






学习完别人的自己写一遍加深印象
内容来源:【深度学习实战(31)】模型结构之CSPDarknet-CSDN博客
为什么要学这个结构:因为这是yolo的经典结构,学yolo结构看到这个名词不理解所以学习一下
一、整体结构:
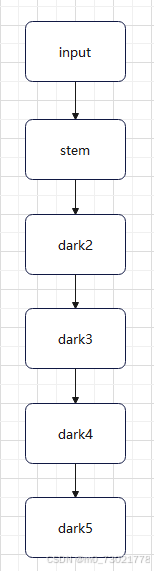
下面分别介绍stem和dark2-5的结构
二、stem结构
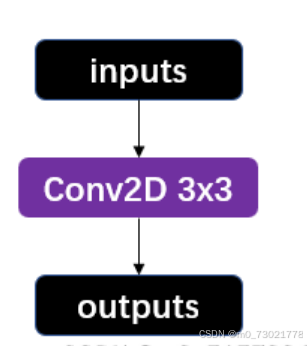
代码:
#-----------------------------------------------#
# 输入图片是640, 640, 3
# 初始的基本通道是64
#-----------------------------------------------#
base_channels = int(wid_mul * 64) # 64
base_depth = max(round(dep_mul * 3), 1) # 3
#-----------------------------------------------#
# 利用卷积结构进行特征提取
# 640, 640, 3 -> 320, 320, 64
#-----------------------------------------------#
self.stem = Conv(3, base_channels, 6, 2)
目的:增加通道数,原本input的图像是640*640*3,现在与一个6*6*64 的卷积核卷积(图里虽然是3*3,但代码里实际参数是(6,2),说明是6*6的卷积核,进行了一次步长为2的下采样,将特征图尺寸减半),并且进行了一次下采样,output变成320*320*64
