无人机的飞行路径以满足大量设备的通信和计算需求成为一个重要且具有挑战性的问题。
最近,一些现有文献已经研究了无人机辅助移动边缘计算网络中的路径规划问题。在[4]中,针对无人机的延迟和能量消耗约束条件下,联合优化了无人机的轨迹和比特分配。然而,在这些工作中,设备被假定为固定的,并且移动性没有被考虑进去。在实际中,设备可能会随着时间动态变化,因此无人机需要根据移动设备的时变位置相应地调整其轨迹。与此同时,上述工作主要集中在传统的基于优化的路径规划算法上,但随着无人机和设备数量的增加,由于优化变量的激增,该方法效率可能不高[5]。在[6]中,通过使用深度神经网络(DNN)进行函数逼近,已经证明深度强化学习(DRL)在逼近Q值方面是有效的。此后,DRL已经被应用于无线网络中的在线资源分配和调度设计[7] - [9]。具体来说,在[7]中,通过优化卸载决策和计算资源分配,最小化了多用户MEC网络的执行延迟和能量消耗的总系统成本。在[8]中提出了一种在线卸载算法,用于最大化支持无线能量收集的无线供能MEC网络的加权求和计算速率。在[9]中,研究了基于深度强化学习的物联网设备计算卸载策略。