







多层感知机
- 初始化参数
#初始化参数
from mxnet import ndarray as nd
num_inputs=28*28
num_outputs=10
num_hidden=256
weight_scale=.01
W1=nd.random_normal(shape=(num_inputs,num_hidden),scale=weight_scale)
b1=nd.zeros(num_hidden)
W1=nd.random_normal(shape=(num_hidden,num_outputs),scale=weight_scale)
b1=nd.zeros(num_outputs)
params=[W1,b1,W2,b2]
for param in params:
param.attach_grad()
这段代码是一个简单的参数初始化过程,用于创建一个具有单隐藏层的全连接神经网络。以下是对代码的解释:
导入需要的库:从mxnet模块中导入ndarray并将其重命名为nd,用于数组操作。
定义输入和输出的维度:num_inputs表示输入的特征数,这里是28x28的图像像素;num_outputs表示输出的类别数,这里是10个类别。
定义隐藏层的大小:num_hidden表示隐藏层的神经元数量,这里设置为256个。
定义权重和偏置的初始化标准差:weight_scale设置为0.01,用于初始化权重矩阵。
初始化第一层权重和偏置:使用nd.random_normal函数根据指定的形状和标准差随机生成符合正态分布的权重矩阵 W1,并初始化偏置向量 b1 为全零向量。
初始化第二层权重和偏置:同样使用nd.random_normal函数来初始化第二层的权重矩阵 W2,并初始化偏置向量 b2 为全零向量。
将参数添加到参数列表:将所有的参数矩阵和偏置向量添加到一个列表 params 中,方便后续访问和处理。
为参数附上梯度:通过 attach_grad 方法,将参数的梯度信息附加到相应的参数上,以便后续进行反向传播和参数更新。
这段代码的作用是初始化一个具有单隐藏层的神经网络模型,并为模型的参数添加梯度信息。在此之后,可以使用这些参数进行前向传播和反向传播等操作。
- 激活函数
#激活函数
#为了让我们的模型可以拟合非线性函数,需要在层与层之间插入非线性的激活函数
def relu(X):
return nd.maximum(X,0)
其中 nd.maximum(X, 0) 表示对输入矩阵 X 的每个元素逐元素地取最大值和0之间的较大值。其效果是将小于0的值变为0,而大于等于0的值保持不变。即当输入大于等于0时,激活函数输出该值;当输入小于0时,激活函数输出0。
relu 激活函数的特点是具有线性增长的部分,因此可以有效地解决梯度消失问题,并且计算简单,不需要额外的参数。在实际应用中,relu 是一种常用的激活函数,经常用于深度学习模型的隐藏层上。
- 定义模型
#定义模型
def net(X):
X=X.reshape((-1,num_inputs))
h1=relu(nd.dot(X,W1)+b1)
output=nd.dot(h1,W2)+b2
return output
该函数接受输入 X,首先将输入数据 X 重塑为形状为 (-1, num_inputs) 的二维张量。这里使用了 -1 来表示自动推断该维度的大小,以适应不同批次大小的输入。
然后,通过矩阵乘法和偏置加法计算隐藏层的输出 h1。使用 nd.dot(X, W1) 进行矩阵乘法,并添加偏置向量 b1。然后将结果应用 relu 激活函数,得到隐藏层的输出。
最后,通过矩阵乘法和偏置加法计算最终的输出 output。使用 nd.dot(h1, W2) + b2 进行矩阵乘法并添加偏置向量 b2。
最后,返回输出 output。
这个神经网络模型由一个隐藏层和一个输出层组成,其中隐藏层使用 relu 激活函数进行非线性变换。
- softmax和交叉熵损失函数
#softmax和交叉熵损失函数
from mxnet import gluon
softmax_cross_entropy=gluon.loss.SoftmaxCrosssRbtropyLoss()
- 训练
#训练
from mxnet import autograd
learning_rate=.5
for epoch in range(5):
train_loss=0.
train_acc=0.
for data,label in train_data:
with autograd.record():
output=net(data)
loss=softmax_cross_entropy(output,label)
loss.backward()
#将梯度做平均 这样学习率会对batch_size 不那么敏感
SGD(params,learning_rate/batch_size)
train_loss+=nd.mean(loss).asscalar()
train_acc+=accuracy(output,label)
test_acc=evaluate_accuracy(test_data,net)
print("Epoch %d. Loss: %f,Train acc %f,Test acc %f"%(epoch,train_loss/len(train_data),train_acc/len(train_data),test_acc))
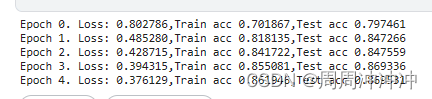
可以看到,增加一个隐含层,精度提升了不少
尝试增加epoch继续训练
- 使用Gluon定义多层感知机
from mxnet import gluon
net=gluon.nn.Sequential()
with net.name_scope():
net.add(gluon.nn.Flatten())
net.add(gluon.nn.Dense(256,activation="relu"))
net.add(gluon.nn.Dense(10))
#函数初始化
net.initialize()
#读取数据并训练
#数据读取
batch_size=256
train_data=gluon.data.DataLoader(mnist_train,batch_size,shuffle=True)
test_data=gluon.data.DataLoader(mnist_test,batch_size,shuffle=False)
softmax_cross_entropy=gluon.loss.SoftmaxCrossEntropyLoss()
#优化
trainer = gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':0.5})
for epoch in range(5):
train_loss=0.
train_acc=0.
for data,label in train_data:
with autograd.record():
output=net(data)
loss=softmax_cross_entropy(output,label)
loss.backward()
#将梯度做平均 这样学习率会对batch_size 不那么敏感
trainer.step(batch_size)
train_loss+=nd.mean(loss).asscalar()
train_acc+=accuracy(output,label)
test_acc=evaluate_accuracy(test_data,net)
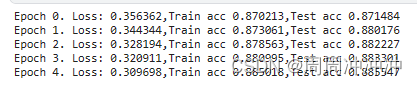
print("Epoch %d. Loss: %f,Train acc %f,Test acc %f"%(epoch,train_loss/len(train_data),train_acc/len(train_data),test_acc))

