






损失函数
常见损失函数分两类
距离标准衡量的损失函数
1.平方损失函数
 2.绝对损失函数
2.绝对损失函数
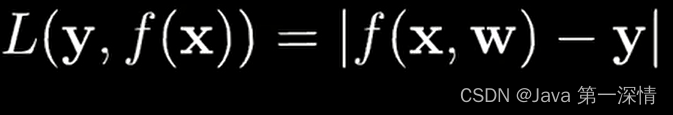 熵标准衡量的损失函数
熵标准衡量的损失函数
1.对数损失函数
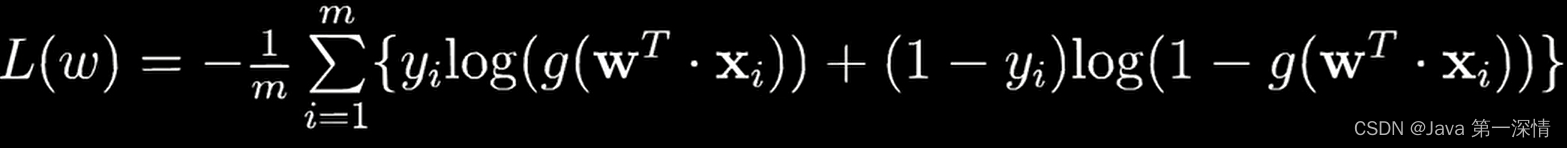
2.交叉熵损失函数
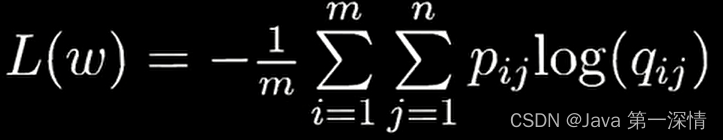
什么是熵
机器学习中的熵源自信息论,它是一种量化信息不确定性的度量,用于描述随机变量或数据集的混乱程度或无序状态。
在监督学习,特别是多类分类问题(如神经网络分类器)中,交叉熵常被用作损失函数,用于衡量模型预测分布与真实标签分布之间的差异。交叉熵是基于模型预测概率分布P(y|x)和实际标签分布Y的联合熵与条件熵之差,用于更新模型权重以减小预测误差。
什么是损失函数
损失函数就是机器学习中用来度量模型预测结果与期望目标之间差距的一种工具,它通过计算“罚分”来告诉模型在哪些地方做错了,以及错得多严重,从而引导模型在训练过程中逐步改进,提高其完成任务的能力。
上面的损失函数就是用来计算评分
经验风险最小化准则(损失函数怎么用)
通俗来讲,它就像是一个指导原则,告诉我们在没有掌握所有可能遇到的数据的情况下,应该如何根据手头已有的有限数据来选择最佳模型。

