







在我们使用神经网络解决问题的时候,寻找好的超参数其实是一件非常困难的事。
当我们的训练结果不太好的时候,我们很难在众多的超参数中选中需要调节的那一个。可能问题的本身出在隐藏层的神经元个数,或者层数?也有可能是他已经在学习了,只是学习的Epoch不够多?或者是minibatch设置的太小了?可能我们需要换另外一个代价函数?可能我们需要尝试不同的权重初始化方法?也可能我们的网络本身就有问题?等等等等。我们很容易就在超参数的选择中迷失了方向。
如果我们的网络规模很大,或者使用了很多的训练数据,这种情况就更令人失望了,因为一次训练可能就要几个小时甚至几天乃至几周,最终什么都没有获得。
后面,会给出一些用于设定超参数优化的方法,目的是帮助大家发展出一套工作流来确保可以很好地设置超参数。当然,并不会覆盖超参数优化的每个方法。那是太繁重的问题,而且也不会是一个能够完全解决的问题。
宽泛策略
在使用神经网络解决新的问题时,一个挑战就是获得任何一种非寻常的学习,也就是说,达到比随机的情况更好的结果。
假设,我们第一次遇到MNIST分类问题。刚开始,你觉得很轻松,但是当第一个神经网络完全失效的时候,你就会开始沮丧。
这个时候我们可以尝试将问题简化,原问题是分类0-9十个数字,我们就可以在开始时只专注与分类0和1两个数字,不仅仅问题比10个分类的情况简化了,同样也会减少80%的训练数据,这样就给出了5倍的加速,这样可以保证更快的实验,也能给予你关于如何构建好的网络更快的洞察。
另外,你也可以通过提高监控的频率来在试验中获得另一个加速。在这个问题中,我们的训练图像共有5万个,测试图像有1万个,在每个Epoch上我们得到反馈的时间就在10秒左右(当然10秒也并不久),但是如果你希望尝试几十种超参数就很麻烦了。我们可以通过更加频繁地监控验证准确率来获得反馈,比如说在每1000次的图像训练后。而且,与其使用整个1万张图片的验证集来监控性能,我们也可以使用100幅图像来进行验证。真正重要的是网络看到足够多的图像来做真正的学习,获得足够优秀的估计性能。
我们一般是在训练的前期使用宽泛策略比较多一点。这么做是因为我们在开始训练一个网络的时候,很容易会遇到神经网络学习不到任何知识的情况。你可能需花费若干天在调整参数上,但是到最后仍然没有什么进展。所以我们应该在实验中尽可能早的获得快速反馈。
虽然从直觉上看,这样子简化问题和架构仅仅会降低你的效率,但是实际上,这样做能够将进度加快,因为能够更快地找到传达出有意义的信号的网络。一旦你获得这些信号,就可以通过这些信号去微调超参数获得快速的性能提升。
这和人生中很多情况一样----万事开头难。
学习速率
假设我们运行了三个不同学习速率( η = 0.025 , η = 0.25 , η = 2.5 \eta = 0.025,\eta=0.25,\eta=2.5 η=0.025,η=0.25,η=2.5)的MNIST网络。下面展示了一副训练代价的变化情况的图:
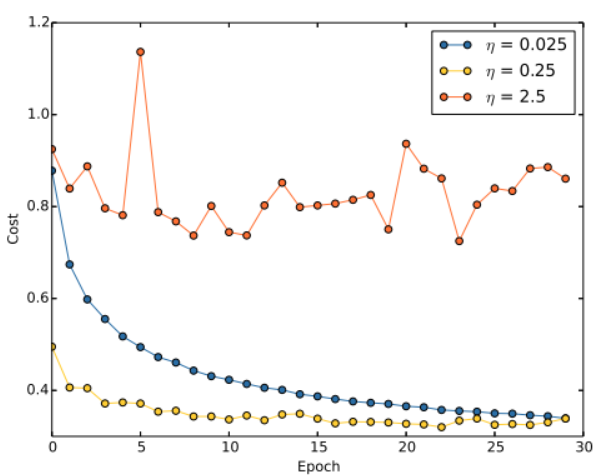
使用 η = 0.025 \eta = 0.025 η=0.025,代价函数一直平滑地下降到最后;使用 η = 0.25 \eta = 0.25 η=0.25,代价刚开始下降,在大约20个Epoch后接近饱和状态,后面就是微小的震动和随机抖动。使用 η = 2.5 \eta=2.5 η=2.5代价从始至终都震荡的非常明显。
为了理解震荡的原因,回想一下随机梯度下降其实是期望我们能够组件地抵达代价函数谷底的。然而,如果 η \eta η太大的话,步长也会变大可能会导致算法在接近最小值的时候一步迈的太大,越过了谷底。
这便是 η = 2.5 \eta=2.5 η=2.5时发生的情况,当我们选择 η = 0.25 \eta=0.25 η=0.25的时候,初始几步将我们带到谷底附近,但是一旦到达了谷底,又很容易跨越过去,当选择 η = 0.025 \eta=0.025 η=0.025时,在前30回合的训练中不会受到这个情况的影响。
但是,如果我们选择了太小的学习速率,也会带来另外一个问题----随机梯度下降算法变慢了。
一种更好的策略是,在开始时使用 η = 0.25 \eta=0.25 η=0.25,随着越来越接近谷底,就换成 η = 0.025 \eta=0.025 η=0.025。
我们要如何设置学习速率呢?其实有很多办法:在开始的时候保持学习速率为一个常量知道验证准确率开始变差,如何按照某个常量下降学习速率,比如每次下降 1 / 1000 1/1000 1/1000,重复这个过程若干次,直至学习速率是初始值的 1 / 1000 1/1000 1/1000(也可以是其他值),那时就终止。
可变学习速率可以提升性能,但是也会产生大量可能的选择。这些选择会让人头疼----你可能会需要花费很多精力才能优化学习规则。对于刚开始实验,建议使用单一的常量作为学习速率的选择,这会给你一个较好的近似。
自动技术
手动选择当然是一种理解网络行为的方法。不过,现实是,很多工作已经使用自动化过程进行。通常的技术就是网格搜索(grid search),可以系统化地对超参数的参数空间进行搜索。网格搜索的成就和限制(易于实现的变体)在James Bergstra 和 Yoshua Bengio 2012年的论文中给出了综述,并且很多更加精细的方法也被大家提出来了。
















 1990
1990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