过拟合
训练误差和泛化误差是在机器学习模型中经常使用的两个概念,它们对于了解模型的表现和性能至关重要。
训练误差(Training Error)是指模型在训练数据上的表现。它可以通过计算模型对已标记的训练样本的预测误差来得到。训练误差度量了模型对训练数据的拟合程度,通常用于评估模型是否能够很好地学习训练数据的特征。
然而,仅仅衡量模型在训练数据上的性能并不足以衡量其真实的泛化能力。泛化误差(Generalization Error)是指模型在未见过的测试数据上的表现。它度量了模型对新样本的预测能力。泛化误差反映了模型对于未知数据的适应能力,是评估模型在实际应用中的性能指标。
为了最小化泛化误差,需要关注过拟合(Overfitting)和欠拟合(Underfitting)问题:
过拟合:当模型太过复杂时,它可能会过度记忆训练数据中的噪声和细节,导致在新数据上的表现较差。在这种情况下,训练误差会非常低,但泛化误差会较高。
欠拟合:当模型太过简单时,它可能无法捕捉到数据中的复杂关系和模式,导致在训练数据和新数据上都表现不佳。在这种情况下,训练误差和泛化误差都会较高。
为了找到适当的模型复杂度,可以通过以下方法来减小泛化误差:
数据集划分:将数据集划分为训练集和测试集,用于评估模型的泛化能力。通常会使用交叉验证来更好地估计模型在不同数据子集上的性能。
正则化:通过在损失函数中引入正则化项,可以限制模型的复杂度,防止过拟合。常见的正则化方法包括 L1 正则化和 L2 正则化。
特征选择和降维:通过选择最相关的特征或使用降维技术(如主成分分析)来减少输入特征的数量,可以降低模型的复杂度。
数据增强:通过对训练数据进行随机变换、旋转、缩放等操作,扩充数据集的多样性,可以提高模型的泛化能力。
模型选择和调参:尝试不同的模型架构、超参数和优化算法,通过交叉验证等方法选择最佳模型,并调整超参数以优化模型的性能。
在训练和评估模型时,需要密切关注训练误差和泛化误差之间的差异,以保证模型具有良好的泛化能力。
from mxnet import ndarray as nd
from mxnet import autograd
from mxnet import gluon
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.dpi']=120
num_inputs=200
num_test=100
num_train=20
#生成数据集
true_w=nd.ones((num_inputs,1))*0.01
true_b=0.05
# 创建随机输入特征 X
X = nd.random_normal(shape=(num_test+num_train, num_inputs))
y=nd.dot(X,true_w)
y +=.01*nd.random.normal(shape=y.shape)
X_train,X_test=X[:num_train,:],X[num_train:,:]
y_train,y_test=y[:num_train],y[num_train:]
#读取数据
import random
batch_size = 1
def data_iter(num_examples):
# 产生一个随机索引
idx = list(range(num_examples))
random.shuffle(idx)
for i in range(0, num_examples, batch_size):
j = nd.array(idx[i:min(i + batch_size, num_examples)])
yield nd.take(X, j), nd.take(y, j)
#初始化模型参数
def get_params():
w=nd.random_normal(shape=(num_inputs,1))*0.1
b=nd.zeros((1,))
#对模型参数附上梯度
for param in (w,b):
param.attach_grad()
return (w,b)
#L2范数正则化
def net(X,lambd,w,b):
return nd.dot(X,w)+b+lambd+((w**2).sum()+b**2)
#定义训练和测试
#损失函数
def square_loss(yhat,y):
return (yhat-y.reshape(yhat.shape))**2
def SGD(params,lr):
for param in params:
param[:]=param-lr*param.grad
def test(params,X,y):
return square_loss(net(X,0,*params),y).mean().asscalar()
def train(lambd):
epochs=10
learning_rate=.002
params=get_params()
train_loss=[]
test_loss=[]
for e in range(epochs):
total_loss=0
for data ,label in data_iter(num_train):
with autograd.record():
output=net(data,lambd,*params)
loss=square_loss(output ,label)
loss.backward()
SGD(params,learning_rate)
total_loss+=nd.sum(loss).asscalar()
# print("Epoch %d,average loss:%f"%(e,total_loss/num_examples))
train_loss.append(test(params,X_train,y_train))
test_loss.append(test(params,X_test,y_test))
plt.plot(train_loss)
plt.plot(test_loss)
plt.legend(['train','test'])
plt.show()
return 'learned w[:10]:',params[0][:10],'learned b:',params[1]
#观察过拟合
train(0)
#使用正则化
train(1)
卷积神经网络
由卷积层构成的神经网络
- 卷积层
out=nd.Convolution(data,w,b,kernel=w.shape[2:],num_filter=w.shape[1])
- 池化层
data=nd.arange(18).reshape((1,2,3,3))
max_pool=nd.Pooling(data=data,pool_type="max",kernel=(2,2))
avg_pool=nd.Pooling(data=data,pool_type="avg",kernel=(2,2))
print(data,'\n',max_pool,'\n',avg_pool)














 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









