







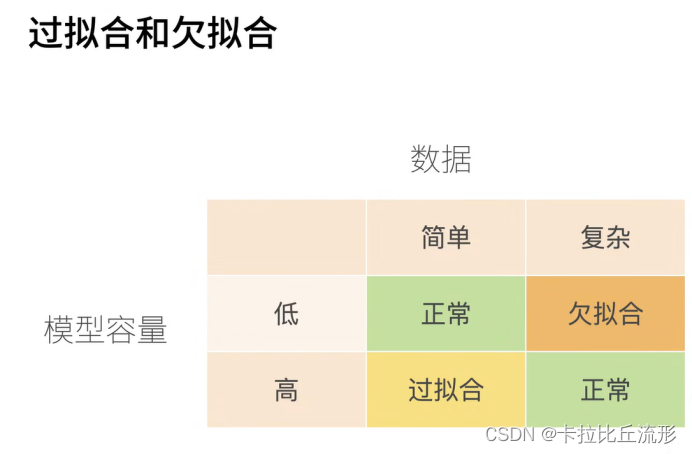
模型选择、欠拟合和过拟合
如何发现可以泛化的模式是机器学习的根本问题。
我们的目标是发现某些模式,这些模式捕捉到了我们训练集潜在总体的规律。如果成功做到了这点,即使是对以前从未遇到过的个体,模型也可以成功地评估风险。
困难在于,当我们训练模型时,我们只能访问数据中的小部分样本。最大的公开图像数据集包含大约一百万张图像。而在大部分时候,我们只能从数千或数万个数据样本中学习。
在大型医院系统中,我们可能会访问数十万份医疗记录。当我们使用有限的样本时,可能会遇到这样的问题:当收集到更多的数据时,会发现之前找到的明显关系并不成立。
将模型在训练数据上拟合的比在潜在分布中更接近的现象称为过拟合(overfitting),用于对抗过拟合的技术称为正则化(regularization)。
如果有足够多的神经元、层数和训练迭代周期,模型最终可以在训练集上达到完美的精度,此时测试集的准确性却下降了。
1. 训练误差和泛化误差
训练误差(training error):模型在训练数据集上计算得到的误差。
泛化误差(generalization error):模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,模型误差的期望。
1.1 统计学习理论
由于泛化是机器学习中的基本问题,许多数学家和理论家毕生致力于研究描述这一现象的形式理论。
在同名定理(eponymous theorem)中,格里文科和坎特利推导出了训练误差收敛到泛化误差的速率。在一系列开创性的论文中,Vapnik和Chervonenkis将这一理论扩展到更一般种类的函数。这项工作为统计学习理论奠定了基础。
在我们目前已探讨、并将在之后继续探讨的监督学习情景中,我们假设训练数据和测试数据都是从相同的分布中独立提取的。
这通常被称为独立同分布假设(i.i.d. assumption),这意味着对数据进行采样的过程没有进行“记忆”。
换句话说,抽取的第2个样本和第3个样本的相关性,并不比抽取的第2个样本和第200万个样本的相关性更强。
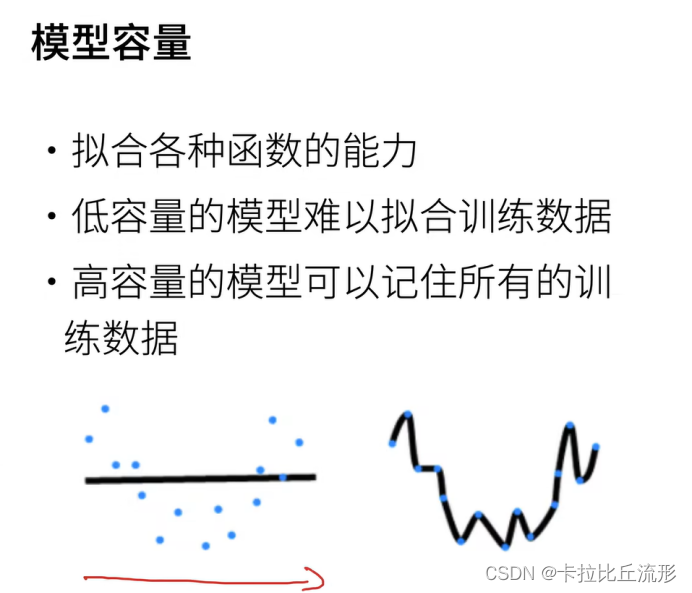
1.2 模型复杂性
当我们有简单的模型和大量的数据时,我们期望泛化误差与训练误差相近。
当我们有更复杂的模型和更少的样本时,我们预计训练误差会下降,但泛化误差会增大。
模型复杂性由什么构成是一个复杂的问题。
一个模型是否能很好地泛化取决于很多因素。
例如,具有更多参数的模型可能被认为更复杂,
参数有更大取值范围的模型可能更为复杂。
通常对于神经网络,我们认为需要更多训练迭代的模型比较复杂,