然而,据我们所知,目前很少有现有的工作探讨了如何智能设计移动边缘计算网络中无人机的飞行轨迹,以服务于大量设备,尤其是考虑到设备的动态移动性和无人机与设备之间的动态关联。
移动数据处理技术在通信行业的使用正在增加。由于这项技术,具有大计算能力的物联网设备可能会以灵活和及时的方式推出独特的应用程序和服务。当边缘服务器用于卸载计算密集型任务时,延迟降低,能耗降低。近年来,无人机(UAV)以终端用户的多址边缘计算服务器的形式得到了利用。由于其灵活的部署、全面的控制和网络性能,UA V辅助无线通信受到了广泛的研究兴趣UAV辅助的边缘计算网络是有意义的,并且在处理巨大设备的通信和处理需求时是一个有趣的概念。
空中无人机(UAV)长期以来一直被用作移动网络中的网络处理器,但它们现在被用作移动边缘计算(MEC)中的移动服务器。由于它们的灵活性、可移植性、强大的视线通信联系以及低成本、可改变的使用,它们在研究和商业应用中变得更加流行。广泛的民用服务现在可能因其基本特性而得到支持,包括运输和工业监测、农业以及森林火灾和无线服务。本项目研究了基于无人机的移动边缘计算网络,其中无人机(UAV)进行移动终端用户向其提供的计算。为了确保每个TU的服务质量(QoS),UA V基于移动TU的位置动态选择其路线。