含义为找到一组w使得损失函数最小化,w即为模型最佳参数
但是实际情况上面这个式子是不够的,通常还要加上一个正则化项
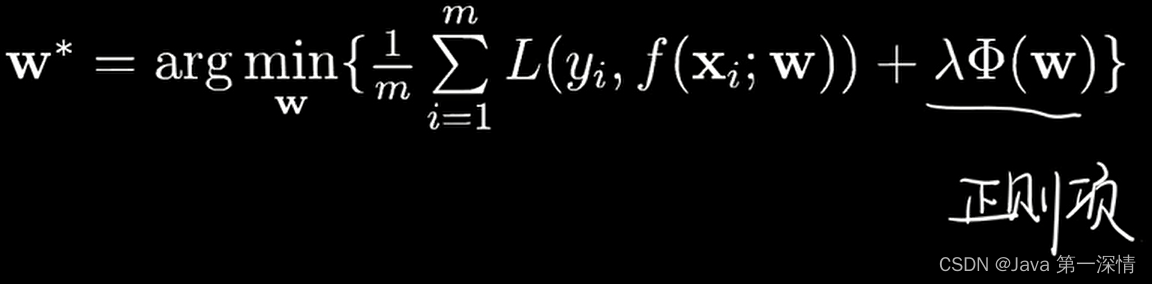
梯度下降
什么是梯度下降
当损失函数中含有对数函数、指数函数等,损失函数叫做超越方程,往往没有解析解,此时需要最优化分析中的搜索逼近来求解。其中最常用的一种算法就是梯度下降
梯度就是函数曲面陡度
偏导数是具体方向的陡度
梯度是所有方向偏导数向量和
决策边界
什么是决策边界
在逻辑回归中,加入sigmoid函数计算概率p,根据概率p的取值来预测y
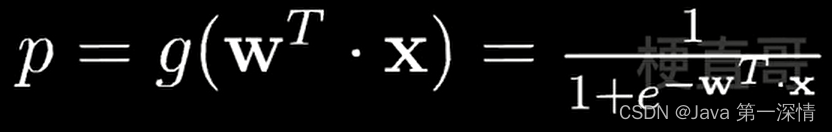
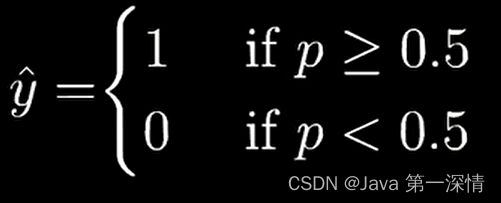
我们知道逻辑回归分类结果是0 1,所以我们要找到一组w使得成为0 1边界,这个边界就叫做决策边界
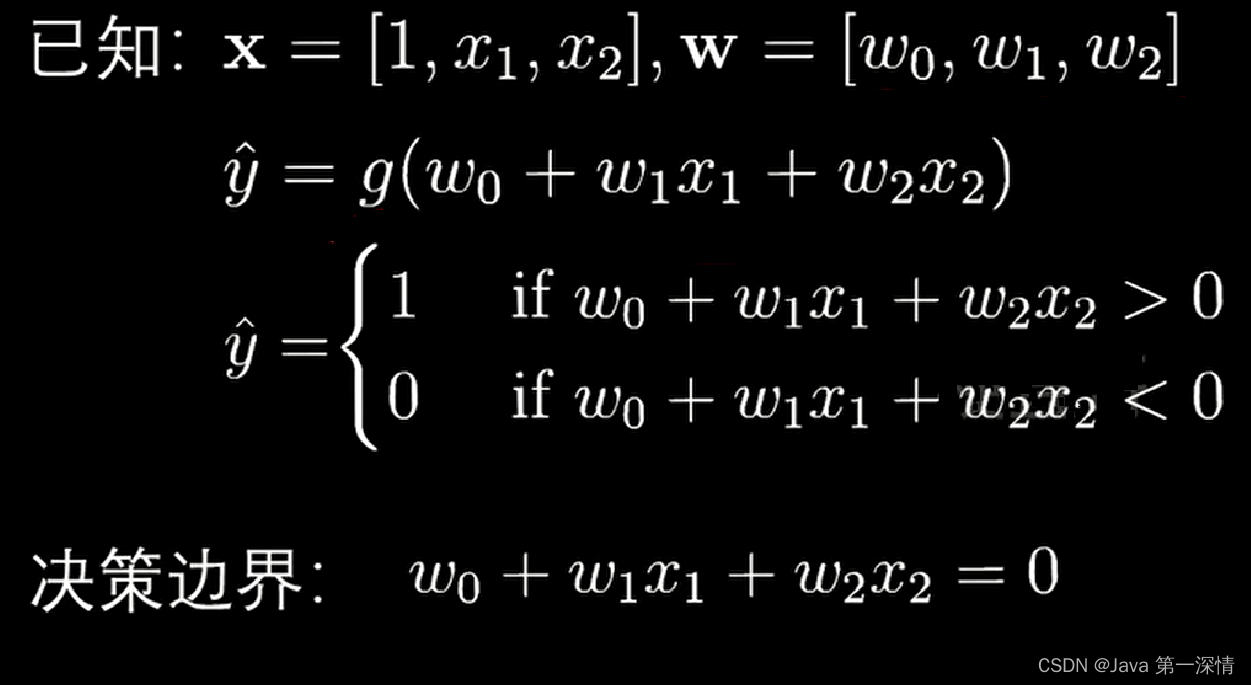
交叉验证
什么是交叉验证
交叉验证的核心思想是通过反复将数据集划分为训练集和测试集,多次训练和测试模型,以减少评估结果的偏差和方差,从而得到对模型性能更为可靠和稳定的估计。