而需要“早停”(early stopping)的模型(即较少训练迭代周期)就不那么复杂。
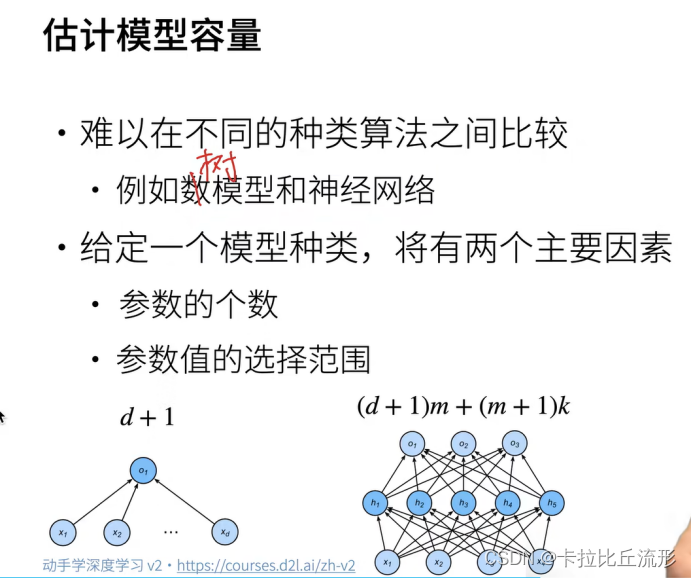
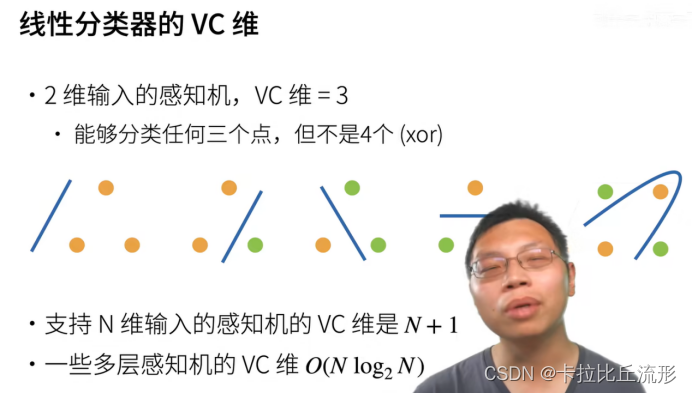
我们很难比较本质上不同大类的模型之间(例如,决策树与神经网络)的复杂性。
就目前而言,一条简单的经验法则相当有用:
统计学家认为,能够轻松解释任意事实的模型是复杂的,而表达能力有限但仍能很好地解释数据的模型可能更有现实用途。
在哲学上,这与波普尔的科学理论的可证伪性标准密切相关:如果一个理论能拟合数据,且有具体的测试可以用来证明它是错误的,那么它就是好的。
这一点很重要,因为所有的统计估计都是事后归纳。
影响模型泛化的因素:
- 可调整参数的数量。当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。
- 参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。
- 训练样本的数量。即使你的模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。
2.模型选择
在机器学习中,我们通常在评估几个候选模型后选择最终的模型。这个过程叫做模型选择。
有时,需要进行比较的模型在本质上是完全不同的(比如,决策树与线性模型)。
又有时,我们需要比较不同的超参数设置下的同一类模型。
例如,训练多层感知机模型时,我们可能希望比较具有不同数量的隐藏层、不同数量的隐藏单元以及不同的的激活函数组合的模型。为了确定候选模型中的最佳模型,我们通常会使用验证集。
2.1 验证集
原则上,在我们确定所有的超参数之前,我们不希望用到测试集。
如果我们在模型选择过程中使用测试数据,可能会有过拟合测试数据的风险,那就麻烦大了。
如果我们过拟合了训练数据,还可以在测试数据上的评估来判断过拟合。
但是如果我们过拟合了测试数据,我们又该怎么知道呢?
因此,我们决不能依靠测试数据进行模型选择。
然而,我们也不能仅仅依靠训练数据来选择模型,因为我们无法估计训练数据的泛化误差。
虽然理想情况下我们只会使用测试数据一次,以评估最好的模型或比较一些模型效果,但现实是测试数据很少在使用一次后被丢弃。
我们很少能有充足的数据来对每一轮实验采用全新测试集。
解决此问题的常见做法是将我们的数据分成三份,除了训练和测试数据集之外,还增加一个验证数据集(validation dataset),也叫验证集(validation set)。
我们实际上是在使用应该被正确地称为训练数据和验证数据的数据集,并没有真正的测试数据集。