详细文章见第4部分。
一、研究背景与意义
随着物联网和人工智能技术的快速发展,多无人机系统在各个领域展现出巨大的应用潜力。然而,多无人机协同工作环境下复杂的网络拓扑结构、有限的能量资源以及动态变化的环境等挑战,严重制约了其性能发挥。移动边缘计算(MEC)技术的引入,为多无人机系统提供了强大的计算和存储能力,使得无人机能够在边缘节点进行数据处理和任务卸载,有效降低了对自身计算能力和通信带宽的需求。因此,基于强化学习的多无人机移动边缘计算与路径规划研究具有重要的理论意义和应用价值。
二、研究目标与内容
本文旨在探讨基于强化学习的多无人机移动边缘计算与路径规划策略,以提高系统效率,降低能耗。研究内容包括:
- 分析多无人机MEC系统的关键技术难点,如路径规划、任务分配、资源调度以及干扰协调等。
- 阐述基于强化学习的解决方案,包括状态空间、动作空间、奖励函数的设计以及算法选择。
- 通过仿真实验验证所提方案的有效性,并对未来的研究方向进行展望。
三、研究方法与技术路线
- 无人机模型:包括无人机的飞行速度、能量消耗模型、计算能力、通信能力等。
- 边缘服务器模型:包括边缘服务器的计算能力、存储容量、通信带宽等。
- 任务模型:包括任务的计算需求、数据大小、时延要求等。
- 通信模型:包括无人机与边缘服务器之间的信道模型,考虑信道衰落和干扰等因素。
- 能量模型:考虑无人机的飞行能量消耗和计算能量消耗。
基于上述模型,采用强化学习方法进行路径规划和资源分配。状态空间包含了系统当前的各种信息,如每个无人机的当前位置、剩余能量、当前任务、附近边缘服务器的状态等。动作空间代表了每个无人机可以采取的动作,如选择下一个飞行目标点、选择卸载任务的边缘服务器、调整飞行速度等。奖励函数的设计考虑了多个因素,如任务完成时间、能量消耗、任务成功率、网络延迟等,并对这些因素进行加权组合。强化学习算法包括Q-learning、Deep Q-Network(DQN)、Actor-Critic、Proximal Policy Optimization(PPO)等,需根据具体应用场景进行选择。
四、仿真实验与结果分析