模型误差
偏差:预测结果的准确程度
方差:预测结果的集中程度
噪声:当前任务期望误差下界

正则化
往往避免过拟合,我们会使得多项式次数更低,如何更低,只能使系数为0,因为x是样本数据,正则化项就是用来使得很多参数为0,或接近于0
正则化项通常采用参数范数(norm)的形式,最常见的是L1范数(绝对值之和)和L2范数(平方和的开方)。
混淆矩阵
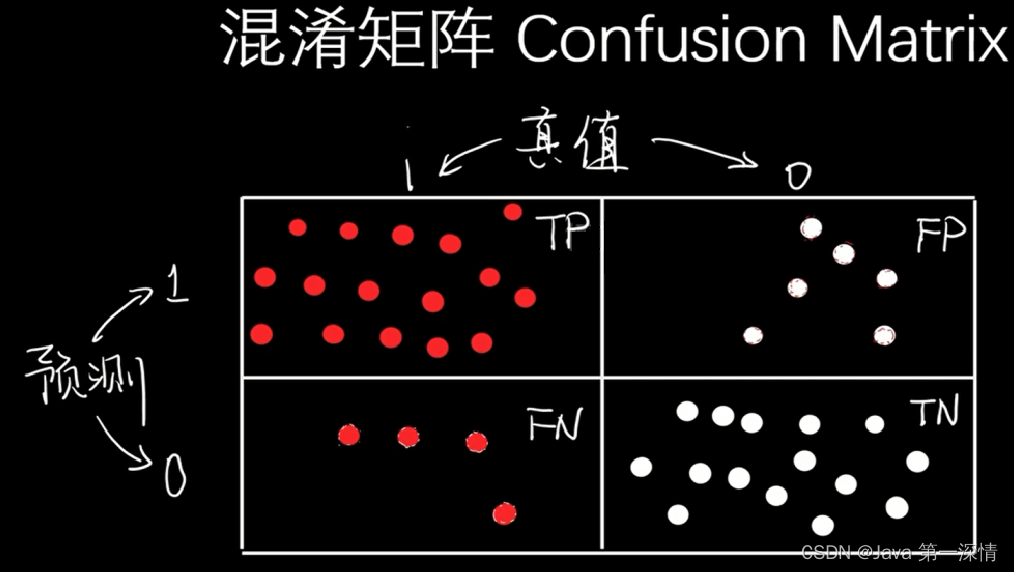
TP:正确预测为红的样本
FP:错误预测为红的样本(冤大头,实际应为白)
FN:漏掉预测的样本(实际上应该是红,但被模型漏掉了,预测成白)
TN:正确预测为白的样本
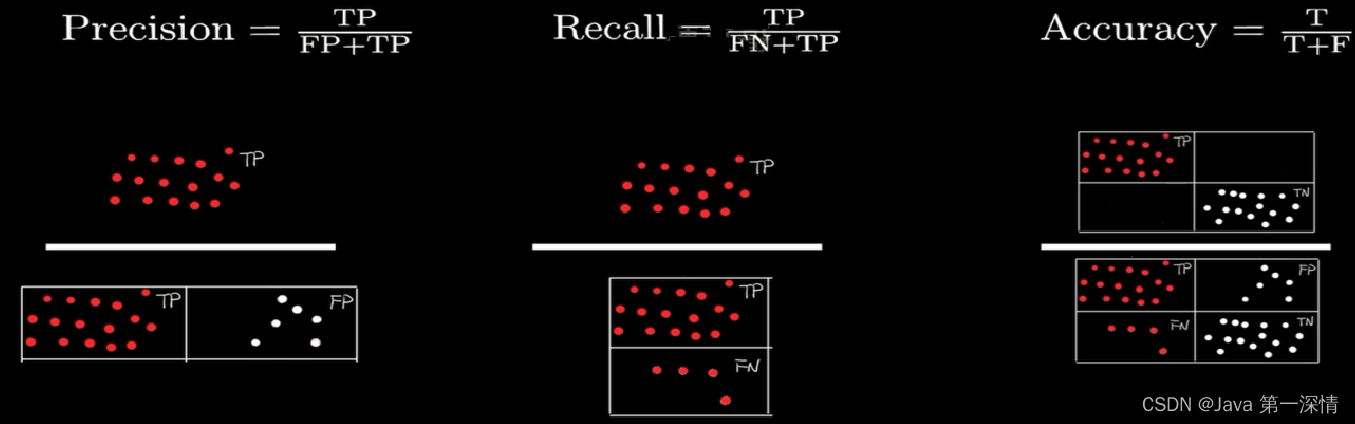
从左到右依次为:精准率(衡量误检程度)、召回率(衡量漏检程度)、精确率(衡量准确程度)

PR曲线即Precision-Recall曲线;
ROC曲线
















 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