2.2 K K K折交叉验证
当训练数据稀缺时,我们甚至可能无法提供足够的数据来构成一个合适的验证集。
这个问题的一个流行的解决方案是采用
K
K
K折交叉验证。
这里,原始训练数据被分成
K
K
K个不重叠的子集。
然后执行
K
K
K次模型训练和验证,每次在
K
−
1
K-1
K−1个子集上进行训练,
并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。
最后,通过对
K
K
K次实验的结果取平均来估计训练和验证误差。


3.欠拟合还是过拟合?
当我们比较训练和验证误差时,我们要注意两种常见的情况。
首先,我们要注意这样的情况:训练误差和验证误差都很严重,
但它们之间仅有一点差距。
如果模型不能降低训练误差,这可能意味着模型过于简单(即表达能力不足),无法捕获试图学习的模式。
此外,由于我们的训练和验证误差之间的泛化误差很小,我们有理由相信可以用一个更复杂的模型降低训练误差。这种现象被称为欠拟合(underfitting)。
另一方面,当我们的训练误差明显低于验证误差时要小心,这表明严重的过拟合(overfitting)。
注意,过拟合并不总是一件坏事。
特别是在深度学习领域,众所周知,最好的预测模型在训练数据上的表现往往比在保留(验证)数据上好得多。
最终,我们通常更关心验证误差,而不是训练误差和验证误差之间的差距。
是否过拟合或欠拟合可能取决于模型复杂性和可用训练数据集的大小。
3.1 模型复杂性
给定由单个特征 x x x和对应实数标签 y y y组成的训练数据,我们试图找到下面的 d d d阶多项式来估计标签 y y y。
y ^ = ∑ i = 0 d x i w i \hat{y}= \sum_{i=0}^d x^i w_i y^=i=0∑dxiwi
这只是一个线性回归问题,我们的特征是 x x x的幂给出的,模型的权重是 w i w_i wi给出的,偏置是 w 0 w_0 w0给出的(因为对于所有的 x x x都有 x 0 = 1 x^0 = 1 x0=1)。由于这只是一个线性回归问题,我们可以使用平方误差作为我们的损失函数。
高阶多项式函数比低阶多项式函数复杂得多。
高阶多项式的参数较多,模型函数的选择范围较广。
因此在固定训练数据集的情况下,高阶多项式函数相对于低阶多项式的训练误差应该始终更低(最坏也是相等)。事实上,当数据样本包含了
x
x
x的不同值时,函数阶数等于数据样本数量的多项式函数可以完美拟合训练集。
3.2 数据集大小
另一个重要因素是数据集的大小。
训练数据集中的样本越少,我们就越有可能(且更严重地)过拟合。
随着训练数据量的增加,泛化误差通常会减小。
此外,一般来说,更多的数据不会有什么坏处。
对于固定的任务和数据分布,模型复杂性和数据集大小之间通常存在关系。
给出更多的数据,我们可能会尝试拟合一个更复杂的模型。能够拟合更复杂的模型可能是有益的。
如果没有足够的数据,简单的模型可能更有用。对于许多任务,深度学习只有在有数千个训练样本时才优于线性模型。
从一定程度上来说,深度学习目前的生机要归功于廉价存储、互联设备以及数字化经济带来的海量数据集。




4. 答疑
-
1.我感觉svm从理论上讲应该对于分类分体效果不错,和神经网络想比,缺点在哪里?
Svm能够调节的参数不多;神经网络本身是一种语言,可以解决较多的问题 -
2.k折交叉验证的目的是确定超参数吗?然后还要用这个超参数再训练一遍全数数据吗?
k折交叉验证确定超参数,再在全数据上进行训练;不再重新训练,选择k折交叉验证中精度最好的超参数;将k折交叉验证的的k个模型在验证集上进行预测,取平均 -
3.老师,所有的验证集上的loss曲线都是这种先下降后上升的吗?为什么网上大部分的图都是一直下降的?
不是
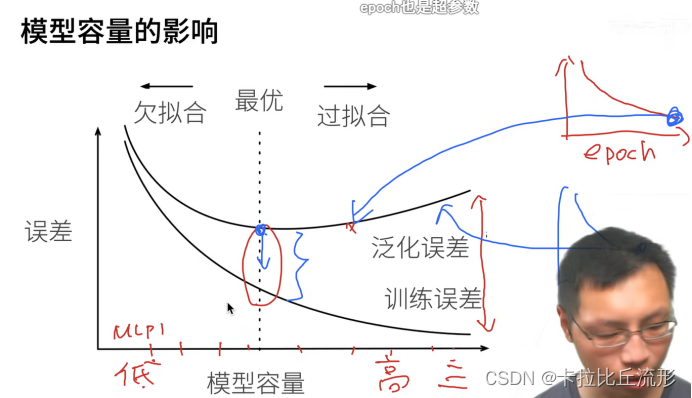
-
4.模型容量一般指的是什么?
模型拟合函数的能力 -
5.如果训练是不平衡的,是否要先考虑测试集是否也是不平衡的,再去决定是否使用一个平衡的验证集?
如果现实就是不平衡的,可以不用管;如果由于采样原因导致数据不平衡,可以对不同类别数据设置权重















 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











