







一、诊断偏差和方差
在机器学习中,诊断偏差和方差是改进模型性能的关键步骤。通过了解这两个概念,能够判断算法的问题究竟是欠拟合还是过拟合,从而有针对性地调整模型。
1. 概念理解
偏差(Bias): 表示模型对于训练数据的拟合程度。高偏差意味着模型过于简单,无法捕捉数据的复杂性,导致欠拟合。
方差(Variance): 表示模型对于训练数据的敏感程度。高方差意味着模型过于复杂,几乎完美地适应训练数据,但在未见过的数据上表现较差,导致过拟合。
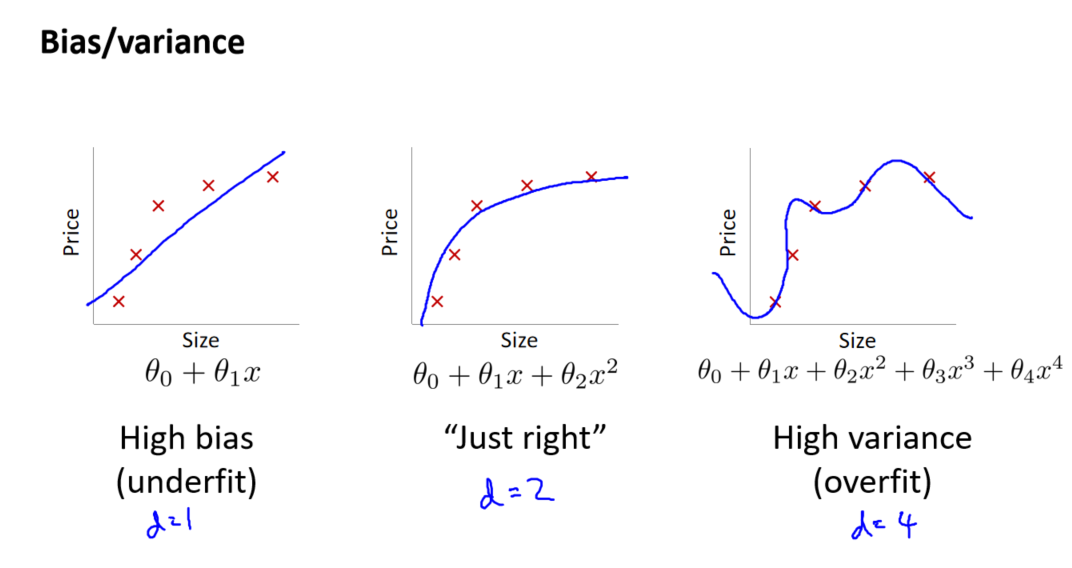
2. 评估偏差和方差
通过绘制训练集误差和交叉验证集误差随模型复杂度(例如多项式次数)的变化图表,我们可以直观地判断模型的问题:
- 训练集误差和交叉验证集误差近似时: 说明存在偏差问题(欠拟合)。
- 交叉验证集误差远大于训练集误差时: 暗示了方差问题(过拟合)。
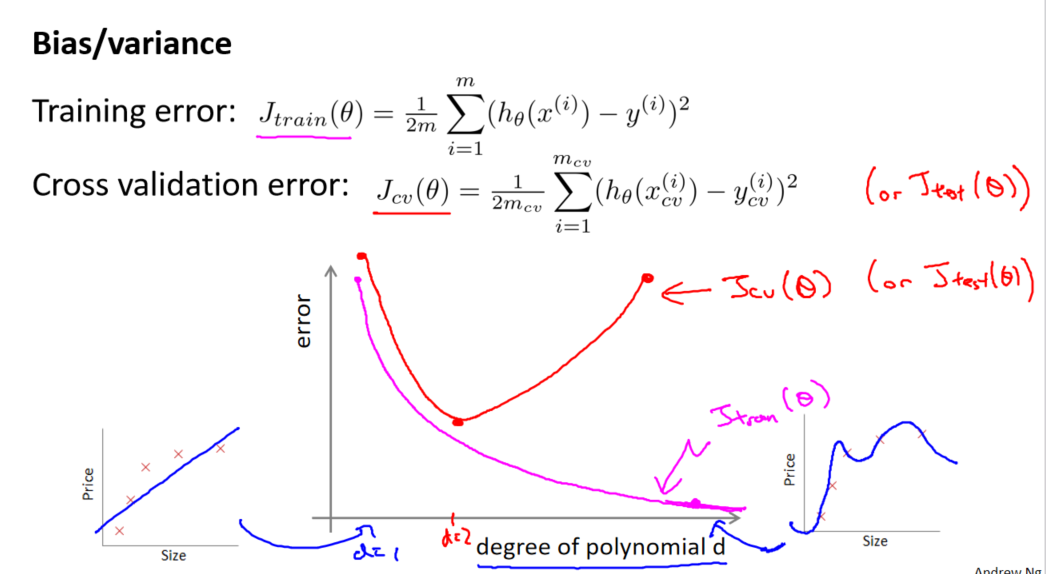
3. 图表解读
在图表中,训练集误差和交叉验证集误差随模型复杂度的变化呈现以下趋势:
- 训练集: 随着模型复杂度的增加,误差逐渐减小。
- 交叉验证集: 当模型过于简单时,误差较大;但随着模型复杂度的增加,误差呈现先减小后增大的趋势,表示模型开始过拟合。
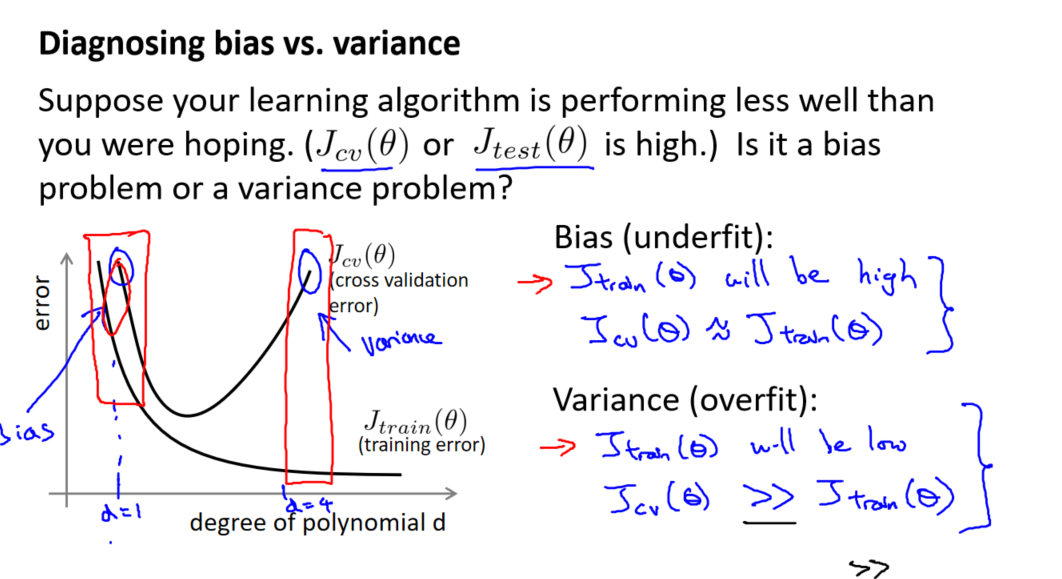
4. 判断偏差和方差
- 误差近似时: 存在偏差问题,需要更复杂的模型。
- 交叉验证集误差远大于训练集误差时: 存在方差问题,需要减少模型复杂度。
二、正则化和偏差/方差
在机器学习中,正则化是一种防止模型过拟合的重要技术。通过引入正则化项,能够控制模型的复杂度,防止其在训练集上表现过于优越而在测试集上表现不佳。在正则化的背景下,还需要考虑正则化参数(λ)的选择,这与选择模型复杂度的过程相似。
1. 正则化的介绍
正则化是通过在代价函数中引入额外的惩罚项来实现的,通常有两种形式:L1正则化和L2正则化。这些正则化项对模型参数进行惩罚,鼓励模型使用较小的参数值,从而防止过拟合。
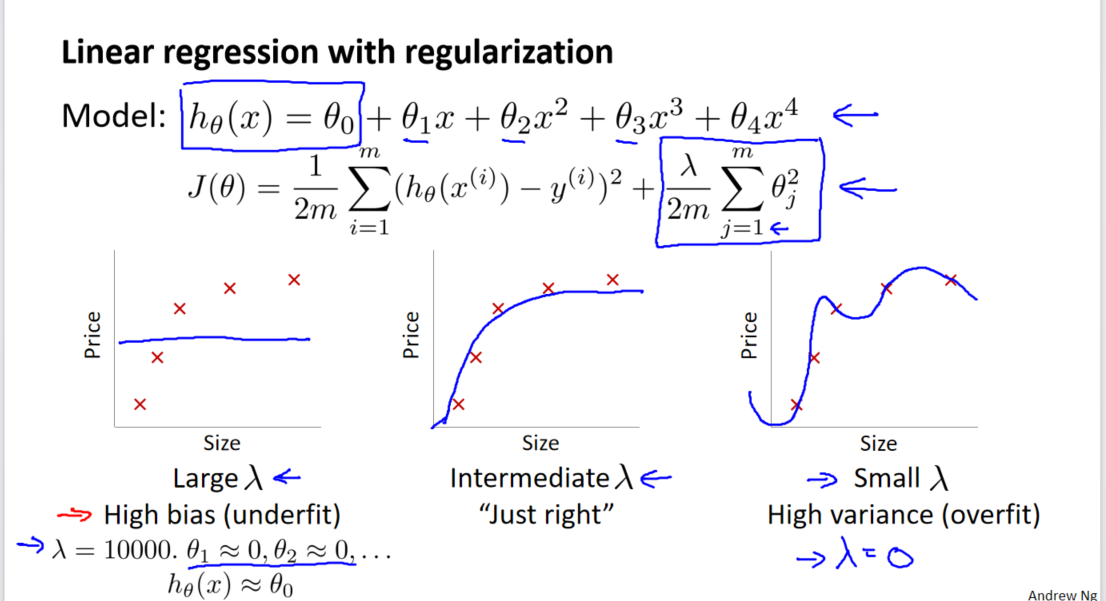
2. 选择正则化参数