仿真环境模拟了多无人机MEC系统的运行,包括无人机的飞行、任务执行、资源分配等过程。实验评估了不同强化学习算法的性能,比较了它们在任务完成时间、能量消耗、任务成功率等指标上的表现。通过分析实验结果,验证了所提方案的可行性和优越性。仿真实验还重点比较了不同强化学习算法在不同规模的多无人机系统中的表现,并分析了算法参数对系统性能的影响。
五、结论与展望
本文通过研究基于强化学习的多无人机移动边缘计算与路径规划策略,验证了该方法能够有效解决多无人机MEC系统中的路径规划和资源分配问题。未来研究将进一步考虑更复杂的系统模型,如动态环境、任务优先级、无人机故障等,并探索更先进的强化学习算法,如多智能体强化学习,以更好地处理多无人机协同问题。同时,分布式强化学习算法的研究也将提高系统可扩展性和鲁棒性。此外,安全性与隐私保护也是未来研究的重要方向。
综上所述,基于强化学习的多无人机移动边缘计算与路径规划研究为构建高效、可靠的多无人机系统提供了新的途径,并有望在未来广泛应用于各个领域。
📚2 运行结果
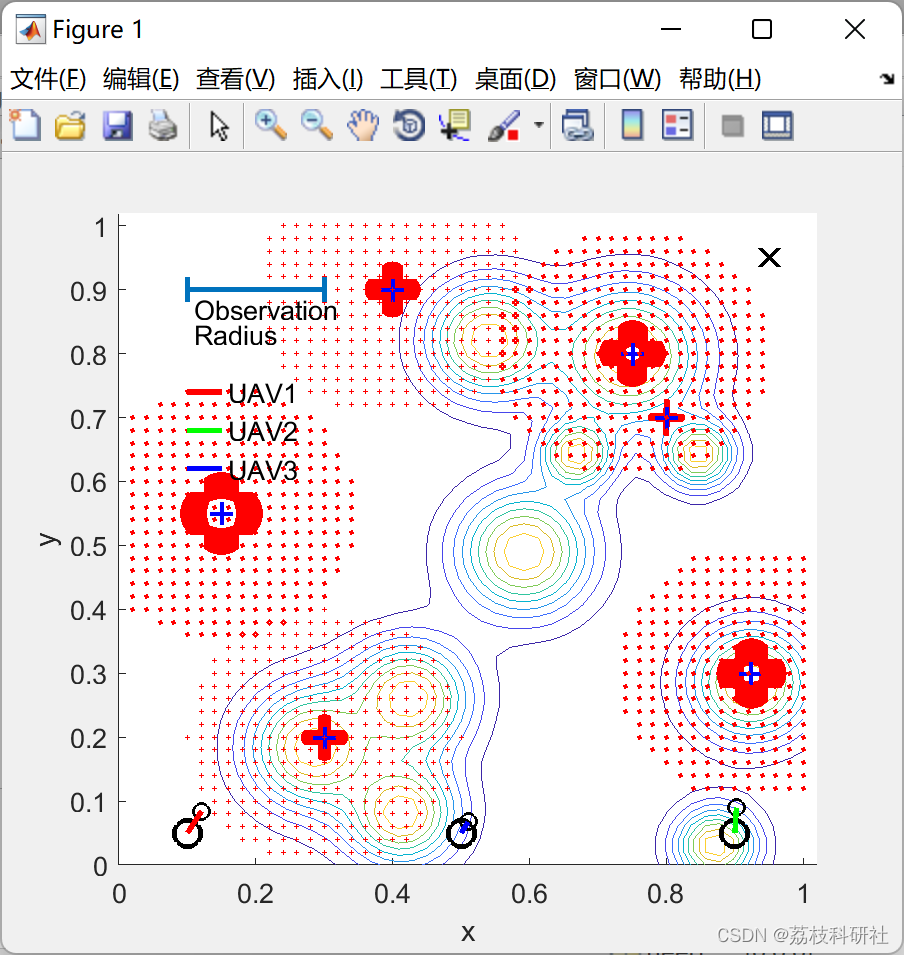
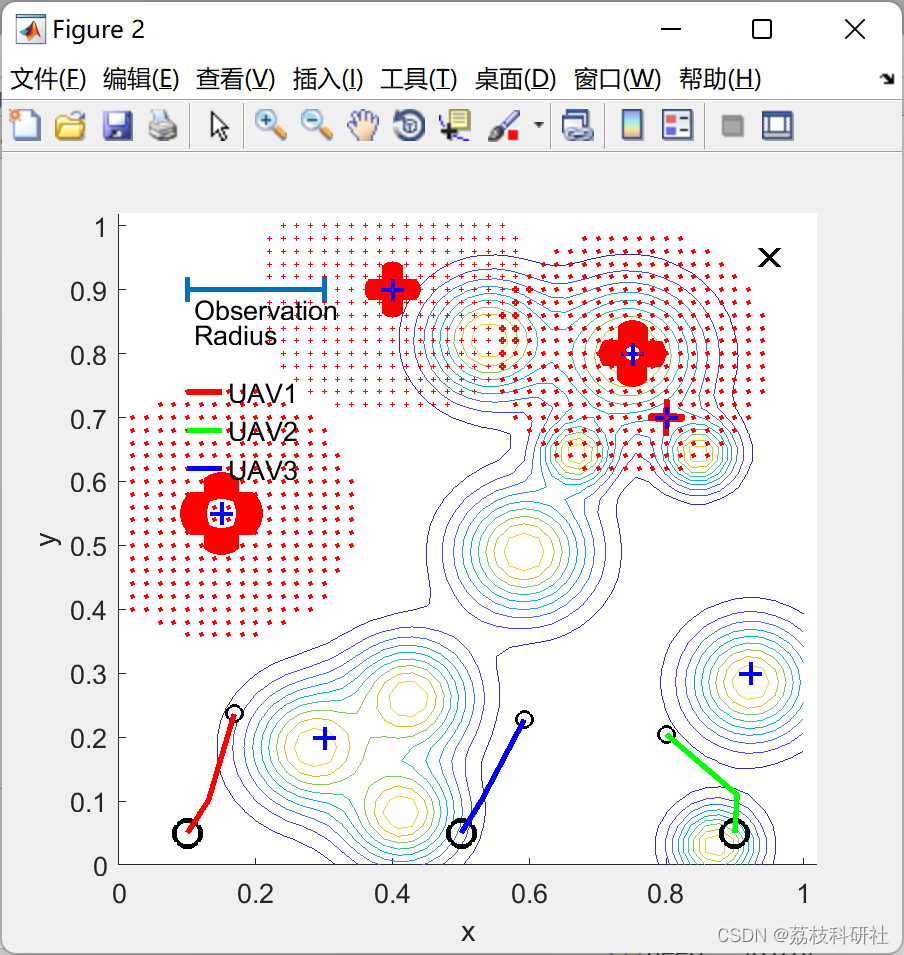