三、dark2-4的结构
输入的图像,经过一次卷积,再经过一次CSP,你问什么是CSP,别急,后面有解释,这里的卷积也同样是进行了下采样和通道数翻倍。
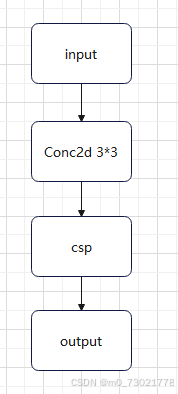
代码:
#-----------------------------------------------#
# 完成卷积之后,160, 160, 128 -> 80, 80, 256
# 完成CSPlayer之后,80, 80, 256 -> 80, 80, 256
#-----------------------------------------------#
self.dark3 = nn.Sequential(
Conv(base_channels * 2, base_channels * 4, 3, 2, act=act),
CSPLayer(base_channels * 4, base_channels * 4, n=base_depth * 3, depthwise=depthwise, act=act),
)
3.1 外层大残差结构CSPLayer(简称CSP):
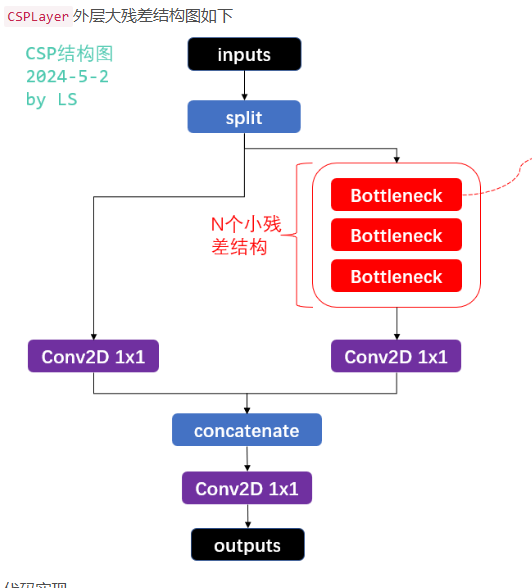
bottleneck后面介绍,split原文理论上其实是把input的通道二等分,比如原来是64*64*32,分成两个64*64*16,分别处理,但实际上,大家的代码是直接把原图分别进行处理,并没有分割 。如下图所示:
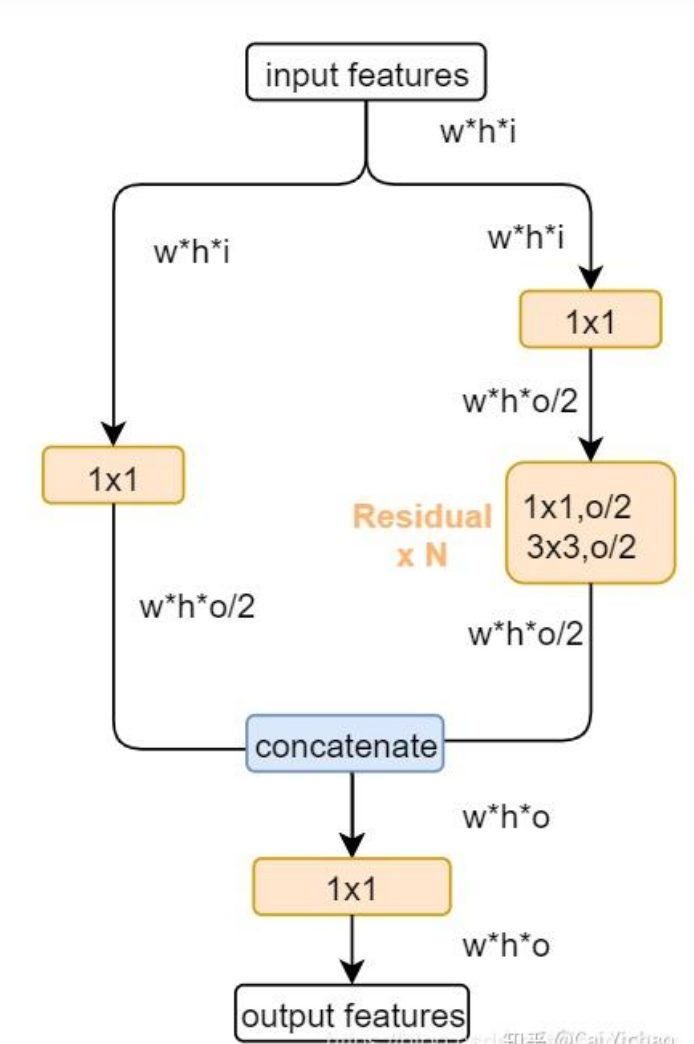
实际的结构在输入后没有按照通道划分成两个部分,而是直接用两路的1x1卷积将输入特征进行变换。 可以理解的是,将全部的输入特征利用两路1x1进行transition,比直接划分通道能够进一步提高特征的重用性,并且在输入到resiudal block之前也确实通道减半,减少了计算量。
3.2 里面小残差结构Bottleneck
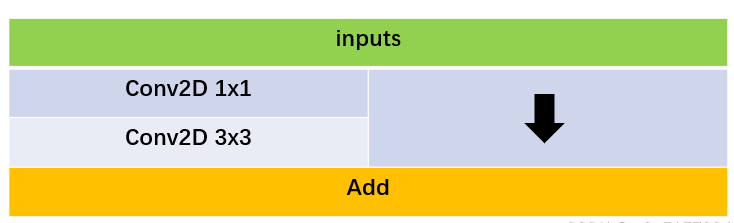
其中Conv2D可以根据需要设置为普通卷积BaseConv或者是深度可分离卷积DWConv,激活函数可以选择relu或者leaky_relu。
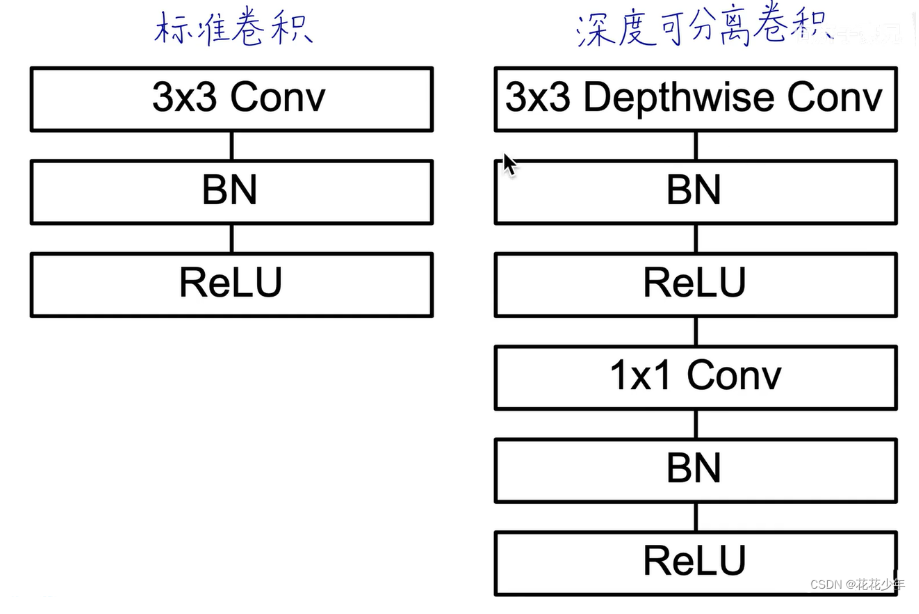
那,什么是深度可分离卷积? 逐点卷积就是W/H维度不变,改变channel。逐深度卷积就是深度(channel)维度不变,改变H/W。深度可分离卷积(Depthwise separable convolution, DSC)由逐深度卷积和逐点卷积组成。深度卷积用于提取空间特征,逐点卷积用于提取通道特征
四、dark5的结构
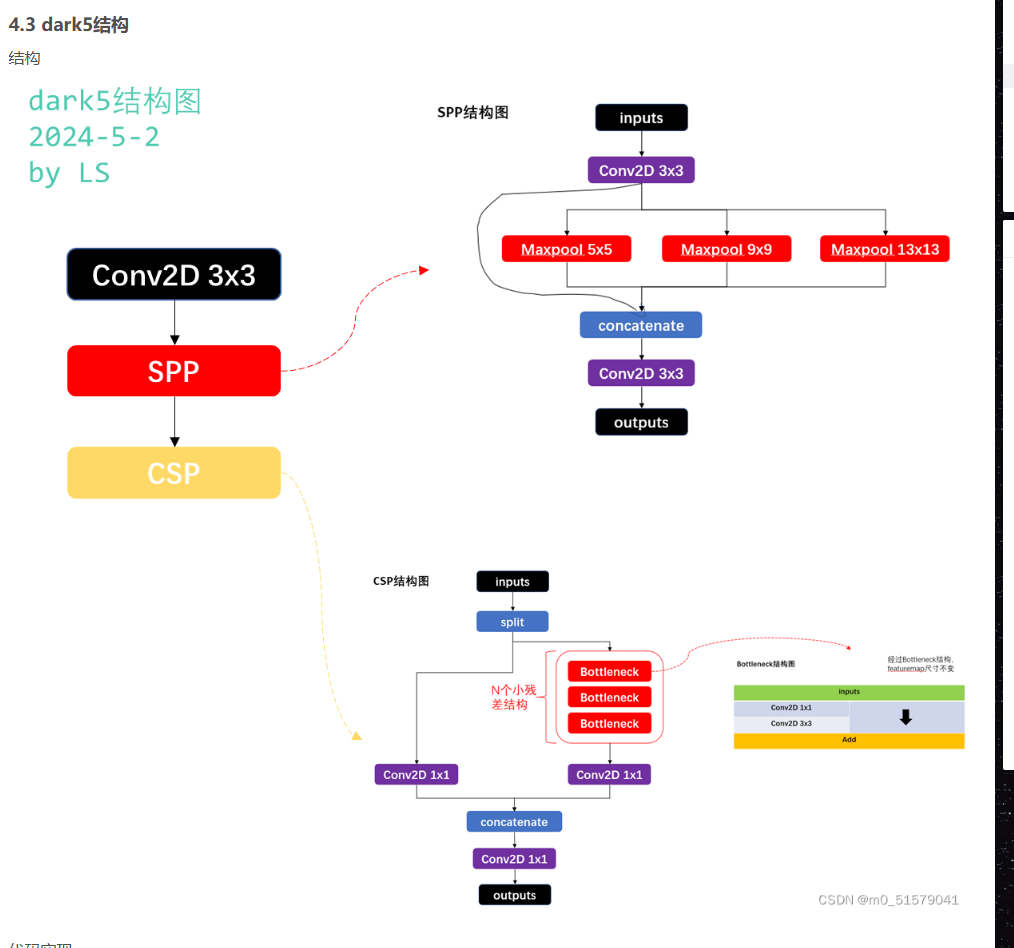
spp结构比较清晰,三个不同的池化结果和原图融合,csp上面解释过了,所以过。

















 7695
7695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