选择正则化参数λ的过程类似于选择多项式模型的次数。需要在一系列候选λ值中选择最优的λ。选择的步骤如下:
- 使用训练集训练12个不同程度正则化的模型,分别对应不同λ值。
- 对这12个模型分别在交叉验证集上计算交叉验证误差。
- 选择具有最小交叉验证误差的模型对应的λ。
- 使用选定的模型对测试集进行评估,计算推广误差。
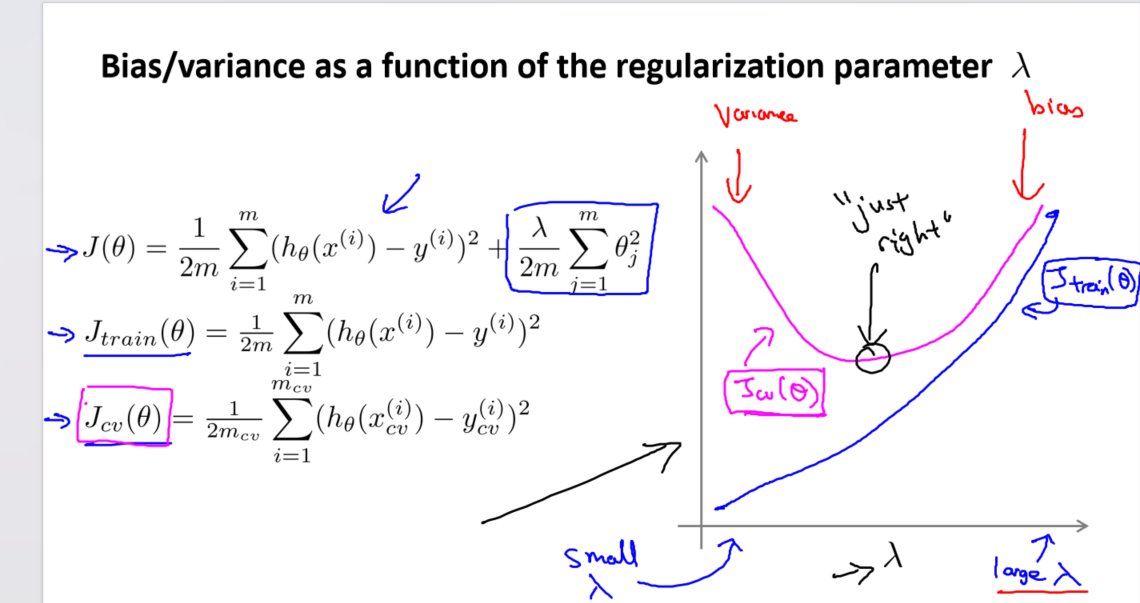
- 绘制训练集和交叉验证集模型的代价函数误差随λ变化的图表。

3. 图表解读
在图表中,随着λ的增加:
- 当λ较小时,训练集误差较小,但交叉验证集误差较大,表示过拟合。
- 随着λ的增加,训练集误差逐渐增加,而交叉验证集误差呈现先减小后增加的趋势。
4. 结论
通过选择适当的λ值,可以平衡模型的偏差和方差,防止过拟合,同时保持模型对训练数据的良好拟合。正则化是提高模型泛化能力的重要手段,而选择合适的λ则是正则化过程中的关键步骤。
参考资料:
















 591
591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