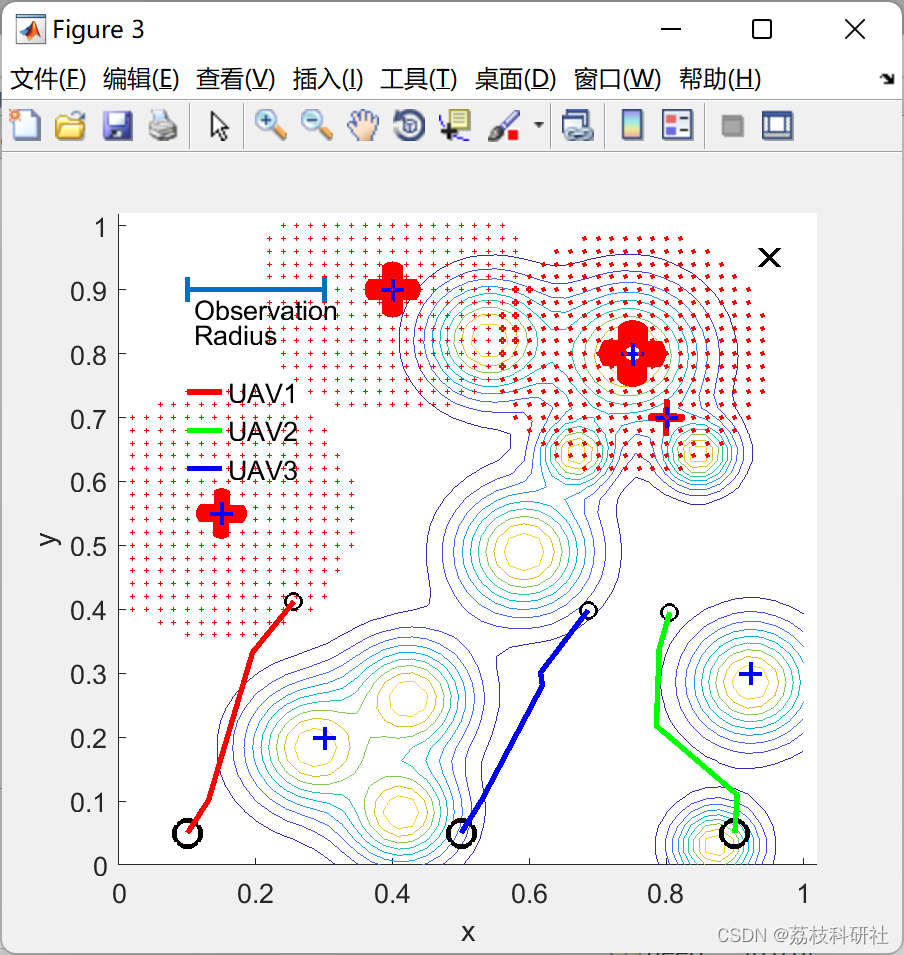
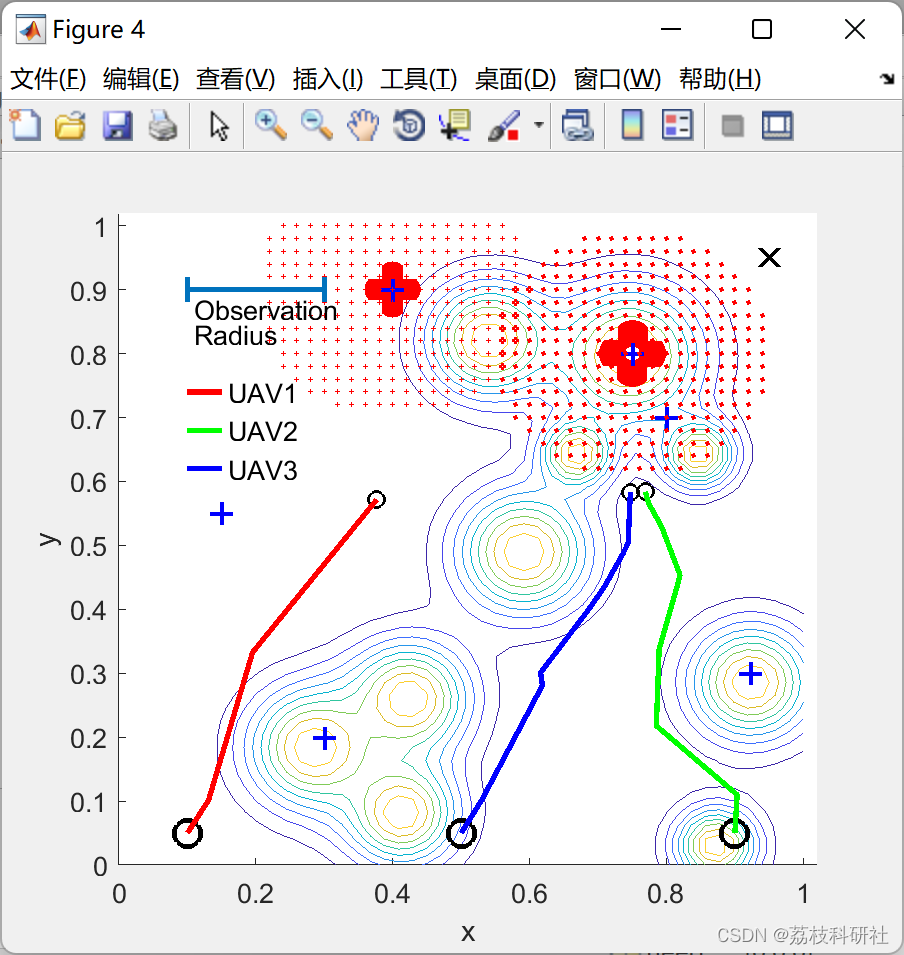
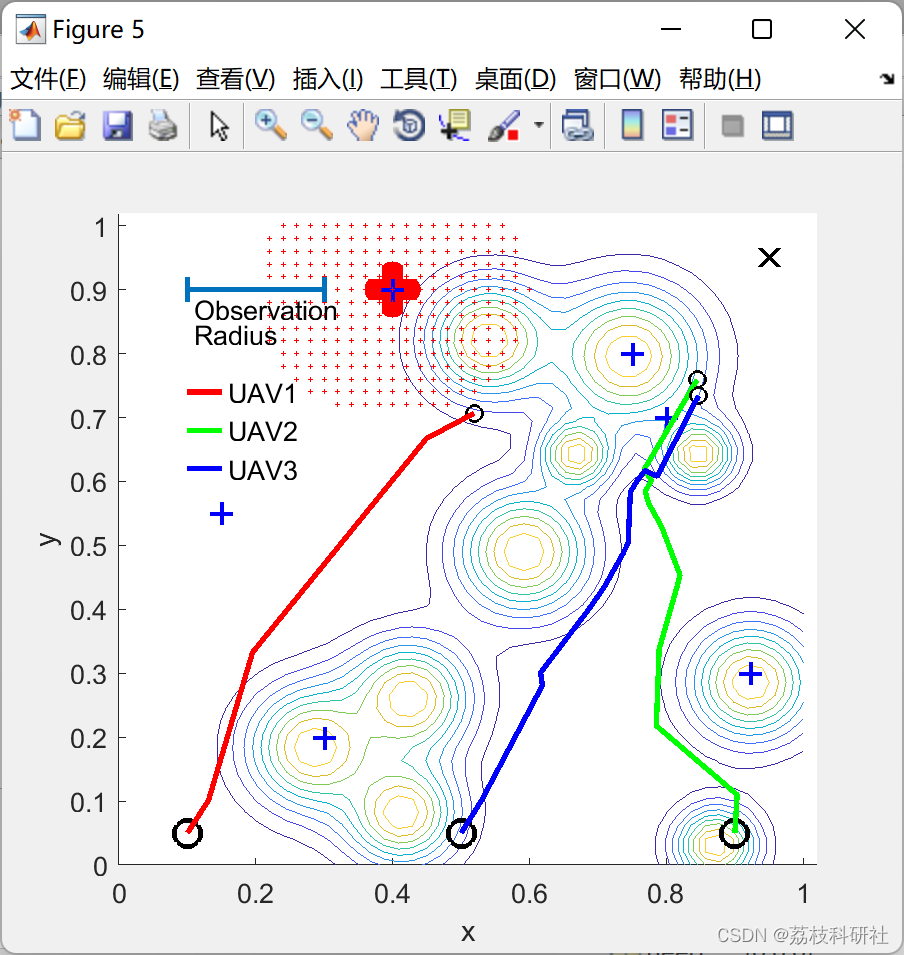
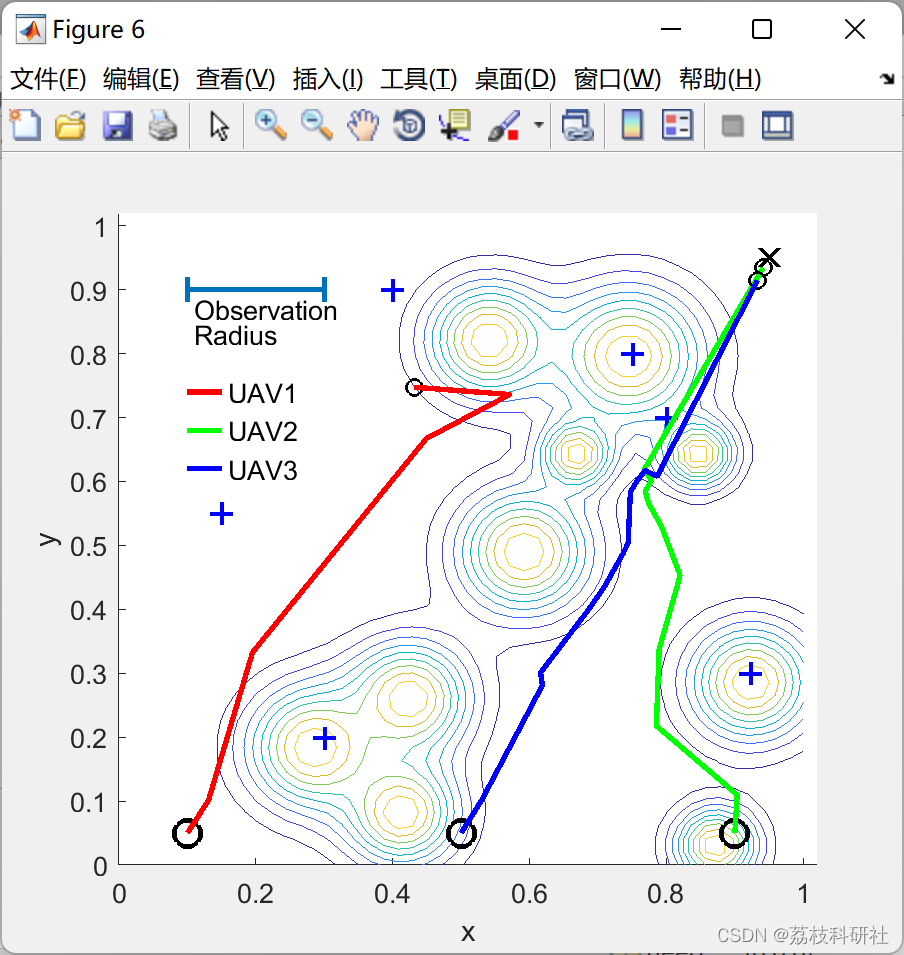
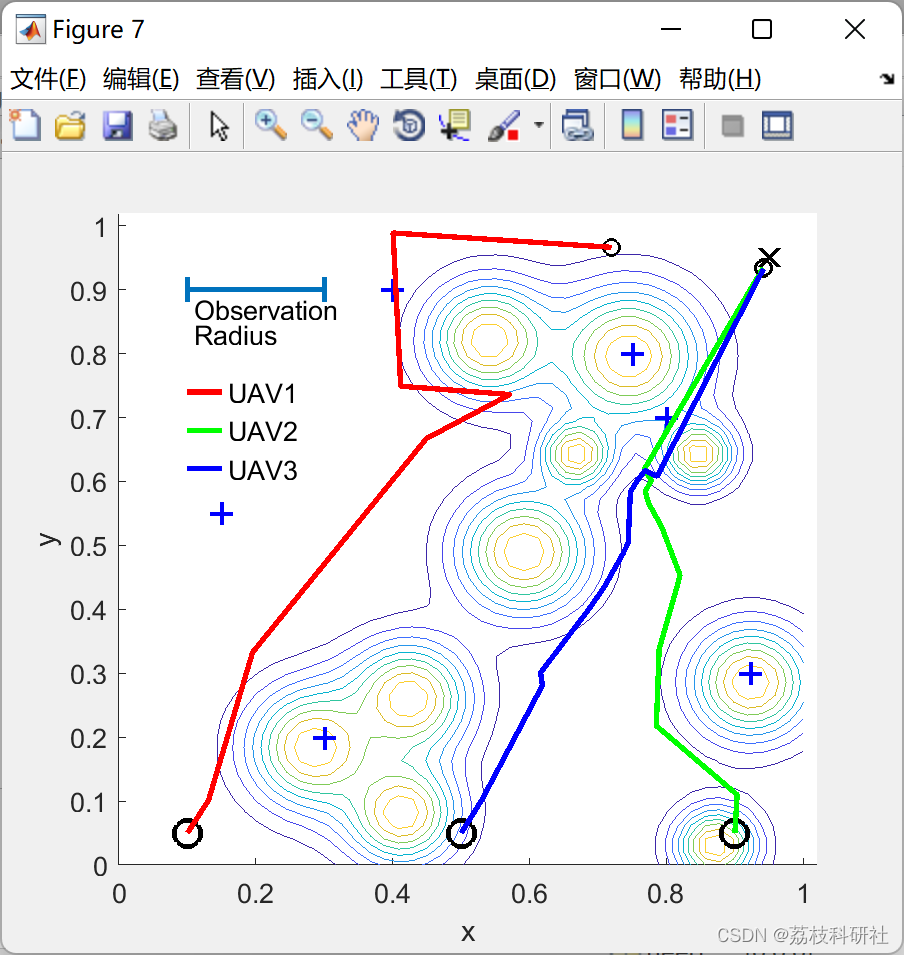
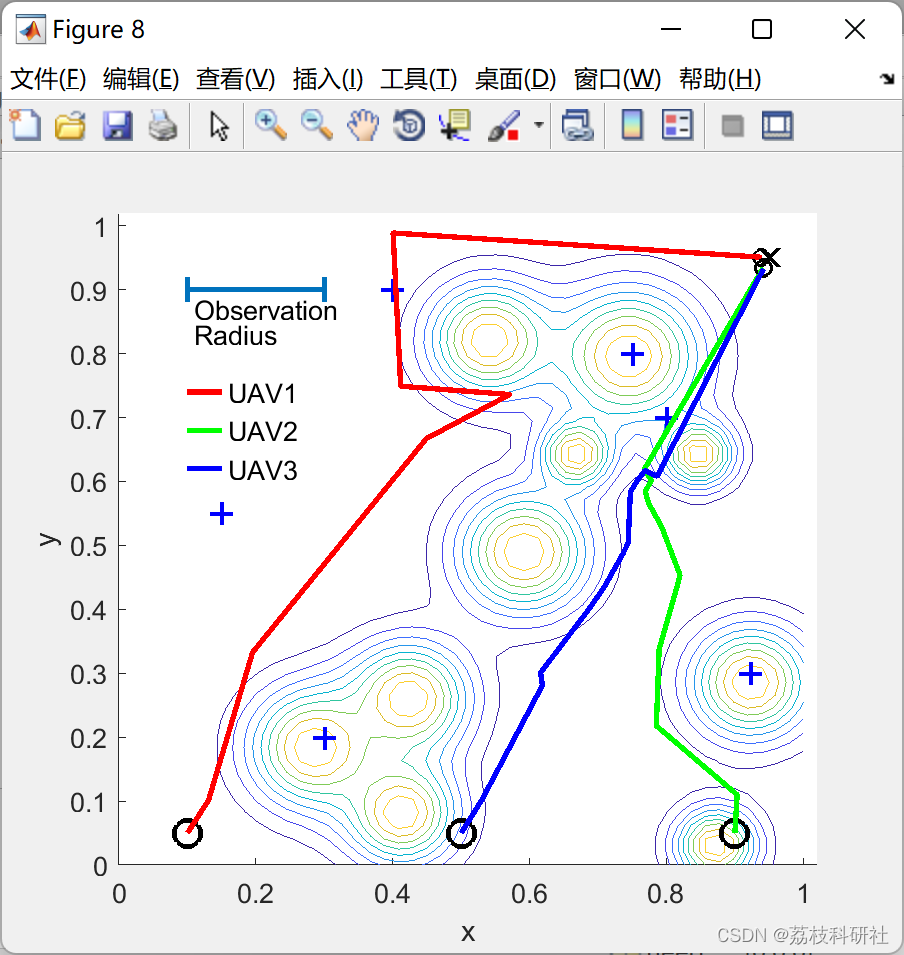 部分代码:
部分代码:
function TU_demand_matrix = TU_demand_linear
%% parameters
global N2;
global TU_info;
global SERVICE_RADIS;
global n;
global B;
%% Normalize
maxDemand=max(TU_info(:,3));
minDemand=min(TU_info(:,3));
%% Calculate accumulated TU_info service demand matrix
TU_demand_matrix=zeros(N2,N2); %initial T as N2*N2 0 matrix
for x=1:N2 %for point (x,y) in N2*N2, summrize demand from TU_info with in SERVICE_RADIS, return T
for y=1:N2
sum=0;
for i=1:size(TU_info,1)
if norm([x/N2,y/N2]-TU_info(i,1:2))<= SERVICE_RADIS
sum=sum+(TU_info(i,3)-minDemand)/(maxDemand-minDemand);
end
end
TU_demand_matrix(x,y)=sum;
end
end
end
🎉3 文献来源
部分理论来源于网络,如有侵权请联系删除。


















 2351
2351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









